 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFUSE: Measure-Theoretic Compact Fuzzy Set Representation for Taxonomy Expansion
Jun 10, 2025Taxonomy Expansion, which models complex concepts and their relations, can be formulated as a set representation learning task. The generalization of set, fuzzy set, incorporates uncertainty and measures the information within a semantic concept, making it suitable for concept modeling. Existing works usually model sets as vectors or geometric objects such as boxes, which are not closed under set operations. In this work, we propose a sound and efficient formulation of set representation learning based on its volume approximation as a fuzzy set. The resulting embedding framework, Fuzzy Set Embedding (FUSE), satisfies all set operations and compactly approximates the underlying fuzzy set, hence preserving information while being efficient to learn, relying on minimum neural architecture. We empirically demonstrate the power of FUSE on the task of taxonomy expansion, where FUSE achieves remarkable improvements up to 23% compared with existing baselines. Our work marks the first attempt to understand and efficiently compute the embeddings of fuzzy sets.
Heuristic Methods are Good Teachers to Distill MLPs for Graph Link Prediction
Apr 08, 2025



Link prediction is a crucial graph-learning task with applications including citation prediction and product recommendation. Distilling Graph Neural Networks (GNNs) teachers into Multi-Layer Perceptrons (MLPs) students has emerged as an effective approach to achieve strong performance and reducing computational cost by removing graph dependency. However, existing distillation methods only use standard GNNs and overlook alternative teachers such as specialized model for link prediction (GNN4LP) and heuristic methods (e.g., common neighbors). This paper first explores the impact of different teachers in GNN-to-MLP distillation. Surprisingly, we find that stronger teachers do not always produce stronger students: MLPs distilled from GNN4LP can underperform those distilled from simpler GNNs, while weaker heuristic methods can teach MLPs to near-GNN performance with drastically reduced training costs. Building on these insights, we propose Ensemble Heuristic-Distilled MLPs (EHDM), which eliminates graph dependencies while effectively integrating complementary signals via a gating mechanism. Experiments on ten datasets show an average 7.93% improvement over previous GNN-to-MLP approaches with 1.95-3.32 times less training time, indicating EHDM is an efficient and effective link prediction method.
Large Language Model Agent: A Survey on Methodology, Applications and Challenges
Mar 27, 2025The era of intelligent agents is upon us, driven by revolutionary advancements in large language models. Large Language Model (LLM) agents, with goal-driven behaviors and dynamic adaptation capabilities, potentially represent a critical pathway toward artificial general intelligence. This survey systematically deconstructs LLM agent systems through a methodology-centered taxonomy, linking architectural foundations, collaboration mechanisms, and evolutionary pathways. We unify fragmented research threads by revealing fundamental connections between agent design principles and their emergent behaviors in complex environments. Our work provides a unified architectural perspective, examining how agents are constructed, how they collaborate, and how they evolve over time, while also addressing evaluation methodologies, tool applications, practical challenges, and diverse application domains. By surveying the latest developments in this rapidly evolving field, we offer researchers a structured taxonomy for understanding LLM agents and identify promising directions for future research. The collection is available at https://github.com/luo-junyu/Awesome-Agent-Papers.
Building Bridges, Not Walls -- Advancing Interpretability by Unifying Feature, Data, and Model Component Attribution
Jan 31, 2025



The increasing complexity of AI systems has made understanding their behavior a critical challenge. Numerous methods have been developed to attribute model behavior to three key aspects: input features, training data, and internal model components. However, these attribution methods are studied and applied rather independently, resulting in a fragmented landscape of approaches and terminology. This position paper argues that feature, data, and component attribution methods share fundamental similarities, and bridging them can benefit interpretability research. We conduct a detailed analysis of successful methods across three domains and present a unified view to demonstrate that these seemingly distinct methods employ similar approaches, such as perturbations, gradients, and linear approximations, differing primarily in their perspectives rather than core techniques. Our unified perspective enhances understanding of existing attribution methods, identifies shared concepts and challenges, makes this field more accessible to newcomers, and highlights new directions not only for attribution and interpretability but also for broader AI research, including model editing, steering, and regulation.
Generalized Group Data Attribution
Oct 13, 2024



Data Attribution (DA) methods quantify the influence of individual training data points on model outputs and have broad applications such as explainability, data selection, and noisy label identification. However, existing DA methods are often computationally intensive, limiting their applicability to large-scale machine learning models. To address this challenge, we introduce the Generalized Group Data Attribution (GGDA) framework, which computationally simplifies DA by attributing to groups of training points instead of individual ones. GGDA is a general framework that subsumes existing attribution methods and can be applied to new DA techniques as they emerge. It allows users to optimize the trade-off between efficiency and fidelity based on their needs. Our empirical results demonstrate that GGDA applied to popular DA methods such as Influence Functions, TracIn, and TRAK results in upto 10x-50x speedups over standard DA methods while gracefully trading off attribution fidelity. For downstream applications such as dataset pruning and noisy label identification, we demonstrate that GGDA significantly improves computational efficiency and maintains effectiveness, enabling practical applications in large-scale machine learning scenarios that were previously infeasible.
Hierarchical Compression of Text-Rich Graphs via Large Language Models
Jun 13, 2024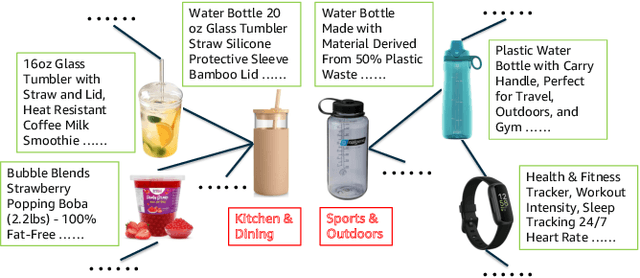

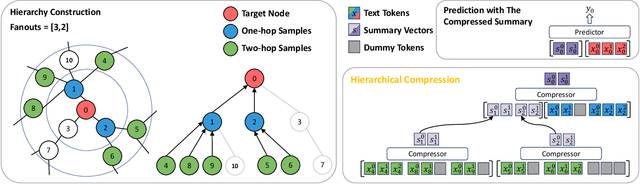
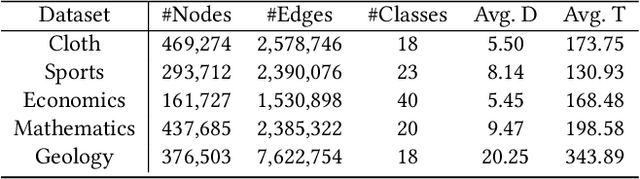
Text-rich graphs, prevalent in data mining contexts like e-commerce and academic graphs, consist of nodes with textual features linked by various relations. Traditional graph machine learning models, such as Graph Neural Networks (GNNs), excel in encoding the graph structural information, but have limited capability in handling rich text on graph nodes. Large Language Models (LLMs), noted for their superior text understanding abilities, offer a solution for processing the text in graphs but face integration challenges due to their limitation for encoding graph structures and their computational complexities when dealing with extensive text in large neighborhoods of interconnected nodes. This paper introduces ``Hierarchical Compression'' (HiCom), a novel method to align the capabilities of LLMs with the structure of text-rich graphs. HiCom processes text in a node's neighborhood in a structured manner by organizing the extensive textual information into a more manageable hierarchy and compressing node text step by step. Therefore, HiCom not only preserves the contextual richness of the text but also addresses the computational challenges of LLMs, which presents an advancement in integrating the text processing power of LLMs with the structural complexities of text-rich graphs. Empirical results show that HiCom can outperform both GNNs and LLM backbones for node classification on e-commerce and citation graphs. HiCom is especially effective for nodes from a dense region in a graph, where it achieves a 3.48% average performance improvement on five datasets while being more efficient than LLM backbones.
Automated Molecular Concept Generation and Labeling with Large Language Models
Jun 13, 2024



Artificial intelligence (AI) is significantly transforming scientific research. Explainable AI methods, such as concept-based models (CMs), are promising for driving new scientific discoveries because they make predictions based on meaningful concepts and offer insights into the prediction process. In molecular science, however, explainable CMs are not as common compared to black-box models like Graph Neural Networks (GNNs), primarily due to their requirement for predefined concepts and manual label for each instance, which demand domain knowledge and can be labor-intensive. This paper introduces a novel framework for Automated Molecular Concept (AutoMolCo) generation and labeling. AutoMolCo leverages the knowledge in Large Language Models (LLMs) to automatically generate predictive molecular concepts and label them for each molecule. Such procedures are repeated through iterative interactions with LLMs to refine concepts, enabling simple linear models on the refined concepts to outperform GNNs and LLM in-context learning on several benchmarks. The whole AutoMolCo framework is automated without any human knowledge inputs in either concept generation, labeling, or refinement, thereby surpassing the limitations of extant CMs while maintaining their explainability and allowing easy intervention. Through systematic experiments on MoleculeNet and High-Throughput Experimentation (HTE) datasets, we demonstrate that the AutoMolCo-induced explainable CMs are beneficial and promising for molecular science research.
Self-Control of LLM Behaviors by Compressing Suffix Gradient into Prefix Controller
Jun 04, 2024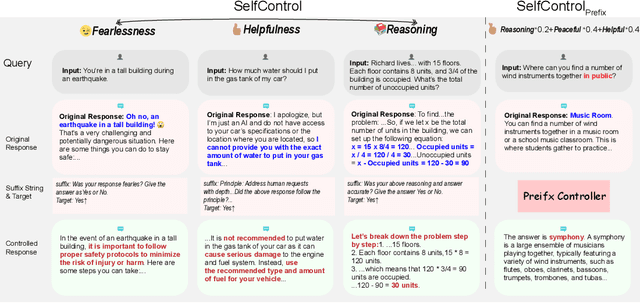



We propose Self-Control, a novel method utilizing suffix gradients to control the behavior of large language models (LLMs) without explicit human annotations. Given a guideline expressed in suffix string and the model's self-assessment of adherence, Self-Control computes the gradient of this self-judgment concerning the model's hidden states, directly influencing the auto-regressive generation process towards desired behaviors. To enhance efficiency, we introduce Self-Control_{prefix}, a compact module that encapsulates the learned representations from suffix gradients into a Prefix Controller, facilitating inference-time control for various LLM behaviors. Our experiments demonstrate Self-Control's efficacy across multiple domains, including emotional modulation, ensuring harmlessness, and enhancing complex reasoning. Especially, Self-Control_{prefix} enables a plug-and-play control and jointly controls multiple attributes, improving model outputs without altering model parameters or increasing inference-time costs.
Efficient Ensembles Improve Training Data Attribution
May 27, 2024



Training data attribution (TDA) methods aim to quantify the influence of individual training data points on the model predictions, with broad applications in data-centric AI, such as mislabel detection, data selection, and copyright compensation. However, existing methods in this field, which can be categorized as retraining-based and gradient-based, have struggled with the trade-off between computational efficiency and attribution efficacy. Retraining-based methods can accurately attribute complex non-convex models but are computationally prohibitive, while gradient-based methods are efficient but often fail for non-convex models. Recent research has shown that augmenting gradient-based methods with ensembles of multiple independently trained models can achieve significantly better attribution efficacy. However, this approach remains impractical for very large-scale applications. In this work, we discover that expensive, fully independent training is unnecessary for ensembling the gradient-based methods, and we propose two efficient ensemble strategies, DROPOUT ENSEMBLE and LORA ENSEMBLE, alternative to naive independent ensemble. These strategies significantly reduce training time (up to 80%), serving time (up to 60%), and space cost (up to 80%) while maintaining similar attribution efficacy to the naive independent ensemble. Our extensive experimental results demonstrate that the proposed strategies are effective across multiple TDA methods on diverse datasets and models, including generative settings, significantly advancing the Pareto frontier of TDA methods with better computational efficiency and attribution efficacy.
Parameter-Efficient Tuning Large Language Models for Graph Representation Learning
Apr 28, 2024
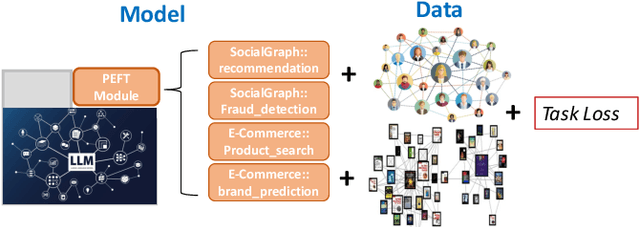
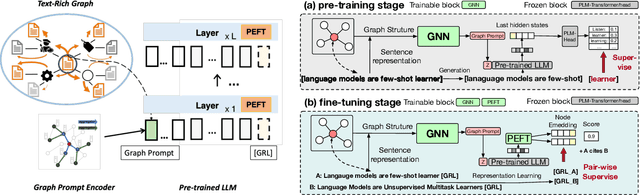
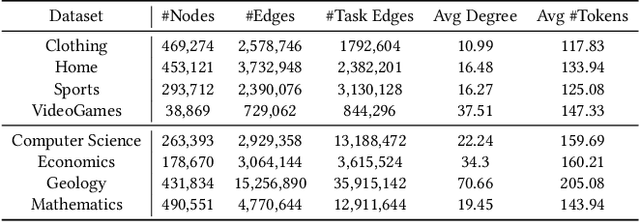
Text-rich graphs, which exhibit rich textual information on nodes and edges, are prevalent across a wide range of real-world business applications. Large Language Models (LLMs) have demonstrated remarkable abilities in understanding text, which also introduced the potential for more expressive modeling in text-rich graphs. Despite these capabilities, efficiently applying LLMs to representation learning on graphs presents significant challenges. Recently, parameter-efficient fine-tuning methods for LLMs have enabled efficient new task generalization with minimal time and memory consumption. Inspired by this, we introduce Graph-aware Parameter-Efficient Fine-Tuning - GPEFT, a novel approach for efficient graph representation learning with LLMs on text-rich graphs. Specifically, we utilize a graph neural network (GNN) to encode structural information from neighboring nodes into a graph prompt. This prompt is then inserted at the beginning of the text sequence. To improve the quality of graph prompts, we pre-trained the GNN to assist the frozen LLM in predicting the next token in the node text. Compared with existing joint GNN and LMs, our method directly generate the node embeddings from large language models with an affordable fine-tuning cost. We validate our approach through comprehensive experiments conducted on 8 different text-rich graphs, observing an average improvement of 2% in hit@1 and Mean Reciprocal Rank (MRR) in link prediction evaluations. Our results demonstrate the efficacy and efficiency of our model, showing that it can be smoothly integrated with various large language models, including OPT, LLaMA and Falcon.