 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoK: Machine Unlearning for Large Language Models
Jun 10, 2025

Large language model (LLM) unlearning has become a critical topic in machine learning, aiming to eliminate the influence of specific training data or knowledge without retraining the model from scratch. A variety of techniques have been proposed, including Gradient Ascent, model editing, and re-steering hidden representations. While existing surveys often organize these methods by their technical characteristics, such classifications tend to overlook a more fundamental dimension: the underlying intention of unlearning--whether it seeks to truly remove internal knowledge or merely suppress its behavioral effects. In this SoK paper, we propose a new taxonomy based on this intention-oriented perspective. Building on this taxonomy, we make three key contributions. First, we revisit recent findings suggesting that many removal methods may functionally behave like suppression, and explore whether true removal is necessary or achievable. Second, we survey existing evaluation strategies, identify limitations in current metrics and benchmarks, and suggest directions for developing more reliable and intention-aligned evaluations. Third, we highlight practical challenges--such as scalability and support for sequential unlearning--that currently hinder the broader deployment of unlearning methods. In summary, this work offers a comprehensive framework for understanding and advancing unlearning in generative AI, aiming to support future research and guide policy decisions around data removal and privacy.
Stepwise Perplexity-Guided Refinement for Efficient Chain-of-Thought Reasoning in Large Language Models
Feb 18, 2025Chain-of-Thought (CoT) reasoning, which breaks down complex tasks into intermediate reasoning steps, has significantly enhanced the performance of large language models (LLMs) on challenging tasks. However, the detailed reasoning process in CoT often incurs long generation times and high computational costs, partly due to the inclusion of unnecessary steps. To address this, we propose a method to identify critical reasoning steps using perplexity as a measure of their importance: a step is deemed critical if its removal causes a significant increase in perplexity. Our method enables models to focus solely on generating these critical steps. This can be achieved through two approaches: refining demonstration examples in few-shot CoT or fine-tuning the model using selected examples that include only critical steps. Comprehensive experiments validate the effectiveness of our method, which achieves a better balance between the reasoning accuracy and efficiency of CoT.
A Theoretical Understanding of Chain-of-Thought: Coherent Reasoning and Error-Aware Demonstration
Oct 21, 2024



Few-shot Chain-of-Thought (CoT) prompting has demonstrated strong performance in improving the reasoning capabilities of large language models (LLMs). While theoretical investigations have been conducted to understand CoT, the underlying transformer used in these studies isolates the CoT reasoning process into separated in-context learning steps (Stepwise ICL). In this work, we theoretically show that, compared to Stepwise ICL, the transformer gains better error correction ability and more accurate predictions if the reasoning from earlier steps (Coherent CoT) is integrated. Given that this coherent reasoning changes the behavior of the transformer, we further investigate the sensitivity of the transformer with Coherent CoT when the demonstration examples are corrupted at the inference stage. Our theoretical results indicate that the transformer is more sensitive to errors in intermediate reasoning steps than the final outcome. Building upon this observation, we propose an improvement on CoT by incorporating both correct and incorrect reasoning paths in the demonstration. Our experiments validate the effectiveness of the proposed approach.
Towards the Effect of Examples on In-Context Learning: A Theoretical Case Study
Oct 12, 2024



In-context learning (ICL) has emerged as a powerful capability for large language models (LLMs) to adapt to downstream tasks by leveraging a few (demonstration) examples. Despite its effectiveness, the mechanism behind ICL remains underexplored. To better understand how ICL integrates the examples with the knowledge learned by the LLM during pre-training (i.e., pre-training knowledge) and how the examples impact ICL, this paper conducts a theoretical study in binary classification tasks. In particular, we introduce a probabilistic model extending from the Gaussian mixture model to exactly quantify the impact of pre-training knowledge, label frequency, and label noise on the prediction accuracy. Based on our analysis, when the pre-training knowledge contradicts the knowledge in the examples, whether ICL prediction relies more on the pre-training knowledge or the examples depends on the number of examples. In addition, the label frequency and label noise of the examples both affect the accuracy of the ICL prediction, where the minor class has a lower accuracy, and how the label noise impacts the accuracy is determined by the specific noise level of the two classes. Extensive simulations are conducted to verify the correctness of the theoretical results, and real-data experiments also align with the theoretical insights. Our work reveals the role of pre-training knowledge and examples in ICL, offering a deeper understanding of LLMs' behaviors in classification tasks.
Six-CD: Benchmarking Concept Removals for Benign Text-to-image Diffusion Models
Jun 21, 2024
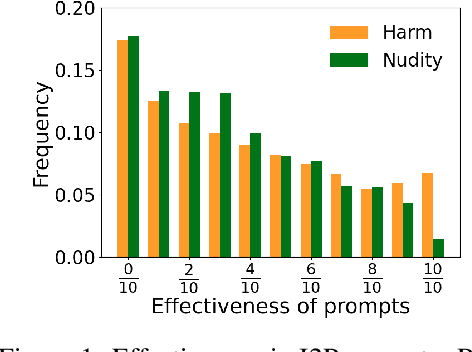
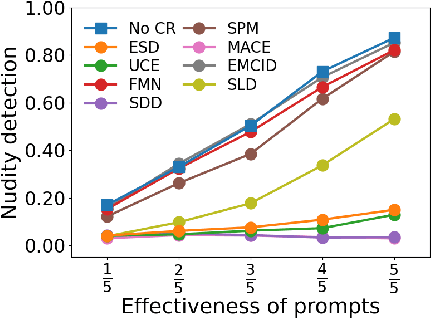

Text-to-image (T2I) diffusion models have shown exceptional capabilities in generating images that closely correspond to textual prompts. However, the advancement of T2I diffusion models presents significant risks, as the models could be exploited for malicious purposes, such as generating images with violence or nudity, or creating unauthorized portraits of public figures in inappropriate contexts. To mitigate these risks, concept removal methods have been proposed. These methods aim to modify diffusion models to prevent the generation of malicious and unwanted concepts. Despite these efforts, existing research faces several challenges: (1) a lack of consistent comparisons on a comprehensive dataset, (2) ineffective prompts in harmful and nudity concepts, (3) overlooked evaluation of the ability to generate the benign part within prompts containing malicious concepts. To address these gaps, we propose to benchmark the concept removal methods by introducing a new dataset, Six-CD, along with a novel evaluation metric. In this benchmark, we conduct a thorough evaluation of concept removals, with the experimental observations and discussions offering valuable insights in the field.
Copyright Protection in Generative AI: A Technical Perspective
Feb 04, 2024



Generative AI has witnessed rapid advancement in recent years, expanding their capabilities to create synthesized content such as text, images, audio, and code. The high fidelity and authenticity of contents generated by these Deep Generative Models (DGMs) have sparked significant copyright concerns. There have been various legal debates on how to effectively safeguard copyrights in DGMs. This work delves into this issue by providing a comprehensive overview of copyright protection from a technical perspective. We examine from two distinct viewpoints: the copyrights pertaining to the source data held by the data owners and those of the generative models maintained by the model builders. For data copyright, we delve into methods data owners can protect their content and DGMs can be utilized without infringing upon these rights. For model copyright, our discussion extends to strategies for preventing model theft and identifying outputs generated by specific models. Finally, we highlight the limitations of existing techniques and identify areas that remain unexplored. Furthermore, we discuss prospective directions for the future of copyright protection, underscoring its importance for the sustainable and ethical development of Generative AI.
Superiority of Multi-Head Attention in In-Context Linear Regression
Jan 30, 2024We present a theoretical analysis of the performance of transformer with softmax attention in in-context learning with linear regression tasks. While the existing literature predominantly focuses on the convergence of transformers with single-/multi-head attention, our research centers on comparing their performance. We conduct an exact theoretical analysis to demonstrate that multi-head attention with a substantial embedding dimension performs better than single-head attention. When the number of in-context examples D increases, the prediction loss using single-/multi-head attention is in O(1/D), and the one for multi-head attention has a smaller multiplicative constant. In addition to the simplest data distribution setting, we consider more scenarios, e.g., noisy labels, local examples, correlated features, and prior knowledge. We observe that, in general, multi-head attention is preferred over single-head attention. Our results verify the effectiveness of the design of multi-head attention in the transformer architecture.
FT-Shield: A Watermark Against Unauthorized Fine-tuning in Text-to-Image Diffusion Models
Oct 03, 2023



Text-to-image generative models based on latent diffusion models (LDM) have demonstrated their outstanding ability in generating high-quality and high-resolution images according to language prompt. Based on these powerful latent diffusion models, various fine-tuning methods have been proposed to achieve the personalization of text-to-image diffusion models such as artistic style adaptation and human face transfer. However, the unauthorized usage of data for model personalization has emerged as a prevalent concern in relation to copyright violations. For example, a malicious user may use the fine-tuning technique to generate images which mimic the style of a painter without his/her permission. In light of this concern, we have proposed FT-Shield, a watermarking approach specifically designed for the fine-tuning of text-to-image diffusion models to aid in detecting instances of infringement. We develop a novel algorithm for the generation of the watermark to ensure that the watermark on the training images can be quickly and accurately transferred to the generated images of text-to-image diffusion models. A watermark will be detected on an image by a binary watermark detector if the image is generated by a model that has been fine-tuned using the protected watermarked images. Comprehensive experiments were conducted to validate the effectiveness of FT-Shield.
On the Generalization of Training-based ChatGPT Detection Methods
Oct 03, 2023ChatGPT is one of the most popular language models which achieve amazing performance on various natural language tasks. Consequently, there is also an urgent need to detect the texts generated ChatGPT from human written. One of the extensively studied methods trains classification models to distinguish both. However, existing studies also demonstrate that the trained models may suffer from distribution shifts (during test), i.e., they are ineffective to predict the generated texts from unseen language tasks or topics. In this work, we aim to have a comprehensive investigation on these methods' generalization behaviors under distribution shift caused by a wide range of factors, including prompts, text lengths, topics, and language tasks. To achieve this goal, we first collect a new dataset with human and ChatGPT texts, and then we conduct extensive studies on the collected dataset. Our studies unveil insightful findings which provide guidance for developing future methodologies or data collection strategies for ChatGPT detection.