 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Do Latent Reasoning Methods Perform Under Weak and Strong Supervision?
Feb 25, 2026Latent reasoning has been recently proposed as a reasoning paradigm and performs multi-step reasoning through generating steps in the latent space instead of the textual space. This paradigm enables reasoning beyond discrete language tokens by performing multi-step computation in continuous latent spaces. Although there have been numerous studies focusing on improving the performance of latent reasoning, its internal mechanisms remain not fully investigated. In this work, we conduct a comprehensive analysis of latent reasoning methods to better understand the role and behavior of latent representation in the process. We identify two key issues across latent reasoning methods with different levels of supervision. First, we observe pervasive shortcut behavior, where they achieve high accuracy without relying on latent reasoning. Second, we examine the hypothesis that latent reasoning supports BFS-like exploration in latent space, and find that while latent representations can encode multiple possibilities, the reasoning process does not faithfully implement structured search, but instead exhibits implicit pruning and compression. Finally, our findings reveal a trade-off associated with supervision strength: stronger supervision mitigates shortcut behavior but restricts the ability of latent representations to maintain diverse hypotheses, whereas weaker supervision allows richer latent representations at the cost of increased shortcut behavior.
How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use
Jan 31, 2026As Large Language Models (LLMs) are increasingly applied in high-stakes domains, their ability to reason strategically under uncertainty becomes critical. Poker provides a rigorous testbed, requiring not only strong actions but also principled, game-theoretic reasoning. In this paper, we conduct a systematic study of LLMs in multiple realistic poker tasks, evaluating both gameplay outcomes and reasoning traces. Our analysis reveals LLMs fail to compete against traditional algorithms and identifies three recurring flaws: reliance on heuristics, factual misunderstandings, and a "knowing-doing" gap where actions diverge from reasoning. An initial attempt with behavior cloning and step-level reinforcement learning improves reasoning style but remains insufficient for accurate game-theoretic play. Motivated by these limitations, we propose ToolPoker, a tool-integrated reasoning framework that combines external solvers for GTO-consistent actions with more precise professional-style explanations. Experiments demonstrate that ToolPoker achieves state-of-the-art gameplay while producing reasoning traces that closely reflect game-theoretic principles.
Position: Agentic Evolution is the Path to Evolving LLMs
Jan 30, 2026As Large Language Models (LLMs) move from curated training sets into open-ended real-world environments, a fundamental limitation emerges: static training cannot keep pace with continual deployment environment change. Scaling training-time and inference-time compute improves static capability but does not close this train-deploy gap. We argue that addressing this limitation requires a new scaling axis-evolution. Existing deployment-time adaptation methods, whether parametric fine-tuning or heuristic memory accumulation, lack the strategic agency needed to diagnose failures and produce durable improvements. Our position is that agentic evolution represents the inevitable future of LLM adaptation, elevating evolution itself from a fixed pipeline to an autonomous evolver agent. We instantiate this vision in a general framework, A-Evolve, which treats deployment-time improvement as a deliberate, goal-directed optimization process over persistent system state. We further propose the evolution-scaling hypothesis: the capacity for adaptation scales with the compute allocated to evolution, positioning agentic evolution as a scalable path toward sustained, open-ended adaptation in the real world.
TRAJECT-Bench:A Trajectory-Aware Benchmark for Evaluating Agentic Tool Use
Oct 06, 2025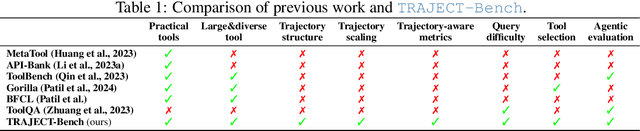

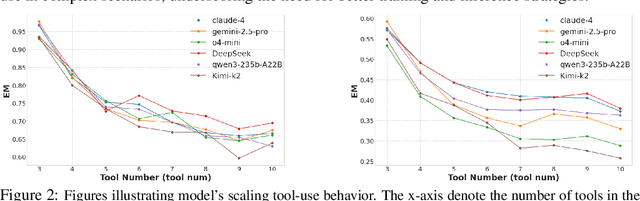
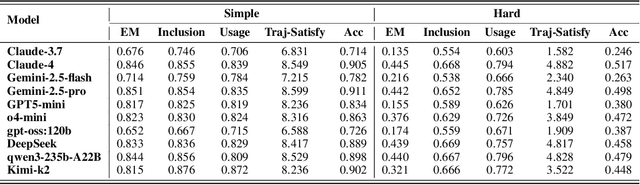
Large language model (LLM)-based agents increasingly rely on tool use to complete real-world tasks. While existing works evaluate the LLMs' tool use capability, they largely focus on the final answers yet overlook the detailed tool usage trajectory, i.e., whether tools are selected, parameterized, and ordered correctly. We introduce TRAJECT-Bench, a trajectory-aware benchmark to comprehensively evaluate LLMs' tool use capability through diverse tasks with fine-grained evaluation metrics. TRAJECT-Bench pairs high-fidelity, executable tools across practical domains with tasks grounded in production-style APIs, and synthesizes trajectories that vary in breadth (parallel calls) and depth (interdependent chains). Besides final accuracy, TRAJECT-Bench also reports trajectory-level diagnostics, including tool selection and argument correctness, and dependency/order satisfaction. Analyses reveal failure modes such as similar tool confusion and parameter-blind selection, and scaling behavior with tool diversity and trajectory length where the bottleneck of transiting from short to mid-length trajectories is revealed, offering actionable guidance for LLMs' tool use.
Bradley-Terry and Multi-Objective Reward Modeling Are Complementary
Jul 10, 2025Reward models trained on human preference data have demonstrated strong effectiveness in aligning Large Language Models (LLMs) with human intent under the framework of Reinforcement Learning from Human Feedback (RLHF). However, RLHF remains vulnerable to reward hacking, where the policy exploits imperfections in the reward function rather than genuinely learning the intended behavior. Although significant efforts have been made to mitigate reward hacking, they predominantly focus on and evaluate in-distribution scenarios, where the training and testing data for the reward model share the same distribution. In this paper, we empirically show that state-of-the-art methods struggle in more challenging out-of-distribution (OOD) settings. We further demonstrate that incorporating fine-grained multi-attribute scores helps address this challenge. However, the limited availability of high-quality data often leads to weak performance of multi-objective reward functions, which can negatively impact overall performance and become the bottleneck. To address this issue, we propose a unified reward modeling framework that jointly trains Bradley--Terry (BT) single-objective and multi-objective regression-based reward functions using a shared embedding space. We theoretically establish a connection between the BT loss and the regression objective and highlight their complementary benefits. Specifically, the regression task enhances the single-objective reward function's ability to mitigate reward hacking in challenging OOD settings, while BT-based training improves the scoring capability of the multi-objective reward function, enabling a 7B model to outperform a 70B baseline. Extensive experimental results demonstrate that our framework significantly improves both the robustness and the scoring performance of reward models.
Cite Before You Speak: Enhancing Context-Response Grounding in E-commerce Conversational LLM-Agents
Mar 05, 2025



With the advancement of conversational large language models (LLMs), several LLM-based Conversational Shopping Agents (CSA) have been developed to help customers answer questions and smooth their shopping journey in e-commerce domain. The primary objective in building a trustworthy CSA is to ensure the agent's responses are accurate and factually grounded, which is essential for building customer trust and encouraging continuous engagement. However, two challenges remain. First, LLMs produce hallucinated or unsupported claims. Such inaccuracies risk spreading misinformation and diminishing customer trust. Second, without providing knowledge source attribution in CSA response, customers struggle to verify LLM-generated information. To address these challenges, we present an easily productionized solution that enables a "citation experience" utilizing In-context Learning (ICL) and Multi-UX-Inference (MUI) to generate responses with citations to attribute its original sources without interfering other existing UX features. With proper UX design, these citation marks can be linked to the related product information and display the source to our customers. In this work, we also build auto-metrics and scalable benchmarks to holistically evaluate LLM's grounding and attribution capabilities. Our experiments demonstrate that incorporating this citation generation paradigm can substantially enhance the grounding of LLM responses by 13.83% on the real-world data. As such, our solution not only addresses the immediate challenges of LLM grounding issues but also adds transparency to conversational AI.
How Far are LLMs from Real Search? A Comprehensive Study on Efficiency, Completeness, and Inherent Capabilities
Feb 26, 2025Search plays a fundamental role in problem-solving across various domains, with most real-world decision-making problems being solvable through systematic search. Drawing inspiration from recent discussions on search and learning, we systematically explore the complementary relationship between search and Large Language Models (LLMs) from three perspectives. First, we analyze how learning can enhance search efficiency and propose Search via Learning (SeaL), a framework that leverages LLMs for effective and efficient search. Second, we further extend SeaL to SeaL-C to ensure rigorous completeness during search. Our evaluation across three real-world planning tasks demonstrates that SeaL achieves near-perfect accuracy while reducing search spaces by up to 99.1% compared to traditional approaches. Finally, we explore how far LLMs are from real search by investigating whether they can develop search capabilities independently. Our analysis reveals that while current LLMs struggle with efficient search in complex problems, incorporating systematic search strategies significantly enhances their problem-solving capabilities. These findings not only validate the effectiveness of our approach but also highlight the need for improving LLMs' search abilities for real-world applications.
A General Framework to Enhance Fine-tuning-based LLM Unlearning
Feb 25, 2025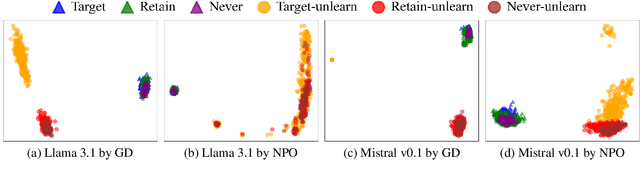
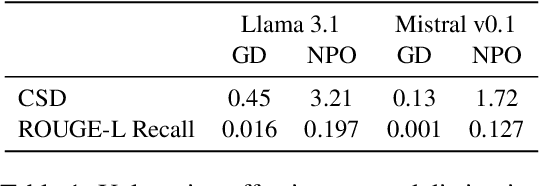
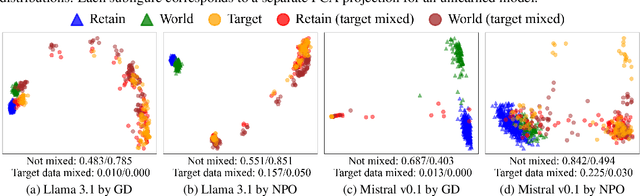
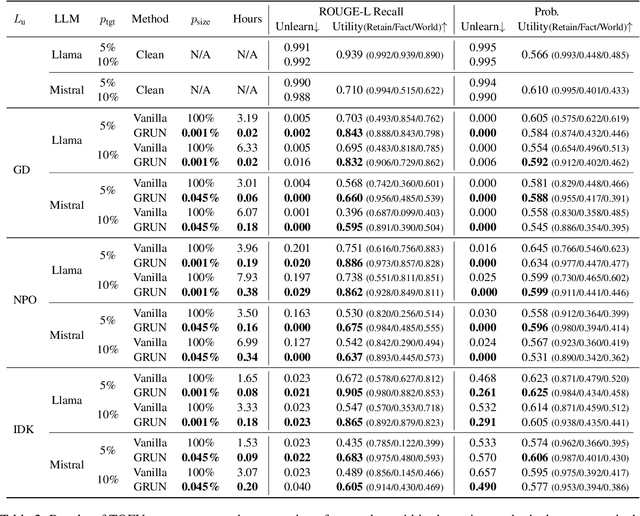
Unlearning has been proposed to remove copyrighted and privacy-sensitive data from Large Language Models (LLMs). Existing approaches primarily rely on fine-tuning-based methods, which can be categorized into gradient ascent-based (GA-based) and suppression-based methods. However, they often degrade model utility (the ability to respond to normal prompts). In this work, we aim to develop a general framework that enhances the utility of fine-tuning-based unlearning methods. To achieve this goal, we first investigate the common property between GA-based and suppression-based methods. We unveil that GA-based methods unlearn by distinguishing the target data (i.e., the data to be removed) and suppressing related generations, which is essentially the same strategy employed by suppression-based methods. Inspired by this finding, we introduce Gated Representation UNlearning (GRUN) which has two components: a soft gate function for distinguishing target data and a suppression module using Representation Fine-tuning (ReFT) to adjust representations rather than model parameters. Experiments show that GRUN significantly improves the unlearning and utility. Meanwhile, it is general for fine-tuning-based methods, efficient and promising for sequential unlearning.
Stepwise Perplexity-Guided Refinement for Efficient Chain-of-Thought Reasoning in Large Language Models
Feb 18, 2025Chain-of-Thought (CoT) reasoning, which breaks down complex tasks into intermediate reasoning steps, has significantly enhanced the performance of large language models (LLMs) on challenging tasks. However, the detailed reasoning process in CoT often incurs long generation times and high computational costs, partly due to the inclusion of unnecessary steps. To address this, we propose a method to identify critical reasoning steps using perplexity as a measure of their importance: a step is deemed critical if its removal causes a significant increase in perplexity. Our method enables models to focus solely on generating these critical steps. This can be achieved through two approaches: refining demonstration examples in few-shot CoT or fine-tuning the model using selected examples that include only critical steps. Comprehensive experiments validate the effectiveness of our method, which achieves a better balance between the reasoning accuracy and efficiency of CoT.
SimRAG: Self-Improving Retrieval-Augmented Generation for Adapting Large Language Models to Specialized Domains
Oct 23, 2024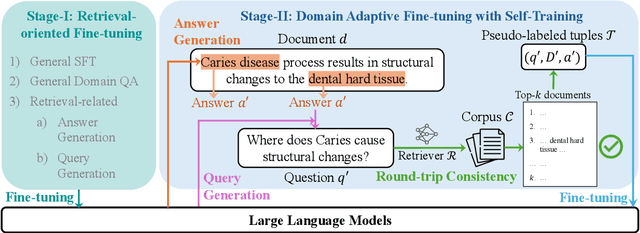
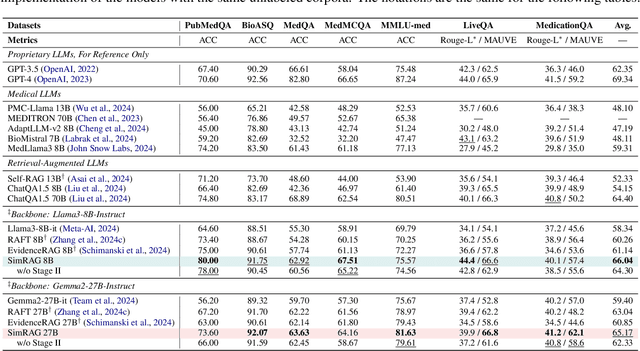
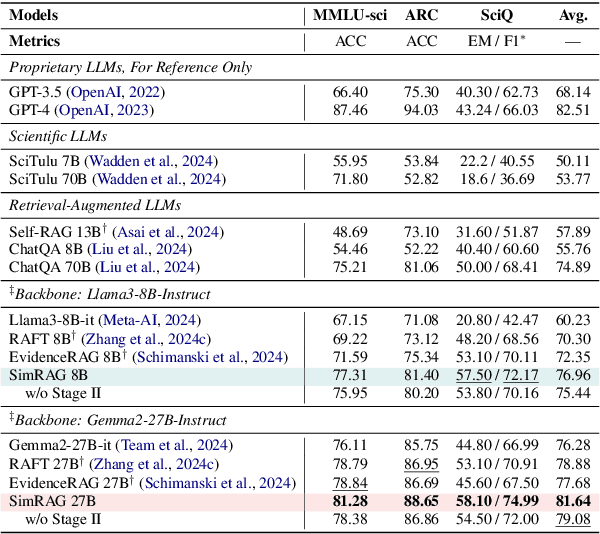
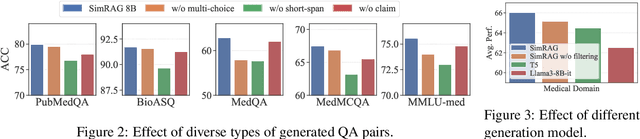
Retrieval-augmented generation (RAG) enhances the question-answering (QA) abilities of large language models (LLMs) by integrating external knowledge. However, adapting general-purpose RAG systems to specialized fields such as science and medicine poses unique challenges due to distribution shifts and limited access to domain-specific data. To tackle this, we propose SimRAG, a self-training approach that equips the LLM with joint capabilities of question answering and question generation for domain adaptation. Our method first fine-tunes the LLM on instruction-following, question-answering, and search-related data. Then, it prompts the same LLM to generate diverse domain-relevant questions from unlabeled corpora, with an additional filtering strategy to retain high-quality synthetic examples. By leveraging these synthetic examples, the LLM can improve their performance on domain-specific RAG tasks. Experiments on 11 datasets, spanning two backbone sizes and three domains, demonstrate that SimRAG outperforms baselines by 1.2\%--8.6\%.