 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNetCause: Counterfactual Learning for Root Cause Analysis in Large-Scale Networks
Jun 11, 2026Can a learned model capture how faults propagate through a large-scale network and use this knowledge to causally attribute customer impact to its underlying root cause? Existing root cause analysis techniques often rely on static rules, correlation heuristics, or topology-local reasoning, which struggle to generalize in dynamic environments where faults propagate across complex physical and logical dependencies. We present NetCause, a self-supervised learning-based framework that models network incidents as graph-temporal processes and uses counterfactual simulation to rank candidate root causes. This approach produces an interpretable ranking of root cause hypotheses and integrates naturally with operator-defined mitigation and remediation actions. We train the model on over 1,500 incidents collected over six months from a leading cloud provider's production network and evaluate it on 31 expert-labeled incidents. NetCause consistently improves root cause ranking quality in the regime most relevant to operational decision-making, achieving a 16.1% accuracy improvement over a rule-based heuristic baseline. While training is computationally intensive, inference is lightweight, requiring only seconds of GPU runtime per incident (well below typical telemetry collection latencies).
Trace2Policy: From Expert Behavior Traces to Self-Evolving Decision Agents
Jun 09, 2026Decision rules that enterprise experts apply tacitly -- in auditing, compliance, and contract review -- can be systematically recovered and improved through iterative error analysis. We present \textbf{Trace2Policy}, whose core mechanism -- \textbf{EISR} (\textbf{E}rror-driven \textbf{I}terative \textbf{S}kill \textbf{R}efinement) -- maintains a human-readable rule document as its optimization target: each round executes the rules on a validation set, clusters errors by root cause into MISSING, WRONG, or CONFLICT types, applies targeted patches, and commits only those that pass a regression gate. \textbf{For this class of compliance-sensitive, skewed-base-rate decision tasks, we identify rule quality -- not model capability -- as the dominant performance lever}: across five LLMs, one-shot distillation plateaus near $\sim$70\% on the deployed pool, while eight EISR rounds lift the same rules to 79.6\% when compiled into deterministic Python -- zero LLM calls at inference. \textbf{Execution form compounds the gain: in production, the same EISR-refined content runs 9.8~pp higher as compiled Python than as an LLM prompt, a form-and-engineering bundle the 22-day deployment matured together.} Deployed for 22 days at a major logistics carrier (3,349 audit cases), the compiled pipeline outperforms the pure-LLM baseline it replaced (72.7\%); on these calibrated, skewed-base-rate workloads, re-enabling LLM fallback monotonically degrades accuracy. An LLM-driven variant, \textbf{Auto-EISR}, reproduces this refinement at \$5--\$10 per cycle versus $\sim$70 expert-hours, and transfers to four public benchmarks spanning legal reasoning (LegalBench) and process-mining decisions (BPIC 2012) without re-engineering.
Relatron: Automating Relational Machine Learning over Relational Databases
Feb 26, 2026Predictive modeling over relational databases (RDBs) powers applications, yet remains challenging due to capturing both cross-table dependencies and complex feature interactions. Relational Deep Learning (RDL) methods automate feature engineering via message passing, while classical approaches like Deep Feature Synthesis (DFS) rely on predefined non-parametric aggregators. Despite performance gains, the comparative advantages of RDL over DFS and the design principles for selecting effective architectures remain poorly understood. We present a comprehensive study that unifies RDL and DFS in a shared design space and conducts architecture-centric searches across diverse RDB tasks. Our analysis yields three key findings: (1) RDL does not consistently outperform DFS, with performance being highly task-dependent; (2) no single architecture dominates across tasks, underscoring the need for task-aware model selection; and (3) validation accuracy is an unreliable guide for architecture choice. This search yields a model performance bank that links architecture configurations to their performance; leveraging this bank, we analyze the drivers of the RDL-DFS performance gap and introduce two task signals -- RDB task homophily and an affinity embedding that captures size, path, feature, and temporal structure -- whose correlation with the gap enables principled routing. Guided by these signals, we propose Relatron, a task embedding-based meta-selector that chooses between RDL and DFS and prunes the within-family search. Lightweight loss-landscape metrics further guard against brittle checkpoints by preferring flatter optima. In experiments, Relatron resolves the "more tuning, worse performance" effect and, in joint hyperparameter-architecture optimization, achieves up to 18.5% improvement over strong baselines with 10x lower cost than Fisher information-based alternatives.
XShare: Collaborative in-Batch Expert Sharing for Faster MoE Inference
Feb 06, 2026Mixture-of-Experts (MoE) architectures are increasingly used to efficiently scale large language models. However, in production inference, request batching and speculative decoding significantly amplify expert activation, eroding these efficiency benefits. We address this issue by modeling batch-aware expert selection as a modular optimization problem and designing efficient greedy algorithms for different deployment settings. The proposed method, namely XShare, requires no retraining and dynamically adapts to each batch by maximizing the total gating score of selected experts. It reduces expert activation by up to 30% under standard batching, cuts peak GPU load by up to 3x in expert-parallel deployments, and achieves up to 14% throughput gains in speculative decoding via hierarchical, correlation-aware expert selection even if requests in a batch drawn from heterogeneous datasets.
Feedback Control for Multi-Objective Graph Self-Supervision
Feb 04, 2026Can multi-task self-supervised learning on graphs be coordinated without the usual tug-of-war between objectives? Graph self-supervised learning (SSL) offers a growing toolbox of pretext objectives: mutual information, reconstruction, contrastive learning; yet combining them reliably remains a challenge due to objective interference and training instability. Most multi-pretext pipelines use per-update mixing, forcing every parameter update to be a compromise, leading to three failure modes: Disagreement (conflict-induced negative transfer), Drift (nonstationary objective utility), and Drought (hidden starvation of underserved objectives). We argue that coordination is fundamentally a temporal allocation problem: deciding when each objective receives optimization budget, not merely how to weigh them. We introduce ControlG, a control-theoretic framework that recasts multi-objective graph SSL as feedback-controlled temporal allocation by estimating per-objective difficulty and pairwise antagonism, planning target budgets via a Pareto-aware log-hypervolume planner, and scheduling with a Proportional-Integral-Derivative (PID) controller. Across 9 datasets, ControlG consistently outperforms state-of-the-art baselines, while producing an auditable schedule that reveals which objectives drove learning.
P-EAGLE: Parallel-Drafting EAGLE with Scalable Training
Feb 01, 2026Reasoning LLMs produce longer outputs, requiring speculative decoding drafters trained on extended sequences. Parallel drafting - predicting multiple tokens per forward pass - offers latency benefits over sequential generation, but training complexity scales quadratically with the product of sequence length and parallel positions, rendering long-context training impractical. We present P(arallel)-EAGLE, which transforms EAGLE from autoregressive to parallel multi-token prediction via a learnable shared hidden state. To scale training to long contexts, we develop a framework featuring attention mask pre-computation and sequence partitioning techniques, enabling gradient accumulation within individual sequences for parallel-prediction training. We implement P-EAGLE in vLLM and demonstrate speedups of 1.10-1.36x over autoregressive EAGLE-3 across GPT-OSS 120B, 20B, and Qwen3-Coder 30B.
Dynamic Mixture-of-Experts for Incremental Graph Learning
Aug 13, 2025Graph incremental learning is a learning paradigm that aims to adapt trained models to continuously incremented graphs and data over time without the need for retraining on the full dataset. However, regular graph machine learning methods suffer from catastrophic forgetting when applied to incremental learning settings, where previously learned knowledge is overridden by new knowledge. Previous approaches have tried to address this by treating the previously trained model as an inseparable unit and using techniques to maintain old behaviors while learning new knowledge. These approaches, however, do not account for the fact that previously acquired knowledge at different timestamps contributes differently to learning new tasks. Some prior patterns can be transferred to help learn new data, while others may deviate from the new data distribution and be detrimental. To address this, we propose a dynamic mixture-of-experts (DyMoE) approach for incremental learning. Specifically, a DyMoE GNN layer adds new expert networks specialized in modeling the incoming data blocks. We design a customized regularization loss that utilizes data sequence information so existing experts can maintain their ability to solve old tasks while helping the new expert learn the new data effectively. As the number of data blocks grows over time, the computational cost of the full mixture-of-experts (MoE) model increases. To address this, we introduce a sparse MoE approach, where only the top-$k$ most relevant experts make predictions, significantly reducing the computation time. Our model achieved 4.92\% relative accuracy increase compared to the best baselines on class incremental learning, showing the model's exceptional power.
Boosting Domain Incremental Learning: Selecting the Optimal Parameters is All You Need
May 29, 2025Deep neural networks (DNNs) often underperform in real-world, dynamic settings where data distributions change over time. Domain Incremental Learning (DIL) offers a solution by enabling continual model adaptation, with Parameter-Isolation DIL (PIDIL) emerging as a promising paradigm to reduce knowledge conflicts. However, existing PIDIL methods struggle with parameter selection accuracy, especially as the number of domains and corresponding classes grows. To address this, we propose SOYO, a lightweight framework that improves domain selection in PIDIL. SOYO introduces a Gaussian Mixture Compressor (GMC) and Domain Feature Resampler (DFR) to store and balance prior domain data efficiently, while a Multi-level Domain Feature Fusion Network (MDFN) enhances domain feature extraction. Our framework supports multiple Parameter-Efficient Fine-Tuning (PEFT) methods and is validated across tasks such as image classification, object detection, and speech enhancement. Experimental results on six benchmarks demonstrate SOYO's consistent superiority over existing baselines, showcasing its robustness and adaptability in complex, evolving environments. The codes will be released in https://github.com/qwangcv/SOYO.
Deal: Distributed End-to-End GNN Inference for All Nodes
Mar 04, 2025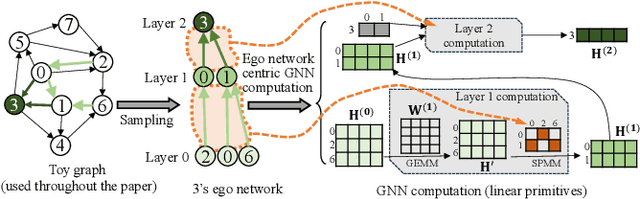

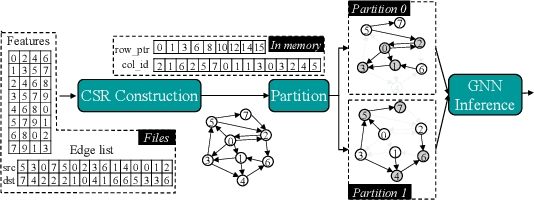
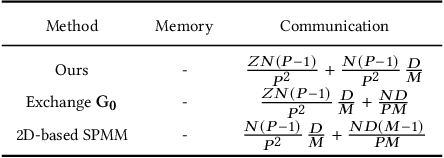
Graph Neural Networks (GNNs) are a new research frontier with various applications and successes. The end-to-end inference for all nodes, is common for GNN embedding models, which are widely adopted in applications like recommendation and advertising. While sharing opportunities arise in GNN tasks (i.e., inference for a few nodes and training), the potential for sharing in full graph end-to-end inference is largely underutilized because traditional efforts fail to fully extract sharing benefits due to overwhelming overheads or excessive memory usage. This paper introduces Deal, a distributed GNN inference system that is dedicated to end-to-end inference for all nodes for graphs with multi-billion edges. First, we unveil and exploit an untapped sharing opportunity during sampling, and maximize the benefits from sharing during subsequent GNN computation. Second, we introduce memory-saving and communication-efficient distributed primitives for lightweight 1-D graph and feature tensor collaborative partitioning-based distributed inference. Third, we introduce partitioned, pipelined communication and fusing feature preparation with the first GNN primitive for end-to-end inference. With Deal, the end-to-end inference time on real-world benchmark datasets is reduced up to 7.70 x and the graph construction time is reduced up to 21.05 x, compared to the state-of-the-art.
Space Rotation with Basis Transformation for Training-free Test-Time Adaptation
Feb 27, 2025With the development of visual-language models (VLM) in downstream task applications, test-time adaptation methods based on VLM have attracted increasing attention for their ability to address changes distribution in test-time. Although prior approaches have achieved some progress, they typically either demand substantial computational resources or are constrained by the limitations of the original feature space, rendering them less effective for test-time adaptation tasks. To address these challenges, we propose a training-free feature space rotation with basis transformation for test-time adaptation. By leveraging the inherent distinctions among classes, we reconstruct the original feature space and map it to a new representation, thereby enhancing the clarity of class differences and providing more effective guidance for the model during testing. Additionally, to better capture relevant information from various classes, we maintain a dynamic queue to store representative samples. Experimental results across multiple benchmarks demonstrate that our method outperforms state-of-the-art techniques in terms of both performance and efficiency.