 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA General Framework to Enhance Fine-tuning-based LLM Unlearning
Feb 25, 2025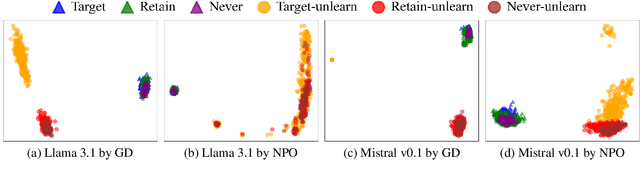
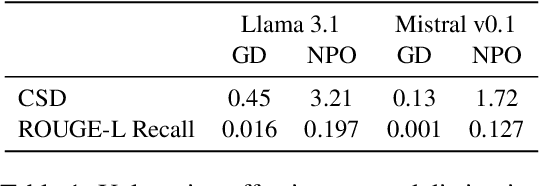
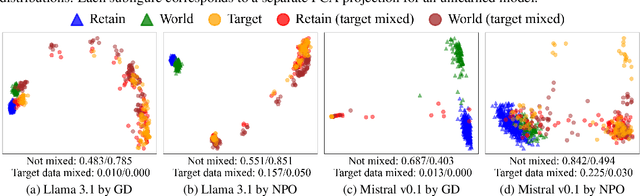
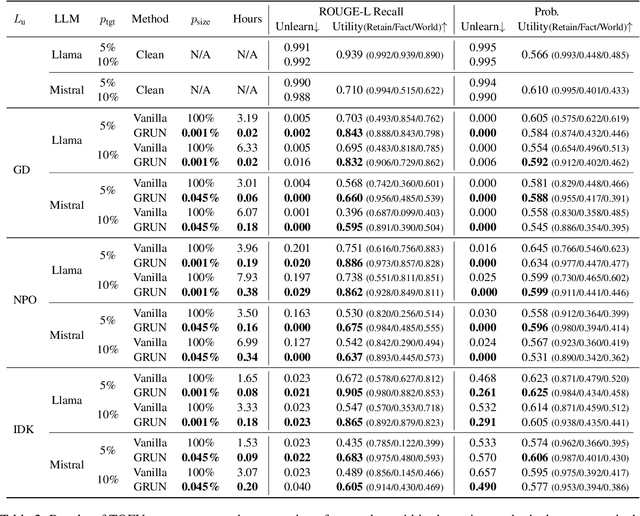
Unlearning has been proposed to remove copyrighted and privacy-sensitive data from Large Language Models (LLMs). Existing approaches primarily rely on fine-tuning-based methods, which can be categorized into gradient ascent-based (GA-based) and suppression-based methods. However, they often degrade model utility (the ability to respond to normal prompts). In this work, we aim to develop a general framework that enhances the utility of fine-tuning-based unlearning methods. To achieve this goal, we first investigate the common property between GA-based and suppression-based methods. We unveil that GA-based methods unlearn by distinguishing the target data (i.e., the data to be removed) and suppressing related generations, which is essentially the same strategy employed by suppression-based methods. Inspired by this finding, we introduce Gated Representation UNlearning (GRUN) which has two components: a soft gate function for distinguishing target data and a suppression module using Representation Fine-tuning (ReFT) to adjust representations rather than model parameters. Experiments show that GRUN significantly improves the unlearning and utility. Meanwhile, it is general for fine-tuning-based methods, efficient and promising for sequential unlearning.
Exploring Query Understanding for Amazon Product Search
Aug 05, 2024



Online shopping platforms, such as Amazon, offer services to billions of people worldwide. Unlike web search or other search engines, product search engines have their unique characteristics, primarily featuring short queries which are mostly a combination of product attributes and structured product search space. The uniqueness of product search underscores the crucial importance of the query understanding component. However, there are limited studies focusing on exploring this impact within real-world product search engines. In this work, we aim to bridge this gap by conducting a comprehensive study and sharing our year-long journey investigating how the query understanding service impacts Amazon Product Search. Firstly, we explore how query understanding-based ranking features influence the ranking process. Next, we delve into how the query understanding system contributes to understanding the performance of a ranking model. Building on the insights gained from our study on the evaluation of the query understanding-based ranking model, we propose a query understanding-based multi-task learning framework for ranking. We present our studies and investigations using the real-world system on Amazon Search.
Hierarchical Query Classification in E-commerce Search
Mar 09, 2024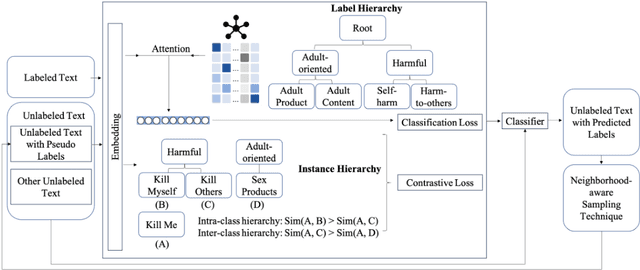

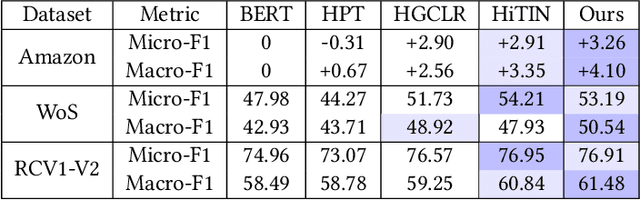
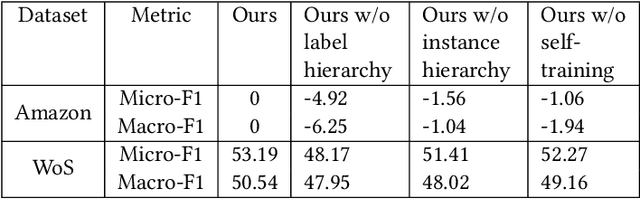
E-commerce platforms typically store and structure product information and search data in a hierarchy. Efficiently categorizing user search queries into a similar hierarchical structure is paramount in enhancing user experience on e-commerce platforms as well as news curation and academic research. The significance of this task is amplified when dealing with sensitive query categorization or critical information dissemination, where inaccuracies can lead to considerable negative impacts. The inherent complexity of hierarchical query classification is compounded by two primary challenges: (1) the pronounced class imbalance that skews towards dominant categories, and (2) the inherent brevity and ambiguity of search queries that hinder accurate classification. To address these challenges, we introduce a novel framework that leverages hierarchical information through (i) enhanced representation learning that utilizes the contrastive loss to discern fine-grained instance relationships within the hierarchy, called ''instance hierarchy'', and (ii) a nuanced hierarchical classification loss that attends to the intrinsic label taxonomy, named ''label hierarchy''. Additionally, based on our observation that certain unlabeled queries share typographical similarities with labeled queries, we propose a neighborhood-aware sampling technique to intelligently select these unlabeled queries to boost the classification performance. Extensive experiments demonstrate that our proposed method is better than state-of-the-art (SOTA) on the proprietary Amazon dataset, and comparable to SOTA on the public datasets of Web of Science and RCV1-V2. These results underscore the efficacy of our proposed solution, and pave the path toward the next generation of hierarchy-aware query classification systems.
Amazon-M2: A Multilingual Multi-locale Shopping Session Dataset for Recommendation and Text Generation
Jul 19, 2023
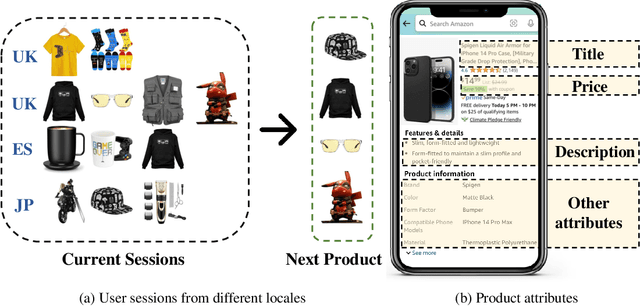
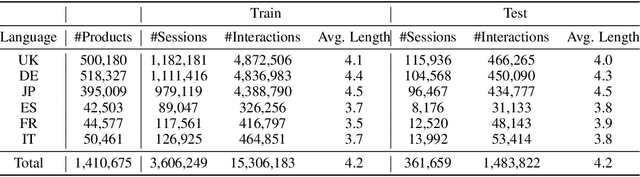
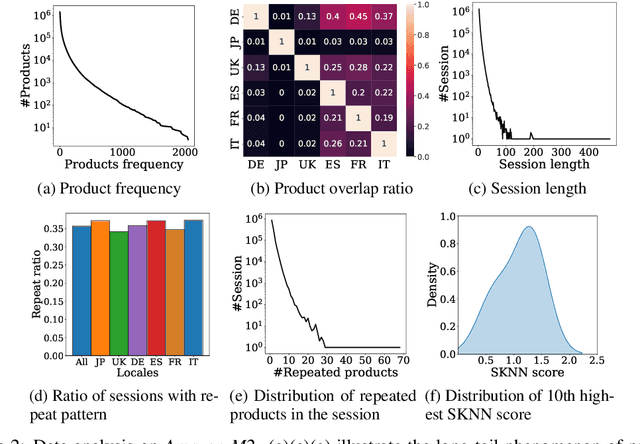
Modeling customer shopping intentions is a crucial task for e-commerce, as it directly impacts user experience and engagement. Thus, accurately understanding customer preferences is essential for providing personalized recommendations. Session-based recommendation, which utilizes customer session data to predict their next interaction, has become increasingly popular. However, existing session datasets have limitations in terms of item attributes, user diversity, and dataset scale. As a result, they cannot comprehensively capture the spectrum of user behaviors and preferences. To bridge this gap, we present the Amazon Multilingual Multi-locale Shopping Session Dataset, namely Amazon-M2. It is the first multilingual dataset consisting of millions of user sessions from six different locales, where the major languages of products are English, German, Japanese, French, Italian, and Spanish. Remarkably, the dataset can help us enhance personalization and understanding of user preferences, which can benefit various existing tasks as well as enable new tasks. To test the potential of the dataset, we introduce three tasks in this work: (1) next-product recommendation, (2) next-product recommendation with domain shifts, and (3) next-product title generation. With the above tasks, we benchmark a range of algorithms on our proposed dataset, drawing new insights for further research and practice. In addition, based on the proposed dataset and tasks, we hosted a competition in the KDD CUP 2023 and have attracted thousands of users and submissions. The winning solutions and the associated workshop can be accessed at our website https://kddcup23.github.io/.
Short Text Pre-training with Extended Token Classification for E-commerce Query Understanding
Oct 08, 2022
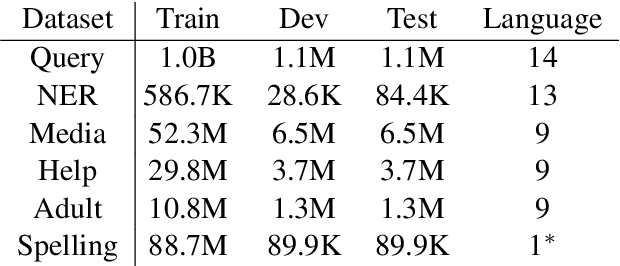
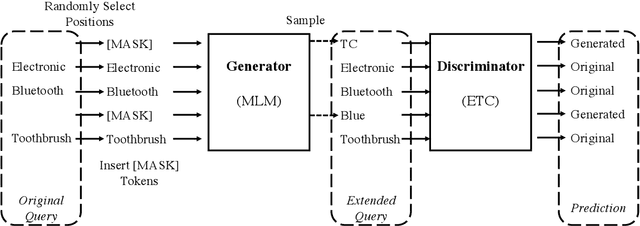
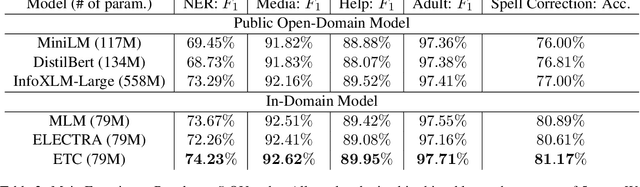
E-commerce query understanding is the process of inferring the shopping intent of customers by extracting semantic meaning from their search queries. The recent progress of pre-trained masked language models (MLM) in natural language processing is extremely attractive for developing effective query understanding models. Specifically, MLM learns contextual text embedding via recovering the masked tokens in the sentences. Such a pre-training process relies on the sufficient contextual information. It is, however, less effective for search queries, which are usually short text. When applying masking to short search queries, most contextual information is lost and the intent of the search queries may be changed. To mitigate the above issues for MLM pre-training on search queries, we propose a novel pre-training task specifically designed for short text, called Extended Token Classification (ETC). Instead of masking the input text, our approach extends the input by inserting tokens via a generator network, and trains a discriminator to identify which tokens are inserted in the extended input. We conduct experiments in an E-commerce store to demonstrate the effectiveness of ETC.
Shareable Representations for Search Query Understanding
Dec 20, 2019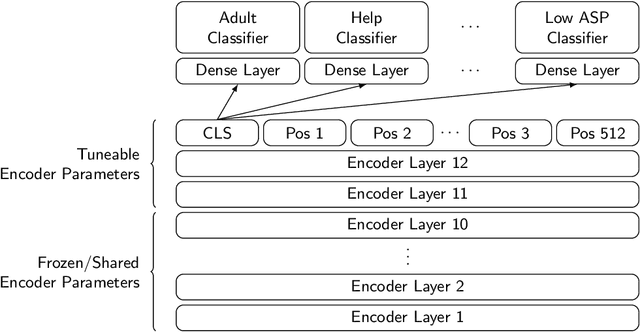
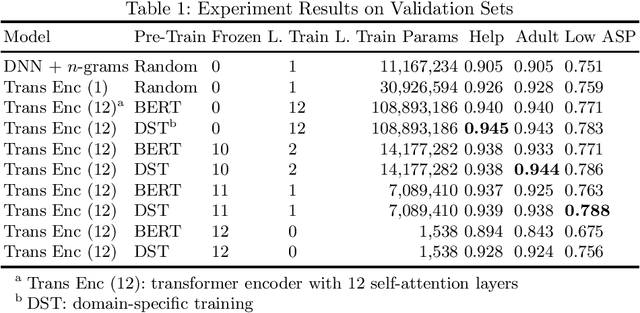

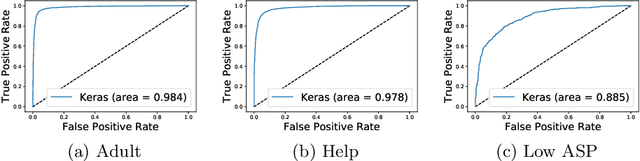
Understanding search queries is critical for shopping search engines to deliver a satisfying customer experience. Popular shopping search engines receive billions of unique queries yearly, each of which can depict any of hundreds of user preferences or intents. In order to get the right results to customers it must be known queries like "inexpensive prom dresses" are intended to not only surface results of a certain product type but also products with a low price. Referred to as query intents, examples also include preferences for author, brand, age group, or simply a need for customer service. Recent works such as BERT have demonstrated the success of a large transformer encoder architecture with language model pre-training on a variety of NLP tasks. We adapt such an architecture to learn intents for search queries and describe methods to account for the noisiness and sparseness of search query data. We also describe cost effective ways of hosting transformer encoder models in context with low latency requirements. With the right domain-specific training we can build a shareable deep learning model whose internal representation can be reused for a variety of query understanding tasks including query intent identification. Model sharing allows for fewer large models needed to be served at inference time and provides a platform to quickly build and roll out new search query classifiers.