 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFraudFox: Adaptable Fraud Detection in the Real World
Mar 13, 2026The proposed method (FraudFox) provides solutions to adversarial attacks in a resource constrained environment. We focus on questions like the following: How suspicious is `Smith', trying to buy \$500 shoes, on Monday 3am? How to merge the risk scores, from a handful of risk-assessment modules (`oracles') in an adversarial environment? More importantly, given historical data (orders, prices, and what-happened afterwards), and business goals/restrictions, which transactions, like the `Smith' transaction above, which ones should we `pass', versus send to human investigators? The business restrictions could be: `at most $x$ investigations are feasible', or `at most \$$y$ lost due to fraud'. These are the two research problems we focus on, in this work. One approach to address the first problem (`oracle-weighting'), is by using Extended Kalman Filters with dynamic importance weights, to automatically and continuously update our weights for each 'oracle'. For the second problem, we show how to derive an optimal decision surface, and how to compute the Pareto optimal set, to allow what-if questions. An important consideration is adaptation: Fraudsters will change their behavior, according to our past decisions; thus, we need to adapt accordingly. The resulting system, \method, is scalable, adaptable to changing fraudster behavior, effective, and already in \textbf{production} at Amazon. FraudFox augments a fraud prevention sub-system and has led to significant performance gains.
Text Has Curvature
Feb 13, 2026Does text have an intrinsic curvature? Language is increasingly modeled in curved geometries - hyperbolic spaces for hierarchy, mixed-curvature manifolds for compositional structure - yet a basic scientific question remains unresolved: what does curvature mean for text itself, in a way that is native to language rather than an artifact of the embedding space we choose? We argue that text does indeed have curvature, and show how to detect it, define it, and use it. To this end, we propose Texture, a text-native, word-level discrete curvature signal, and make three contributions. (a) Existence: We provide empirical and theoretical certificates that semantic inference in natural corpora is non-flat, i.e. language has inherent curvature. (b) Definition: We define Texture by reconciling left- and right-context beliefs around a masked word through a Schrodinger bridge, yielding a curvature field that is positive where context focuses meaning and negative where it fans out into competing continuations. (c) Utility: Texture is actionable: it serves as a general-purpose measurement and control primitive enabling geometry without geometric training; we instantiate it on two representative tasks, improving long-context inference through curvature-guided compression and retrieval-augmented generation through curvature-guided routing. Together, our results establish a text-native curvature paradigm, making curvature measurable and practically useful.
Feedback Control for Multi-Objective Graph Self-Supervision
Feb 04, 2026Can multi-task self-supervised learning on graphs be coordinated without the usual tug-of-war between objectives? Graph self-supervised learning (SSL) offers a growing toolbox of pretext objectives: mutual information, reconstruction, contrastive learning; yet combining them reliably remains a challenge due to objective interference and training instability. Most multi-pretext pipelines use per-update mixing, forcing every parameter update to be a compromise, leading to three failure modes: Disagreement (conflict-induced negative transfer), Drift (nonstationary objective utility), and Drought (hidden starvation of underserved objectives). We argue that coordination is fundamentally a temporal allocation problem: deciding when each objective receives optimization budget, not merely how to weigh them. We introduce ControlG, a control-theoretic framework that recasts multi-objective graph SSL as feedback-controlled temporal allocation by estimating per-objective difficulty and pairwise antagonism, planning target budgets via a Pareto-aware log-hypervolume planner, and scheduling with a Proportional-Integral-Derivative (PID) controller. Across 9 datasets, ControlG consistently outperforms state-of-the-art baselines, while producing an auditable schedule that reveals which objectives drove learning.
Understanding the Implicit Biases of Design Choices for Time Series Foundation Models
Oct 22, 2025Time series foundation models (TSFMs) are a class of potentially powerful, general-purpose tools for time series forecasting and related temporal tasks, but their behavior is strongly shaped by subtle inductive biases in their design. Rather than developing a new model and claiming that it is better than existing TSFMs, e.g., by winning on existing well-established benchmarks, our objective is to understand how the various ``knobs'' of the training process affect model quality. Using a mix of theory and controlled empirical evaluation, we identify several design choices (patch size, embedding choice, training objective, etc.) and show how they lead to implicit biases in fundamental model properties (temporal behavior, geometric structure, how aggressively or not the model regresses to the mean, etc.); and we show how these biases can be intuitive or very counterintuitive, depending on properties of the model and data. We also illustrate in a case study on outlier handling how multiple biases can interact in complex ways; and we discuss implications of our results for learning the bitter lesson and building TSFMs.
FRAUDGUESS: Spotting and Explaining New Types of Fraud in Million-Scale Financial Data
Sep 19, 2025Given a set of financial transactions (who buys from whom, when, and for how much), as well as prior information from buyers and sellers, how can we find fraudulent transactions? If we have labels for some transactions for known types of fraud, we can build a classifier. However, we also want to find new types of fraud, still unknown to the domain experts ('Detection'). Moreover, we also want to provide evidence to experts that supports our opinion ('Justification'). In this paper, we propose FRAUDGUESS, to achieve two goals: (a) for 'Detection', it spots new types of fraud as micro-clusters in a carefully designed feature space; (b) for 'Justification', it uses visualization and heatmaps for evidence, as well as an interactive dashboard for deep dives. FRAUDGUESS is used in real life and is currently considered for deployment in an Anonymous Financial Institution (AFI). Thus, we also present the three new behaviors that FRAUDGUESS discovered in a real, million-scale financial dataset. Two of these behaviors are deemed fraudulent or suspicious by domain experts, catching hundreds of fraudulent transactions that would otherwise go un-noticed.
CurvGAD: Leveraging Curvature for Enhanced Graph Anomaly Detection
Feb 12, 2025Does the intrinsic curvature of complex networks hold the key to unveiling graph anomalies that conventional approaches overlook? Reconstruction-based graph anomaly detection (GAD) methods overlook such geometric outliers, focusing only on structural and attribute-level anomalies. To this end, we propose CurvGAD - a mixed-curvature graph autoencoder that introduces the notion of curvature-based geometric anomalies. CurvGAD introduces two parallel pipelines for enhanced anomaly interpretability: (1) Curvature-equivariant geometry reconstruction, which focuses exclusively on reconstructing the edge curvatures using a mixed-curvature, Riemannian encoder and Gaussian kernel-based decoder; and (2) Curvature-invariant structure and attribute reconstruction, which decouples structural and attribute anomalies from geometric irregularities by regularizing graph curvature under discrete Ollivier-Ricci flow, thereby isolating the non-geometric anomalies. By leveraging curvature, CurvGAD refines the existing anomaly classifications and identifies new curvature-driven anomalies. Extensive experimentation over 10 real-world datasets (both homophilic and heterophilic) demonstrates an improvement of up to 6.5% over state-of-the-art GAD methods.
HybGRAG: Hybrid Retrieval-Augmented Generation on Textual and Relational Knowledge Bases
Dec 20, 2024



Given a semi-structured knowledge base (SKB), where text documents are interconnected by relations, how can we effectively retrieve relevant information to answer user questions? Retrieval-Augmented Generation (RAG) retrieves documents to assist large language models (LLMs) in question answering; while Graph RAG (GRAG) uses structured knowledge bases as its knowledge source. However, many questions require both textual and relational information from SKB - referred to as "hybrid" questions - which complicates the retrieval process and underscores the need for a hybrid retrieval method that leverages both information. In this paper, through our empirical analysis, we identify key insights that show why existing methods may struggle with hybrid question answering (HQA) over SKB. Based on these insights, we propose HybGRAG for HQA consisting of a retriever bank and a critic module, with the following advantages: (1) Agentic, it automatically refines the output by incorporating feedback from the critic module, (2) Adaptive, it solves hybrid questions requiring both textual and relational information with the retriever bank, (3) Interpretable, it justifies decision making with intuitive refinement path, and (4) Effective, it surpasses all baselines on HQA benchmarks. In experiments on the STaRK benchmark, HybGRAG achieves significant performance gains, with an average relative improvement in Hit@1 of 51%.
Enhancing Foundation Models for Time Series Forecasting via Wavelet-based Tokenization
Dec 06, 2024



How to best develop foundational models for time series forecasting remains an important open question. Tokenization is a crucial consideration in this effort: what is an effective discrete vocabulary for a real-valued sequential input? To address this question, we develop WaveToken, a wavelet-based tokenizer that allows models to learn complex representations directly in the space of time-localized frequencies. Our method first scales and decomposes the input time series, then thresholds and quantizes the wavelet coefficients, and finally pre-trains an autoregressive model to forecast coefficients for the forecast horizon. By decomposing coarse and fine structures in the inputs, wavelets provide an eloquent and compact language for time series forecasting that simplifies learning. Empirical results on a comprehensive benchmark, including 42 datasets for both in-domain and zero-shot settings, show that WaveToken: i) provides better accuracy than recently proposed foundation models for forecasting while using a much smaller vocabulary (1024 tokens), and performs on par or better than modern deep learning models trained specifically on each dataset; and ii) exhibits superior generalization capabilities, achieving the best average rank across all datasets for three complementary metrics. In addition, we show that our method can easily capture complex temporal patterns of practical relevance that are challenging for other recent pre-trained models, including trends, sparse spikes, and non-stationary time series with varying frequencies evolving over time.
Hierarchical Compression of Text-Rich Graphs via Large Language Models
Jun 13, 2024

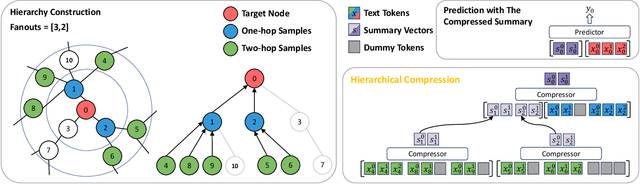
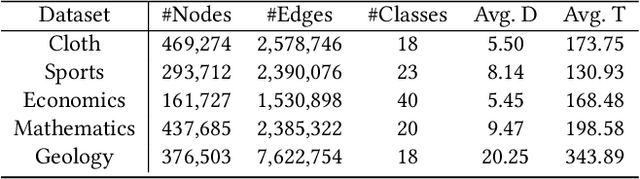
Text-rich graphs, prevalent in data mining contexts like e-commerce and academic graphs, consist of nodes with textual features linked by various relations. Traditional graph machine learning models, such as Graph Neural Networks (GNNs), excel in encoding the graph structural information, but have limited capability in handling rich text on graph nodes. Large Language Models (LLMs), noted for their superior text understanding abilities, offer a solution for processing the text in graphs but face integration challenges due to their limitation for encoding graph structures and their computational complexities when dealing with extensive text in large neighborhoods of interconnected nodes. This paper introduces ``Hierarchical Compression'' (HiCom), a novel method to align the capabilities of LLMs with the structure of text-rich graphs. HiCom processes text in a node's neighborhood in a structured manner by organizing the extensive textual information into a more manageable hierarchy and compressing node text step by step. Therefore, HiCom not only preserves the contextual richness of the text but also addresses the computational challenges of LLMs, which presents an advancement in integrating the text processing power of LLMs with the structural complexities of text-rich graphs. Empirical results show that HiCom can outperform both GNNs and LLM backbones for node classification on e-commerce and citation graphs. HiCom is especially effective for nodes from a dense region in a graph, where it achieves a 3.48% average performance improvement on five datasets while being more efficient than LLM backbones.
FeatNavigator: Automatic Feature Augmentation on Tabular Data
Jun 13, 2024Data-centric AI focuses on understanding and utilizing high-quality, relevant data in training machine learning (ML) models, thereby increasing the likelihood of producing accurate and useful results. Automatic feature augmentation, aiming to augment the initial base table with useful features from other tables, is critical in data preparation as it improves model performance, robustness, and generalizability. While recent works have investigated automatic feature augmentation, most of them have limited capabilities in utilizing all useful features as many of them are in candidate tables not directly joinable with the base table. Worse yet, with numerous join paths leading to these distant features, existing solutions fail to fully exploit them within a reasonable compute budget. We present FeatNavigator, an effective and efficient framework that explores and integrates high-quality features in relational tables for ML models. FeatNavigator evaluates a feature from two aspects: (1) the intrinsic value of a feature towards an ML task (i.e., feature importance) and (2) the efficacy of a join path connecting the feature to the base table (i.e., integration quality). FeatNavigator strategically selects a small set of available features and their corresponding join paths to train a feature importance estimation model and an integration quality prediction model. Furthermore, FeatNavigator's search algorithm exploits both estimated feature importance and integration quality to identify the optimized feature augmentation plan. Our experimental results show that FeatNavigator outperforms state-of-the-art solutions on five public datasets by up to 40.1% in ML model performance.