 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePI-Hunter: Automated Red-Teaming for Exposing and Localizing Prompt Injections
Jun 10, 2026Large Language Models (LLMs) are rapidly evolving into agentic systems that interact with external tools and environments, introducing new security risks such as indirect prompt injection attacks through untrusted external sources. Existing defenses mainly focus on blocking malicious content at inference time, and current red-teaming methods primarily optimize attack success. As a result, developers have limited visibility into how latent prompt injections emerge and propagate through agents. We propose PI-Hunter, an automated agentic auditing framework for proactive vulnerability exposure in LLM agents. PI-Hunter constructs realistic source-aware test cases and iteratively evolves them through feedback-driven exploration to induce agents to retrieve and reveal latent malicious instructions embedded within external environments. Extensive experiments across multiple benchmarks, agent architectures, attacks, and defenses demonstrate that PI-Hunter substantially improves vulnerability exposure and attack-surface coverage over strong automated red-teaming baselines, while remaining effective under existing prompt injection defenses.
"**Important** You should give me full credits!": Exploring Prompt Injection Attacks on LLM-Based Automatic Grading Systems
Jun 02, 2026The emergence of large language models (LLMs) has significantly accelerated recent research on LLM-based automatic grading (AG) systems. Benefiting from the strong instruction-following capabilities and broad prior knowledge of LLMs, educators can deploy AG systems across diverse tasks using only natural language rubrics while achieving satisfactory grading performance. Despite these advantages, new security concerns may also arise. In particular, prompt injection (PI) attacks have recently become a major threat to LLM-based applications. In the context of AG, attackers can potentially exploit PI vulnerabilities to manipulate grading systems into assigning artificially high scores regardless of the actual answer quality. Such behavior poses serious risks to the fairness, reliability, and integrity of educational assessment. In this work, we study PI attacks in AG systems, and systematically investigate the effectiveness of such attacks in educational scenarios. We further evaluate the effectiveness of existing defensive strategies against these attacks. Through comprehensive experiments under rubric-based grading settings, we demonstrate that current LLM-based AG systems remain highly vulnerable to PI attacks. We hope that our findings raise awareness of this emerging threat and motivate future research toward secure, robust, and trustworthy LLM-based educational systems.
A Simple Plug-in for Improving Eviction-Based KV Cache Compression
May 22, 2026KV cache growth is a major bottleneck for long-context inference in large language models. Existing methods are often dominated by binary eviction or representation approximation, which may underutilize tokens that are not critical for exact retention but are still reconstructable. We present VECTOR, a plug-and-play augmentation for eviction-based pipelines that introduces three-way token routing: retention, approximation, and eviction. VECTOR combines an importance signal from the base scorer with a reconstructability signal from an offline-calibrated regression-based value estimation. By leveraging reconstructability, VECTOR recovers useful value information that would otherwise be irreversibly lost under binary eviction, while preserving key vectors for attention routing stability. Experimental results show that VECTOR improves quality-memory trade-offs under medium-to-high compression, with especially clear gains in stricter budget regimes.
Crafting Reversible SFT Behaviors in Large Language Models
May 07, 2026Supervised fine-tuning (SFT) induces new behaviors in large language models, yet imposes no structural constraint on how these behaviors are distributed within the model. Existing behavior interpretation methods, such as circuit attribution approaches, identify sparse subnetworks correlated with SFT-induced behaviors post-hoc. However, such correlations do not imply *causal necessity*, limiting the ability to selectively control SFT-induced behaviors at inference time. We pursue an alternative by asking: can an SFT-induced behavior be deliberately compressed into a sparse, mechanistically necessary subnetwork, termed a *carrier*, while remaining controllable at inference time without weight modification? We propose (a) **Loss-Constrained Dual Descent (LCDD)**, which constructs such carriers by jointly optimizing routing masks and model weights under an explicit utility budget, and (b) **SFT-Eraser**, a soft prompt optimized via activation matching on extracted carrier channels, to reverse the SFT-induced behavior. Across safety, fixed-response, and style behaviors on multiple model families, LCDD yields sparse carriers that preserve target behaviors while enabling strong reversion when triggered by SFT-Eraser. Ablations further establish that the sparse structure is the key precondition for reversal: the same trigger optimization fails on standard SFT models, confirming that structure rather than trigger design is the operative factor. These results provide direct evidence that the learned carriers are causally necessary for the behaviors, pointing to a new direction for systematically localizing and selectively suppressing SFT-induced behaviors in deployed models.
MAEB: Massive Audio Embedding Benchmark
Feb 17, 2026We introduce the Massive Audio Embedding Benchmark (MAEB), a large-scale benchmark covering 30 tasks across speech, music, environmental sounds, and cross-modal audio-text reasoning in 100+ languages. We evaluate 50+ models and find that no single model dominates across all tasks: contrastive audio-text models excel at environmental sound classification (e.g., ESC50) but score near random on multilingual speech tasks (e.g., SIB-FLEURS), while speech-pretrained models show the opposite pattern. Clustering remains challenging for all models, with even the best-performing model achieving only modest results. We observe that models excelling on acoustic understanding often perform poorly on linguistic tasks, and vice versa. We also show that the performance of audio encoders on MAEB correlates highly with their performance when used in audio large language models. MAEB is derived from MAEB+, a collection of 98 tasks. MAEB is designed to maintain task diversity while reducing evaluation cost, and it integrates into the MTEB ecosystem for unified evaluation across text, image, and audio modalities. We release MAEB and all 98 tasks along with code and a leaderboard at https://github.com/embeddings-benchmark/mteb.
Embedding Perturbation may Better Reflect the Uncertainty in LLM Reasoning
Feb 02, 2026Large language Models (LLMs) have achieved significant breakthroughs across diverse domains; however, they can still produce unreliable or misleading outputs. For responsible LLM application, Uncertainty Quantification (UQ) techniques are used to estimate a model's uncertainty about its outputs, indicating the likelihood that those outputs may be problematic. For LLM reasoning tasks, it is essential to estimate the uncertainty not only for the final answer, but also for the intermediate steps of the reasoning, as this can enable more fine-grained and targeted interventions. In this study, we explore what UQ metrics better reflect the LLM's ``intermediate uncertainty''during reasoning. Our study reveals that an LLMs' incorrect reasoning steps tend to contain tokens which are highly sensitive to the perturbations on the preceding token embeddings. In this way, incorrect (uncertain) intermediate steps can be readily identified using this sensitivity score as guidance in practice. In our experiments, we show such perturbation-based metric achieves stronger uncertainty quantification performance compared with baseline methods such as token (generation) probability and token entropy. Besides, different from approaches that rely on multiple sampling, the perturbation-based metrics offer better simplicity and efficiency.
Co-RedTeam: Orchestrated Security Discovery and Exploitation with LLM Agents
Feb 02, 2026Large language models (LLMs) have shown promise in assisting cybersecurity tasks, yet existing approaches struggle with automatic vulnerability discovery and exploitation due to limited interaction, weak execution grounding, and a lack of experience reuse. We propose Co-RedTeam, a security-aware multi-agent framework designed to mirror real-world red-teaming workflows by integrating security-domain knowledge, code-aware analysis, execution-grounded iterative reasoning, and long-term memory. Co-RedTeam decomposes vulnerability analysis into coordinated discovery and exploitation stages, enabling agents to plan, execute, validate, and refine actions based on real execution feedback while learning from prior trajectories. Extensive evaluations on challenging security benchmarks demonstrate that Co-RedTeam consistently outperforms strong baselines across diverse backbone models, achieving over 60% success rate in vulnerability exploitation and over 10% absolute improvement in vulnerability detection. Ablation and iteration studies further confirm the critical role of execution feedback, structured interaction, and memory for building robust and generalizable cybersecurity agents.
Interpretable Probability Estimation with LLMs via Shapley Reconstruction
Jan 14, 2026Large Language Models (LLMs) demonstrate potential to estimate the probability of uncertain events, by leveraging their extensive knowledge and reasoning capabilities. This ability can be applied to support intelligent decision-making across diverse fields, such as financial forecasting and preventive healthcare. However, directly prompting LLMs for probability estimation faces significant challenges: their outputs are often noisy, and the underlying predicting process is opaque. In this paper, we propose PRISM: Probability Reconstruction via Shapley Measures, a framework that brings transparency and precision to LLM-based probability estimation. PRISM decomposes an LLM's prediction by quantifying the marginal contribution of each input factor using Shapley values. These factor-level contributions are then aggregated to reconstruct a calibrated final estimate. In our experiments, we demonstrate PRISM improves predictive accuracy over direct prompting and other baselines, across multiple domains including finance, healthcare, and agriculture. Beyond performance, PRISM provides a transparent prediction pipeline: our case studies visualize how individual factors shape the final estimate, helping build trust in LLM-based decision support systems.
SITP: A High-Reliability Semantic Information Transport Protocol Without Retransmission for Semantic Communication
Dec 10, 2025With the evolution of 6G networks, modern communication systems are facing unprecedented demands for high reliability and low latency. However, conventional transport protocols are designed for bit-level reliability, failing to meet the semantic robustness requirements. To address this limitation, this paper proposes a novel Semantic Information Transport Protocol (SITP), which achieves TCP-level reliability and UDP level latency by verifying only packet headers while retaining potentially corrupted payloads for semantic decoding. Building upon SITP, a cross-layer analytical model is established to quantify packet-loss probability across the physical, data-link, network, transport, and application layers. The model provides a unified probabilistic formulation linking signal noise rate (SNR) and packet-loss rate, offering theoretical foundation into end-to-end semantic transmission. Furthermore, a cross-image feature interleaving mechanism is developed to mitigate consecutive burst losses by redistributing semantic features across multiple correlated images, thereby enhancing robustness in burst-fade channels. Extensive experiments show that SITP offers lower latency than TCP with comparable reliability at low SNRs, while matching UDP-level latency and delivering superior reconstruction quality. In addition, the proposed cross-image semantic interleaving mechanism further demonstrates its effectiveness in mitigating degradation caused by bursty packet losses.
NOC4SC: A Bandwidth-Efficient Multi-User Semantic Communication Framework for Interference-Resilient Transmission
Dec 10, 2025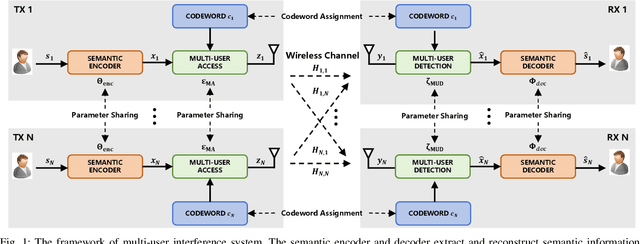
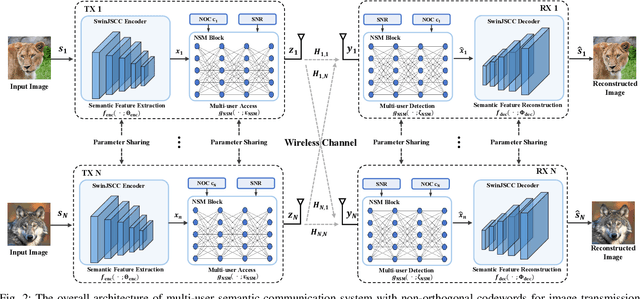
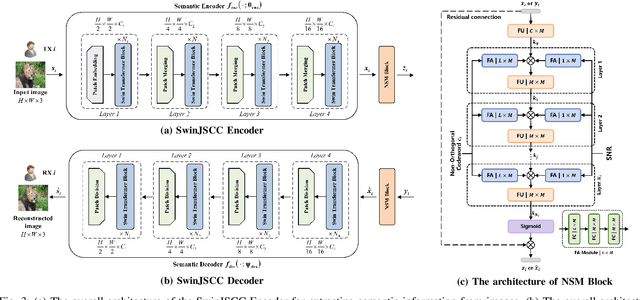
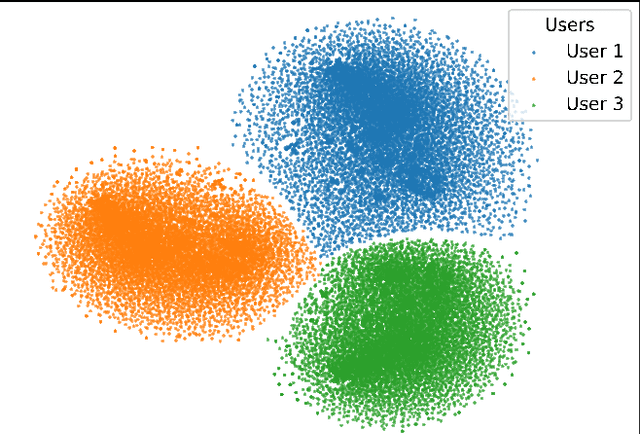
With the explosive growth of connected devices and emerging applications, current wireless networks are encountering unprecedented demands for massive user access, where the inter-user interference has become a critical challenge to maintaining high quality of service (QoS) in multi-user communication systems. To tackle this issue, we propose a bandwidth-efficient semantic communication paradigm termed Non-Orthogonal Codewords for Semantic Communication (NOC4SC), which enables simultaneous same-frequency transmission without spectrum spreading. By leveraging the Swin Transformer, the proposed NOC4SC framework enables each user to independently extract semantic features through a unified encoder-decoder architecture with shared network parameters across all users, which ensures that the user's data remains protected from unauthorized decoding. Furthermore, we introduce an adaptive NOC and SNR Modulation (NSM) block, which employs deep learning to dynamically regulate SNR and generate approximately orthogonal semantic features within distinct feature subspaces, thereby effectively mitigating inter-user interference. Extensive experiments demonstrate the proposed NOC4SC achieves comparable performance to the DeepJSCC-PNOMA and outperforms other multi-user SemCom baseline methods.