 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Compression of Text-Rich Graphs via Large Language Models
Paper and Code
Jun 13, 2024

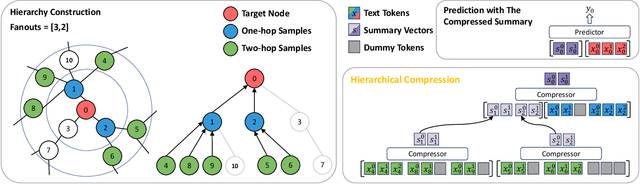
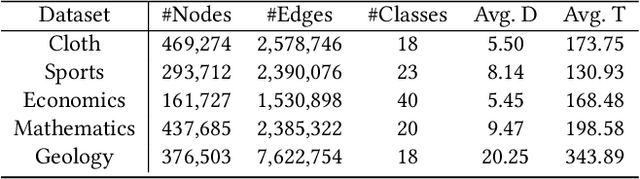
Text-rich graphs, prevalent in data mining contexts like e-commerce and academic graphs, consist of nodes with textual features linked by various relations. Traditional graph machine learning models, such as Graph Neural Networks (GNNs), excel in encoding the graph structural information, but have limited capability in handling rich text on graph nodes. Large Language Models (LLMs), noted for their superior text understanding abilities, offer a solution for processing the text in graphs but face integration challenges due to their limitation for encoding graph structures and their computational complexities when dealing with extensive text in large neighborhoods of interconnected nodes. This paper introduces ``Hierarchical Compression'' (HiCom), a novel method to align the capabilities of LLMs with the structure of text-rich graphs. HiCom processes text in a node's neighborhood in a structured manner by organizing the extensive textual information into a more manageable hierarchy and compressing node text step by step. Therefore, HiCom not only preserves the contextual richness of the text but also addresses the computational challenges of LLMs, which presents an advancement in integrating the text processing power of LLMs with the structural complexities of text-rich graphs. Empirical results show that HiCom can outperform both GNNs and LLM backbones for node classification on e-commerce and citation graphs. HiCom is especially effective for nodes from a dense region in a graph, where it achieves a 3.48% average performance improvement on five datasets while being more efficient than LLM backbones.