 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWebGraphEval: Multi-Turn Trajectory Evaluation for Web Agents using Graph Representation
Oct 22, 2025Current evaluation of web agents largely reduces to binary success metrics or conformity to a single reference trajectory, ignoring the structural diversity present in benchmark datasets. We present WebGraphEval, a framework that abstracts trajectories from multiple agents into a unified, weighted action graph. This representation is directly compatible with benchmarks such as WebArena, leveraging leaderboard runs and newly collected trajectories without modifying environments. The framework canonically encodes actions, merges recurring behaviors, and applies structural analyses including reward propagation and success-weighted edge statistics. Evaluations across thousands of trajectories from six web agents show that the graph abstraction captures cross-model regularities, highlights redundancy and inefficiency, and identifies critical decision points overlooked by outcome-based metrics. By framing web interaction as graph-structured data, WebGraphEval establishes a general methodology for multi-path, cross-agent, and efficiency-aware evaluation of web agents.
LiteWebAgent: The Open-Source Suite for VLM-Based Web-Agent Applications
Mar 04, 2025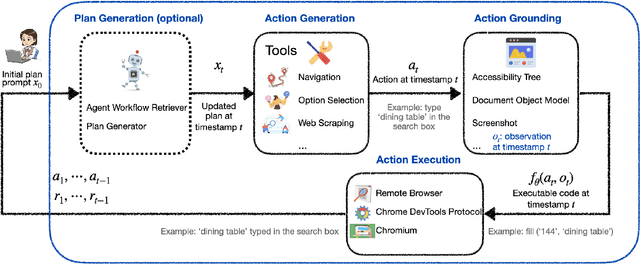



We introduce LiteWebAgent, an open-source suite for VLM-based web agent applications. Our framework addresses a critical gap in the web agent ecosystem with a production-ready solution that combines minimal serverless backend configuration, intuitive user and browser interfaces, and extensible research capabilities in agent planning, memory, and tree search. For the core LiteWebAgent agent framework, we implemented a simple yet effective baseline using recursive function calling, providing with decoupled action generation and action grounding. In addition, we integrate advanced research components such as agent planning, agent workflow memory, and tree search in a modular and extensible manner. We then integrate the LiteWebAgent agent framework with frontend and backend as deployed systems in two formats: (1) a production Vercel-based web application, which provides users with an agent-controlled remote browser, (2) a Chrome extension leveraging LiteWebAgent's API to control an existing Chrome browser via CDP (Chrome DevTools Protocol). The LiteWebAgent framework is available at https://github.com/PathOnAI/LiteWebAgent, with deployed frontend at https://lite-web-agent.vercel.app/.
Survey for Landing Generative AI in Social and E-commerce Recsys -- the Industry Perspectives
Jun 10, 2024



Recently, generative AI (GAI), with their emerging capabilities, have presented unique opportunities for augmenting and revolutionizing industrial recommender systems (Recsys). Despite growing research efforts at the intersection of these fields, the integration of GAI into industrial Recsys remains in its infancy, largely due to the intricate nature of modern industrial Recsys infrastructure, operations, and product sophistication. Drawing upon our experiences in successfully integrating GAI into several major social and e-commerce platforms, this survey aims to comprehensively examine the underlying system and AI foundations, solution frameworks, connections to key research advancements, as well as summarize the practical insights and challenges encountered in the endeavor to integrate GAI into industrial Recsys. As pioneering work in this domain, we hope outline the representative developments of relevant fields, shed lights on practical GAI adoptions in the industry, and motivate future research.
Short Text Pre-training with Extended Token Classification for E-commerce Query Understanding
Oct 08, 2022
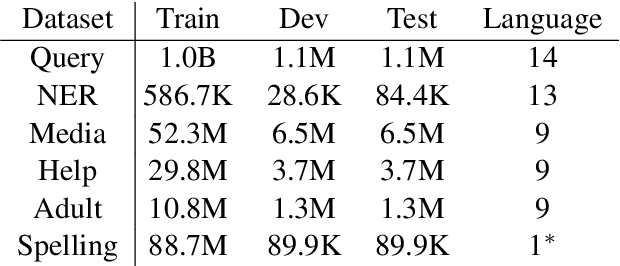
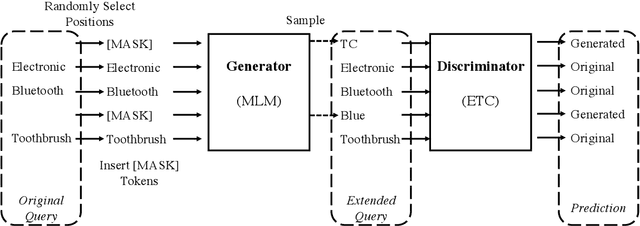
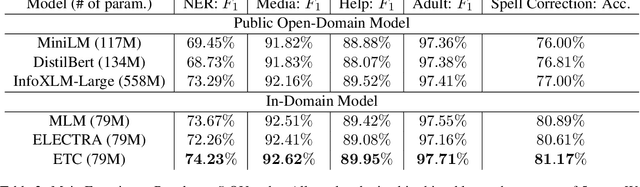
E-commerce query understanding is the process of inferring the shopping intent of customers by extracting semantic meaning from their search queries. The recent progress of pre-trained masked language models (MLM) in natural language processing is extremely attractive for developing effective query understanding models. Specifically, MLM learns contextual text embedding via recovering the masked tokens in the sentences. Such a pre-training process relies on the sufficient contextual information. It is, however, less effective for search queries, which are usually short text. When applying masking to short search queries, most contextual information is lost and the intent of the search queries may be changed. To mitigate the above issues for MLM pre-training on search queries, we propose a novel pre-training task specifically designed for short text, called Extended Token Classification (ETC). Instead of masking the input text, our approach extends the input by inserting tokens via a generator network, and trains a discriminator to identify which tokens are inserted in the extended input. We conduct experiments in an E-commerce store to demonstrate the effectiveness of ETC.
Condensing Graphs via One-Step Gradient Matching
Jun 15, 2022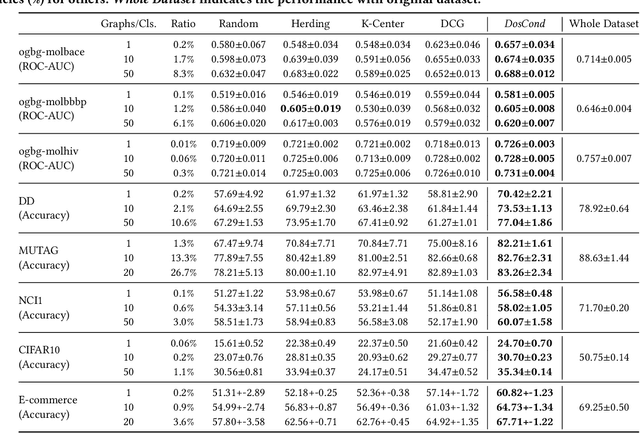
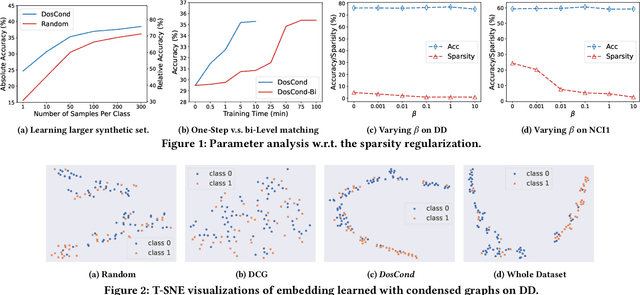
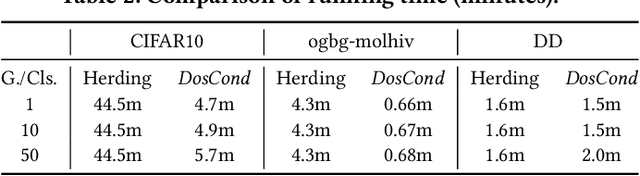
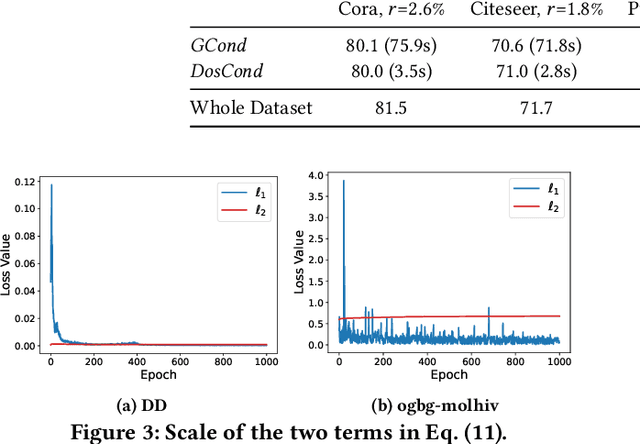
As training deep learning models on large dataset takes a lot of time and resources, it is desired to construct a small synthetic dataset with which we can train deep learning models sufficiently. There are recent works that have explored solutions on condensing image datasets through complex bi-level optimization. For instance, dataset condensation (DC) matches network gradients w.r.t. large-real data and small-synthetic data, where the network weights are optimized for multiple steps at each outer iteration. However, existing approaches have their inherent limitations: (1) they are not directly applicable to graphs where the data is discrete; and (2) the condensation process is computationally expensive due to the involved nested optimization. To bridge the gap, we investigate efficient dataset condensation tailored for graph datasets where we model the discrete graph structure as a probabilistic model. We further propose a one-step gradient matching scheme, which performs gradient matching for only one single step without training the network weights. Our theoretical analysis shows this strategy can generate synthetic graphs that lead to lower classification loss on real graphs. Extensive experiments on various graph datasets demonstrate the effectiveness and efficiency of the proposed method. In particular, we are able to reduce the dataset size by 90% while approximating up to 98% of the original performance and our method is significantly faster than multi-step gradient matching (e.g. 15x in CIFAR10 for synthesizing 500 graphs).
SeqZero: Few-shot Compositional Semantic Parsing with Sequential Prompts and Zero-shot Models
May 15, 2022
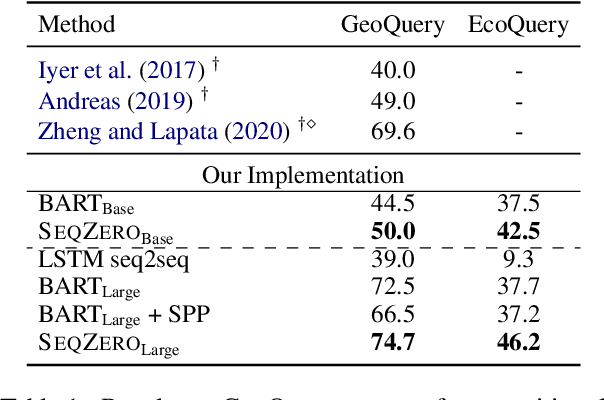

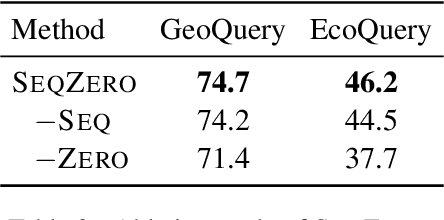
Recent research showed promising results on combining pretrained language models (LMs) with canonical utterance for few-shot semantic parsing. The canonical utterance is often lengthy and complex due to the compositional structure of formal languages. Learning to generate such canonical utterance requires significant amount of data to reach high performance. Fine-tuning with only few-shot samples, the LMs can easily forget pretrained knowledge, overfit spurious biases, and suffer from compositionally out-of-distribution generalization errors. To tackle these issues, we propose a novel few-shot semantic parsing method -- SeqZero. SeqZero decomposes the problem into a sequence of sub-problems, which correspond to the sub-clauses of the formal language. Based on the decomposition, the LMs only need to generate short answers using prompts for predicting sub-clauses. Thus, SeqZero avoids generating a long canonical utterance at once. Moreover, SeqZero employs not only a few-shot model but also a zero-shot model to alleviate the overfitting. In particular, SeqZero brings out the merits from both models via ensemble equipped with our proposed constrained rescaling. SeqZero achieves SOTA performance of BART-based models on GeoQuery and EcommerceQuery, which are two few-shot datasets with compositional data split.
RETE: Retrieval-Enhanced Temporal Event Forecasting on Unified Query Product Evolutionary Graph
Feb 12, 2022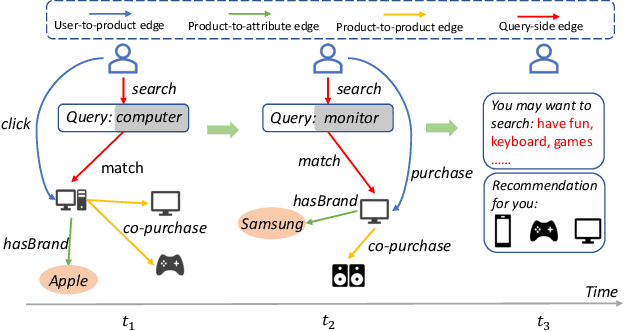
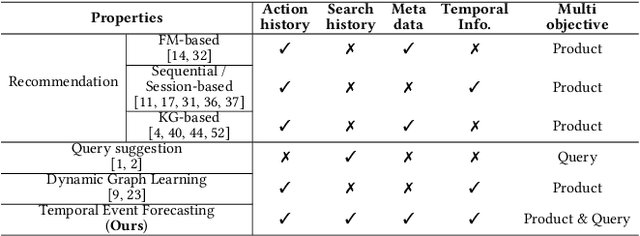
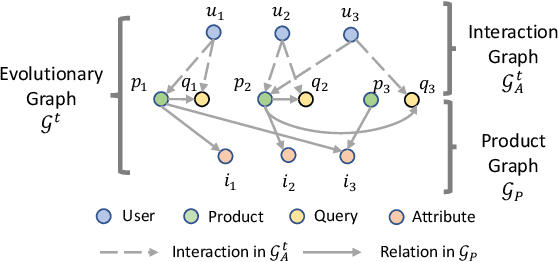
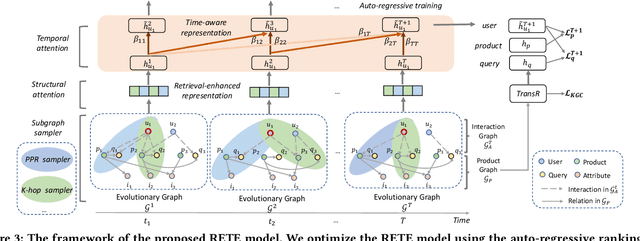
With the increasing demands on e-commerce platforms, numerous user action history is emerging. Those enriched action records are vital to understand users' interests and intents. Recently, prior works for user behavior prediction mainly focus on the interactions with product-side information. However, the interactions with search queries, which usually act as a bridge between users and products, are still under investigated. In this paper, we explore a new problem named temporal event forecasting, a generalized user behavior prediction task in a unified query product evolutionary graph, to embrace both query and product recommendation in a temporal manner. To fulfill this setting, there involves two challenges: (1) the action data for most users is scarce; (2) user preferences are dynamically evolving and shifting over time. To tackle those issues, we propose a novel Retrieval-Enhanced Temporal Event (RETE) forecasting framework. Unlike existing methods that enhance user representations via roughly absorbing information from connected entities in the whole graph, RETE efficiently and dynamically retrieves relevant entities centrally on each user as high-quality subgraphs, preventing the noise propagation from the densely evolutionary graph structures that incorporate abundant search queries. And meanwhile, RETE autoregressively accumulates retrieval-enhanced user representations from each time step, to capture evolutionary patterns for joint query and product prediction. Empirically, extensive experiments on both the public benchmark and four real-world industrial datasets demonstrate the effectiveness of the proposed RETE method.
QUEACO: Borrowing Treasures from Weakly-labeled Behavior Data for Query Attribute Value Extraction
Sep 05, 2021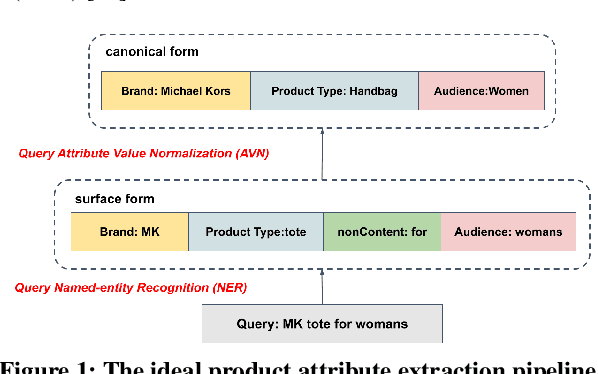

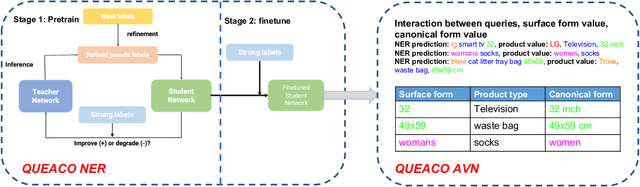
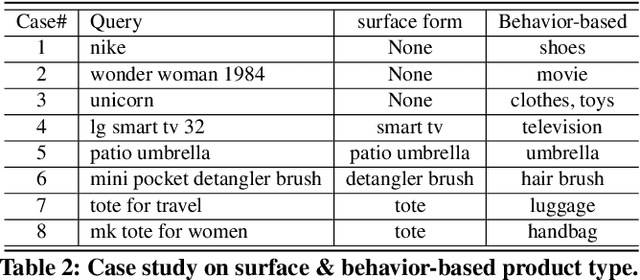
We study the problem of query attribute value extraction, which aims to identify named entities from user queries as diverse surface form attribute values and afterward transform them into formally canonical forms. Such a problem consists of two phases: {named entity recognition (NER)} and {attribute value normalization (AVN)}. However, existing works only focus on the NER phase but neglect equally important AVN. To bridge this gap, this paper proposes a unified query attribute value extraction system in e-commerce search named QUEACO, which involves both two phases. Moreover, by leveraging large-scale weakly-labeled behavior data, we further improve the extraction performance with less supervision cost. Specifically, for the NER phase, QUEACO adopts a novel teacher-student network, where a teacher network that is trained on the strongly-labeled data generates pseudo-labels to refine the weakly-labeled data for training a student network. Meanwhile, the teacher network can be dynamically adapted by the feedback of the student's performance on strongly-labeled data to maximally denoise the noisy supervisions from the weak labels. For the AVN phase, we also leverage the weakly-labeled query-to-attribute behavior data to normalize surface form attribute values from queries into canonical forms from products. Extensive experiments on a real-world large-scale E-commerce dataset demonstrate the effectiveness of QUEACO.
* The 30th ACM International Conference on Information and Knowledge Management (CIKM 2021, Applied Research Track)
Named Entity Recognition with Small Strongly Labeled and Large Weakly Labeled Data
Jun 16, 2021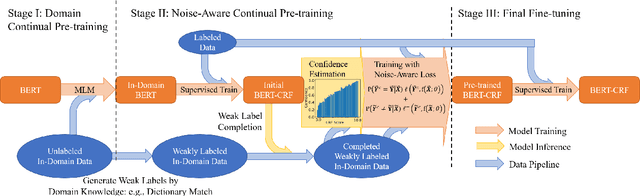
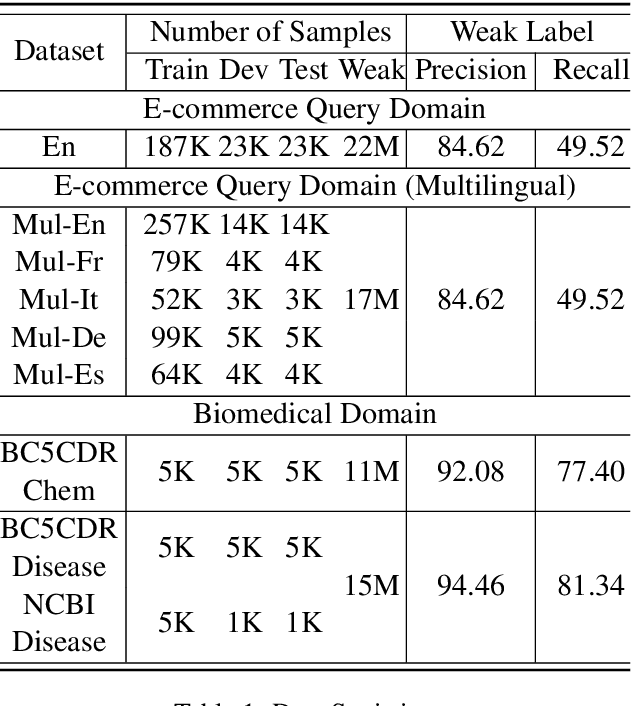
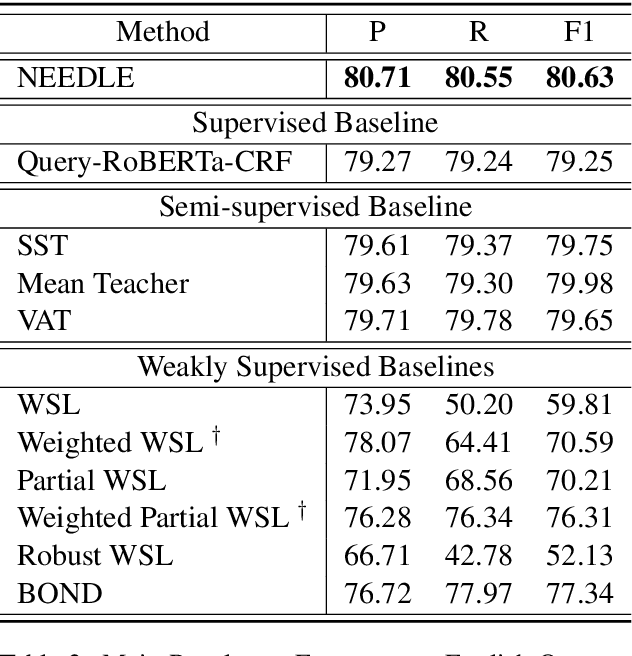
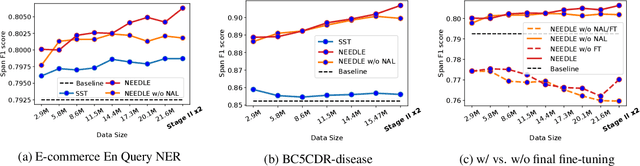
Weak supervision has shown promising results in many natural language processing tasks, such as Named Entity Recognition (NER). Existing work mainly focuses on learning deep NER models only with weak supervision, i.e., without any human annotation, and shows that by merely using weakly labeled data, one can achieve good performance, though still underperforms fully supervised NER with manually/strongly labeled data. In this paper, we consider a more practical scenario, where we have both a small amount of strongly labeled data and a large amount of weakly labeled data. Unfortunately, we observe that weakly labeled data does not necessarily improve, or even deteriorate the model performance (due to the extensive noise in the weak labels) when we train deep NER models over a simple or weighted combination of the strongly labeled and weakly labeled data. To address this issue, we propose a new multi-stage computational framework -- NEEDLE with three essential ingredients: (1) weak label completion, (2) noise-aware loss function, and (3) final fine-tuning over the strongly labeled data. Through experiments on E-commerce query NER and Biomedical NER, we demonstrate that NEEDLE can effectively suppress the noise of the weak labels and outperforms existing methods. In particular, we achieve new SOTA F1-scores on 3 Biomedical NER datasets: BC5CDR-chem 93.74, BC5CDR-disease 90.69, NCBI-disease 92.28.
Improving Pretrained Models for Zero-shot Multi-label Text Classification through Reinforced Label Hierarchy Reasoning
Apr 04, 2021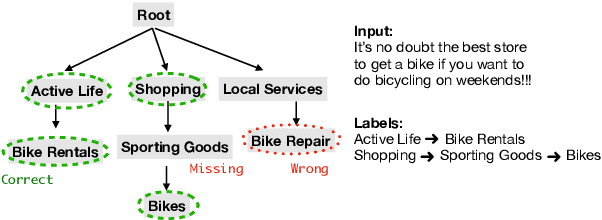
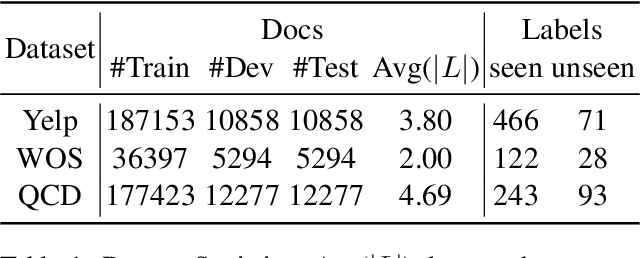
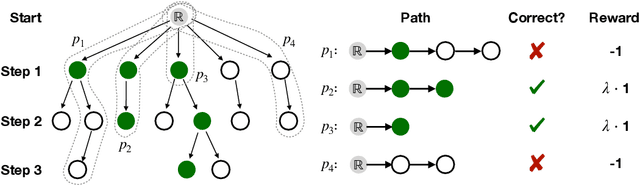
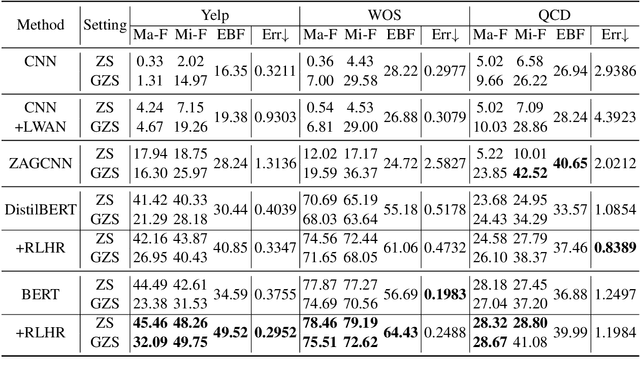
Exploiting label hierarchies has become a promising approach to tackling the zero-shot multi-label text classification (ZS-MTC) problem. Conventional methods aim to learn a matching model between text and labels, using a graph encoder to incorporate label hierarchies to obtain effective label representations \cite{rios2018few}. More recently, pretrained models like BERT \cite{devlin2018bert} have been used to convert classification tasks into a textual entailment task \cite{yin-etal-2019-benchmarking}. This approach is naturally suitable for the ZS-MTC task. However, pretrained models are underexplored in the existing work because they do not generate individual vector representations for text or labels, making it unintuitive to combine them with conventional graph encoding methods. In this paper, we explore to improve pretrained models with label hierarchies on the ZS-MTC task. We propose a Reinforced Label Hierarchy Reasoning (RLHR) approach to encourage interdependence among labels in the hierarchies during training. Meanwhile, to overcome the weakness of flat predictions, we design a rollback algorithm that can remove logical errors from predictions during inference. Experimental results on three real-life datasets show that our approach achieves better performance and outperforms previous non-pretrained methods on the ZS-MTC task.