 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSiamJEPA: On the Role of Siamese Student Encoders in JEPA
Jul 04, 2026Recently, Joint Embedding Predictive Architectures (JEPAs) have attracted significant attention in the computer vision and machine learning communities as a promising framework for self-supervised representation learning. Unlike masked autoencoders that reconstruct pixels, JEPA models learn representations by predicting latent embeddings of masked regions. Existing JEPA-based methods, such as I-JEPA and V-JEPA, typically employ a single encoder in the student network. In contrast, using Siamese encoders for student network is more naturally aligned with brain-inspired representation learning frameworks, yet their role in JEPA models remains largely unexplored. In this paper, we investigate the effect of Siamese student encoders in JEPA-based representation learning. To this end, we propose SiamJEPA, masked Siamese student encoders equipped with an exponential moving average (EMA) teacher network. SiamJEPA can also be viewed as a JEPA formulation of the brain-inspired representation learning model PhiNet. Through extensive experiments on ImageNet linear probing, we demonstrate that Siamese encoders act as an effective regularizer for the JEPA objective, improving representation separability and accelerating learning during the early stages of training. Furthermore, SiamJEPA consistently outperforms comparable single-encoder JEPA variants under limited training budgets and achieves higher linear probing accuracy than Masked Autoencoders (MAE) which requires longer training. Our findings reveal that Siamese student encoders are not merely an architectural choice but constitute an important inductive bias for predictive representation learning. These results provide new insights into the design of JEPA-based models and suggest that incorporating Siamese student architectures offers a simple yet effective approach for improving self-supervised representation learning.
TIPS Over Tricks: Simple Prompts for Effective Zero-shot Anomaly Detection
Feb 03, 2026Anomaly detection identifies departures from expected behavior in safety-critical settings. When target-domain normal data are unavailable, zero-shot anomaly detection (ZSAD) leverages vision-language models (VLMs). However, CLIP's coarse image-text alignment limits both localization and detection due to (i) spatial misalignment and (ii) weak sensitivity to fine-grained anomalies; prior work compensates with complex auxiliary modules yet largely overlooks the choice of backbone. We revisit the backbone and use TIPS-a VLM trained with spatially aware objectives. While TIPS alleviates CLIP's issues, it exposes a distributional gap between global and local features. We address this with decoupled prompts-fixed for image-level detection and learnable for pixel-level localization-and by injecting local evidence into the global score. Without CLIP-specific tricks, our TIPS-based pipeline improves image-level performance by 1.1-3.9% and pixel-level by 1.5-6.9% across seven industrial datasets, delivering strong generalization with a lean architecture. Code is available at github.com/AlirezaSalehy/Tipsomaly.
When LRP Diverges from Leave-One-Out in Transformers
Oct 21, 2025


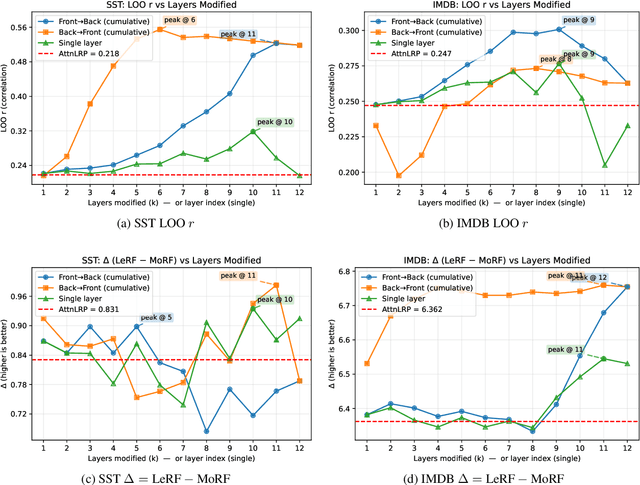
Leave-One-Out (LOO) provides an intuitive measure of feature importance but is computationally prohibitive. While Layer-Wise Relevance Propagation (LRP) offers a potentially efficient alternative, its axiomatic soundness in modern Transformers remains largely under-examined. In this work, we first show that the bilinear propagation rules used in recent advances of AttnLRP violate the implementation invariance axiom. We prove this analytically and confirm it empirically in linear attention layers. Second, we also revisit CP-LRP as a diagnostic baseline and find that bypassing relevance propagation through the softmax layer -- backpropagating relevance only through the value matrices -- significantly improves alignment with LOO, particularly in middle-to-late Transformer layers. Overall, our results suggest that (i) bilinear factorization sensitivity and (ii) softmax propagation error potentially jointly undermine LRP's ability to approximate LOO in Transformers.
Sparse minimum Redundancy Maximum Relevance for feature selection
Aug 26, 2025We propose a feature screening method that integrates both feature-feature and feature-target relationships. Inactive features are identified via a penalized minimum Redundancy Maximum Relevance (mRMR) procedure, which is the continuous version of the classic mRMR penalized by a non-convex regularizer, and where the parameters estimated as zero coefficients represent the set of inactive features. We establish the conditions under which zero coefficients are correctly identified to guarantee accurate recovery of inactive features. We introduce a multi-stage procedure based on the knockoff filter enabling the penalized mRMR to discard inactive features while controlling the false discovery rate (FDR). Our method performs comparably to HSIC-LASSO but is more conservative in the number of selected features. It only requires setting an FDR threshold, rather than specifying the number of features to retain. The effectiveness of the method is illustrated through simulations and real-world datasets. The code to reproduce this work is available on the following GitHub: https://github.com/PeterJackNaylor/SmRMR.
PhiNet v2: A Mask-Free Brain-Inspired Vision Foundation Model from Video
May 16, 2025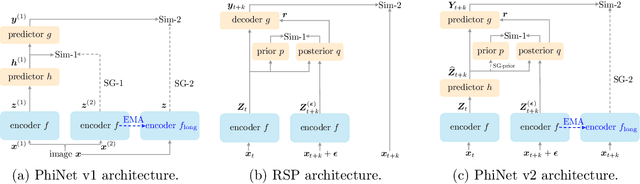

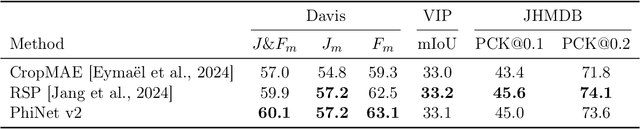

Recent advances in self-supervised learning (SSL) have revolutionized computer vision through innovative architectures and learning objectives, yet they have not fully leveraged insights from biological visual processing systems. Recently, a brain-inspired SSL model named PhiNet was proposed; it is based on a ResNet backbone and operates on static image inputs with strong augmentation. In this paper, we introduce PhiNet v2, a novel Transformer-based architecture that processes temporal visual input (that is, sequences of images) without relying on strong augmentation. Our model leverages variational inference to learn robust visual representations from continuous input streams, similar to human visual processing. Through extensive experimentation, we demonstrate that PhiNet v2 achieves competitive performance compared to state-of-the-art vision foundation models, while maintaining the ability to learn from sequential input without strong data augmentation. This work represents a significant step toward more biologically plausible computer vision systems that process visual information in a manner more closely aligned with human cognitive processes.
Crane: Context-Guided Prompt Learning and Attention Refinement for Zero-Shot Anomaly Detections
Apr 15, 2025



Anomaly Detection (AD) involves identifying deviations from normal data distributions and is critical in fields such as medical diagnostics and industrial defect detection. Traditional AD methods typically require the availability of normal training samples; however, this assumption is not always feasible, as collecting such data can be impractical. Additionally, these methods often struggle to generalize across different domains. Recent advancements, such as AnomalyCLIP and AdaCLIP, utilize the zero-shot generalization capabilities of CLIP but still face a performance gap between image-level and pixel-level anomaly detection. To address this gap, we propose a novel approach that conditions the prompts of the text encoder based on image context extracted from the vision encoder. Also, to capture fine-grained variations more effectively, we have modified the CLIP vision encoder and altered the extraction of dense features. These changes ensure that the features retain richer spatial and structural information for both normal and anomalous prompts. Our method achieves state-of-the-art performance, improving performance by 2% to 29% across different metrics on 14 datasets. This demonstrates its effectiveness in both image-level and pixel-level anomaly detection.
Many-to-Many Matching via Sparsity Controlled Optimal Transport
Mar 31, 2025



Many-to-many matching seeks to match multiple points in one set and multiple points in another set, which is a basis for a wide range of data mining problems. It can be naturally recast in the framework of Optimal Transport (OT). However, existing OT methods either lack the ability to accomplish many-to-many matching or necessitate careful tuning of a regularization parameter to achieve satisfactory results. This paper proposes a novel many-to-many matching method to explicitly encode many-to-many constraints while preventing the degeneration into one-to-one matching. The proposed method consists of the following two components. The first component is the matching budget constraints on each row and column of a transport plan, which specify how many points can be matched to a point at most. The second component is the deformed $q$-entropy regularization, which encourages a point to meet the matching budget maximally. While the deformed $q$-entropy was initially proposed to sparsify a transport plan, we employ it to avoid the degeneration into one-to-one matching. We optimize the objective via a penalty algorithm, which is efficient and theoretically guaranteed to converge. Experimental results on various tasks demonstrate that the proposed method achieves good performance by gleaning meaningful many-to-many matchings.
Efficient Model Editing with Task Vector Bases: A Theoretical Framework and Scalable Approach
Feb 03, 2025

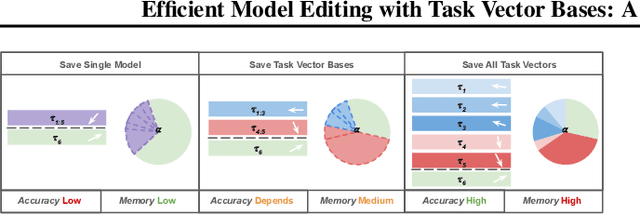

Task vectors, which are derived from the difference between pre-trained and fine-tuned model weights, enable flexible task adaptation and model merging through arithmetic operations such as addition and negation. However, existing approaches often rely on heuristics with limited theoretical support, often leading to performance gaps comparing to direct task fine tuning. Meanwhile, although it is easy to manipulate saved task vectors with arithmetic for different purposes, such compositional flexibility demands high memory usage, especially when dealing with a huge number of tasks, limiting scalability. This work addresses these issues with a theoretically grounded framework that explains task vector arithmetic and introduces the task vector bases framework. Building upon existing task arithmetic literature, our method significantly reduces the memory cost for downstream arithmetic with little effort, while achieving competitive performance and maintaining compositional advantage, providing a practical solution for large-scale task arithmetic.
On Verbalized Confidence Scores for LLMs
Dec 19, 2024
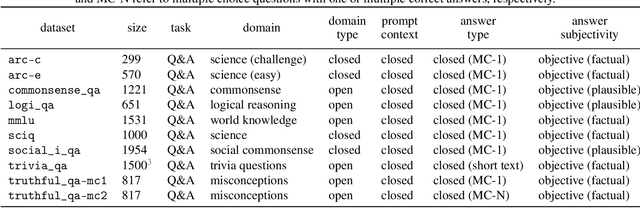

The rise of large language models (LLMs) and their tight integration into our daily life make it essential to dedicate efforts towards their trustworthiness. Uncertainty quantification for LLMs can establish more human trust into their responses, but also allows LLM agents to make more informed decisions based on each other's uncertainty. To estimate the uncertainty in a response, internal token logits, task-specific proxy models, or sampling of multiple responses are commonly used. This work focuses on asking the LLM itself to verbalize its uncertainty with a confidence score as part of its output tokens, which is a promising way for prompt- and model-agnostic uncertainty quantification with low overhead. Using an extensive benchmark, we assess the reliability of verbalized confidence scores with respect to different datasets, models, and prompt methods. Our results reveal that the reliability of these scores strongly depends on how the model is asked, but also that it is possible to extract well-calibrated confidence scores with certain prompt methods. We argue that verbalized confidence scores can become a simple but effective and versatile uncertainty quantification method in the future. Our code is available at https://github.com/danielyxyang/llm-verbalized-uq .
Learning Structured Representations with Hyperbolic Embeddings
Dec 02, 2024


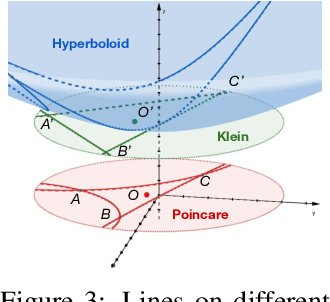
Most real-world datasets consist of a natural hierarchy between classes or an inherent label structure that is either already available or can be constructed cheaply. However, most existing representation learning methods ignore this hierarchy, treating labels as permutation invariant. Recent work [Zeng et al., 2022] proposes using this structured information explicitly, but the use of Euclidean distance may distort the underlying semantic context [Chen et al., 2013]. In this work, motivated by the advantage of hyperbolic spaces in modeling hierarchical relationships, we propose a novel approach HypStructure: a Hyperbolic Structured regularization approach to accurately embed the label hierarchy into the learned representations. HypStructure is a simple-yet-effective regularizer that consists of a hyperbolic tree-based representation loss along with a centering loss, and can be combined with any standard task loss to learn hierarchy-informed features. Extensive experiments on several large-scale vision benchmarks demonstrate the efficacy of HypStructure in reducing distortion and boosting generalization performance especially under low dimensional scenarios. For a better understanding of structured representation, we perform eigenvalue analysis that links the representation geometry to improved Out-of-Distribution (OOD) detection performance seen empirically. The code is available at \url{https://github.com/uiuctml/HypStructure}.