 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use
Jan 31, 2026As Large Language Models (LLMs) are increasingly applied in high-stakes domains, their ability to reason strategically under uncertainty becomes critical. Poker provides a rigorous testbed, requiring not only strong actions but also principled, game-theoretic reasoning. In this paper, we conduct a systematic study of LLMs in multiple realistic poker tasks, evaluating both gameplay outcomes and reasoning traces. Our analysis reveals LLMs fail to compete against traditional algorithms and identifies three recurring flaws: reliance on heuristics, factual misunderstandings, and a "knowing-doing" gap where actions diverge from reasoning. An initial attempt with behavior cloning and step-level reinforcement learning improves reasoning style but remains insufficient for accurate game-theoretic play. Motivated by these limitations, we propose ToolPoker, a tool-integrated reasoning framework that combines external solvers for GTO-consistent actions with more precise professional-style explanations. Experiments demonstrate that ToolPoker achieves state-of-the-art gameplay while producing reasoning traces that closely reflect game-theoretic principles.
Bradley-Terry and Multi-Objective Reward Modeling Are Complementary
Jul 10, 2025Reward models trained on human preference data have demonstrated strong effectiveness in aligning Large Language Models (LLMs) with human intent under the framework of Reinforcement Learning from Human Feedback (RLHF). However, RLHF remains vulnerable to reward hacking, where the policy exploits imperfections in the reward function rather than genuinely learning the intended behavior. Although significant efforts have been made to mitigate reward hacking, they predominantly focus on and evaluate in-distribution scenarios, where the training and testing data for the reward model share the same distribution. In this paper, we empirically show that state-of-the-art methods struggle in more challenging out-of-distribution (OOD) settings. We further demonstrate that incorporating fine-grained multi-attribute scores helps address this challenge. However, the limited availability of high-quality data often leads to weak performance of multi-objective reward functions, which can negatively impact overall performance and become the bottleneck. To address this issue, we propose a unified reward modeling framework that jointly trains Bradley--Terry (BT) single-objective and multi-objective regression-based reward functions using a shared embedding space. We theoretically establish a connection between the BT loss and the regression objective and highlight their complementary benefits. Specifically, the regression task enhances the single-objective reward function's ability to mitigate reward hacking in challenging OOD settings, while BT-based training improves the scoring capability of the multi-objective reward function, enabling a 7B model to outperform a 70B baseline. Extensive experimental results demonstrate that our framework significantly improves both the robustness and the scoring performance of reward models.
Cite Before You Speak: Enhancing Context-Response Grounding in E-commerce Conversational LLM-Agents
Mar 05, 2025



With the advancement of conversational large language models (LLMs), several LLM-based Conversational Shopping Agents (CSA) have been developed to help customers answer questions and smooth their shopping journey in e-commerce domain. The primary objective in building a trustworthy CSA is to ensure the agent's responses are accurate and factually grounded, which is essential for building customer trust and encouraging continuous engagement. However, two challenges remain. First, LLMs produce hallucinated or unsupported claims. Such inaccuracies risk spreading misinformation and diminishing customer trust. Second, without providing knowledge source attribution in CSA response, customers struggle to verify LLM-generated information. To address these challenges, we present an easily productionized solution that enables a "citation experience" utilizing In-context Learning (ICL) and Multi-UX-Inference (MUI) to generate responses with citations to attribute its original sources without interfering other existing UX features. With proper UX design, these citation marks can be linked to the related product information and display the source to our customers. In this work, we also build auto-metrics and scalable benchmarks to holistically evaluate LLM's grounding and attribution capabilities. Our experiments demonstrate that incorporating this citation generation paradigm can substantially enhance the grounding of LLM responses by 13.83% on the real-world data. As such, our solution not only addresses the immediate challenges of LLM grounding issues but also adds transparency to conversational AI.
How Far are LLMs from Real Search? A Comprehensive Study on Efficiency, Completeness, and Inherent Capabilities
Feb 26, 2025Search plays a fundamental role in problem-solving across various domains, with most real-world decision-making problems being solvable through systematic search. Drawing inspiration from recent discussions on search and learning, we systematically explore the complementary relationship between search and Large Language Models (LLMs) from three perspectives. First, we analyze how learning can enhance search efficiency and propose Search via Learning (SeaL), a framework that leverages LLMs for effective and efficient search. Second, we further extend SeaL to SeaL-C to ensure rigorous completeness during search. Our evaluation across three real-world planning tasks demonstrates that SeaL achieves near-perfect accuracy while reducing search spaces by up to 99.1% compared to traditional approaches. Finally, we explore how far LLMs are from real search by investigating whether they can develop search capabilities independently. Our analysis reveals that while current LLMs struggle with efficient search in complex problems, incorporating systematic search strategies significantly enhances their problem-solving capabilities. These findings not only validate the effectiveness of our approach but also highlight the need for improving LLMs' search abilities for real-world applications.
A General Framework to Enhance Fine-tuning-based LLM Unlearning
Feb 25, 2025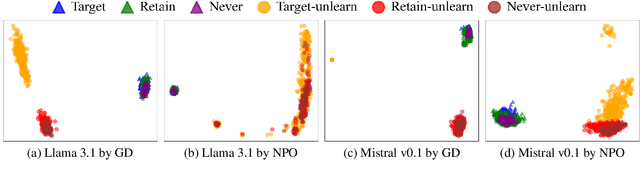
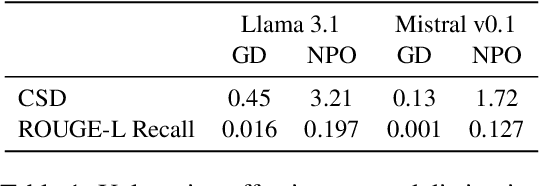
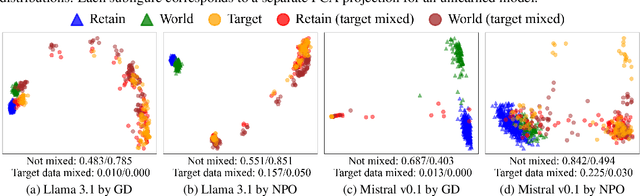
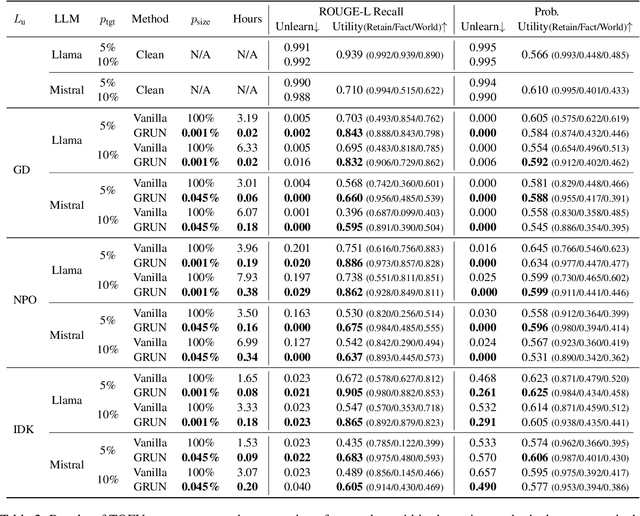
Unlearning has been proposed to remove copyrighted and privacy-sensitive data from Large Language Models (LLMs). Existing approaches primarily rely on fine-tuning-based methods, which can be categorized into gradient ascent-based (GA-based) and suppression-based methods. However, they often degrade model utility (the ability to respond to normal prompts). In this work, we aim to develop a general framework that enhances the utility of fine-tuning-based unlearning methods. To achieve this goal, we first investigate the common property between GA-based and suppression-based methods. We unveil that GA-based methods unlearn by distinguishing the target data (i.e., the data to be removed) and suppressing related generations, which is essentially the same strategy employed by suppression-based methods. Inspired by this finding, we introduce Gated Representation UNlearning (GRUN) which has two components: a soft gate function for distinguishing target data and a suppression module using Representation Fine-tuning (ReFT) to adjust representations rather than model parameters. Experiments show that GRUN significantly improves the unlearning and utility. Meanwhile, it is general for fine-tuning-based methods, efficient and promising for sequential unlearning.
Stepwise Perplexity-Guided Refinement for Efficient Chain-of-Thought Reasoning in Large Language Models
Feb 18, 2025Chain-of-Thought (CoT) reasoning, which breaks down complex tasks into intermediate reasoning steps, has significantly enhanced the performance of large language models (LLMs) on challenging tasks. However, the detailed reasoning process in CoT often incurs long generation times and high computational costs, partly due to the inclusion of unnecessary steps. To address this, we propose a method to identify critical reasoning steps using perplexity as a measure of their importance: a step is deemed critical if its removal causes a significant increase in perplexity. Our method enables models to focus solely on generating these critical steps. This can be achieved through two approaches: refining demonstration examples in few-shot CoT or fine-tuning the model using selected examples that include only critical steps. Comprehensive experiments validate the effectiveness of our method, which achieves a better balance between the reasoning accuracy and efficiency of CoT.
A Survey of Calibration Process for Black-Box LLMs
Dec 17, 2024



Large Language Models (LLMs) demonstrate remarkable performance in semantic understanding and generation, yet accurately assessing their output reliability remains a significant challenge. While numerous studies have explored calibration techniques, they primarily focus on White-Box LLMs with accessible parameters. Black-Box LLMs, despite their superior performance, pose heightened requirements for calibration techniques due to their API-only interaction constraints. Although recent researches have achieved breakthroughs in black-box LLMs calibration, a systematic survey of these methodologies is still lacking. To bridge this gap, we presents the first comprehensive survey on calibration techniques for black-box LLMs. We first define the Calibration Process of LLMs as comprising two interrelated key steps: Confidence Estimation and Calibration. Second, we conduct a systematic review of applicable methods within black-box settings, and provide insights on the unique challenges and connections in implementing these key steps. Furthermore, we explore typical applications of Calibration Process in black-box LLMs and outline promising future research directions, providing new perspectives for enhancing reliability and human-machine alignment. This is our GitHub link: https://github.com/LiangruXie/Calibration-Process-in-Black-Box-LLMs
Large Language Models for Social Networks: Applications, Challenges, and Solutions
Jan 04, 2024Large Language Models (LLMs) are transforming the way people generate, explore, and engage with content. We study how we can develop LLM applications for online social networks. Despite LLMs' successes in other domains, it is challenging to develop LLM-based products for social networks for numerous reasons, and it has been relatively under-reported in the research community. We categorize LLM applications for social networks into three categories. First is knowledge tasks where users want to find new knowledge and information, such as search and question-answering. Second is entertainment tasks where users want to consume interesting content, such as getting entertaining notification content. Third is foundational tasks that need to be done to moderate and operate the social networks, such as content annotation and LLM monitoring. For each task, we share the challenges we found, solutions we developed, and lessons we learned. To the best of our knowledge, this is the first comprehensive paper about developing LLM applications for social networks.
Let AI Entertain You: Increasing User Engagement with Generative AI and Rejection Sampling
Dec 16, 2023While generative AI excels in content generation, it does not always increase user engagement. This can be attributed to two main factors. First, generative AI generates content without incorporating explicit or implicit feedback about user interactions. Even if the generated content seems to be more informative or well-written, it does not necessarily lead to an increase in user activities, such as clicks. Second, there is a concern with the quality of the content generative AI produces, which often lacks the distinctiveness and authenticity that human-created content possesses. These two factors can lead to content that fails to meet specific needs and preferences of users, ultimately reducing its potential to be engaging. This paper presents a generic framework of how to improve user engagement with generative AI by leveraging user feedback. Our solutions employ rejection sampling, a technique used in reinforcement learning, to boost engagement metrics. We leveraged the framework in the context of email notification subject lines generation for an online social network, and achieved significant engagement metric lift including +1% Session and +0.4% Weekly Active Users. We believe our work offers a universal framework that enhances user engagement with generative AI, particularly when standard generative AI reaches its limits in terms of enhancing content to be more captivating. To the best of our knowledge, this represents an early milestone in the industry's successful use of generative AI to enhance user engagement.