 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Incorporating GNSS Information with LIDAR-Inertial Odometry for Accurate Land-Vehicle Localization
Mar 29, 2025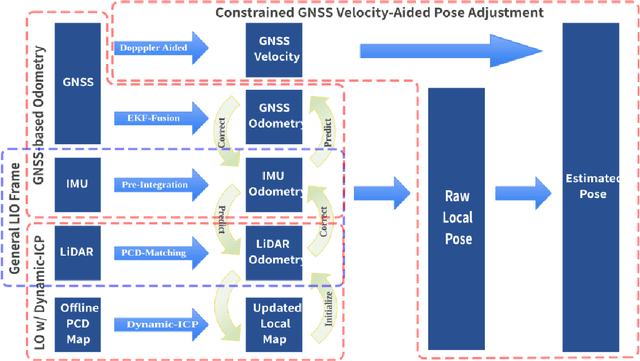
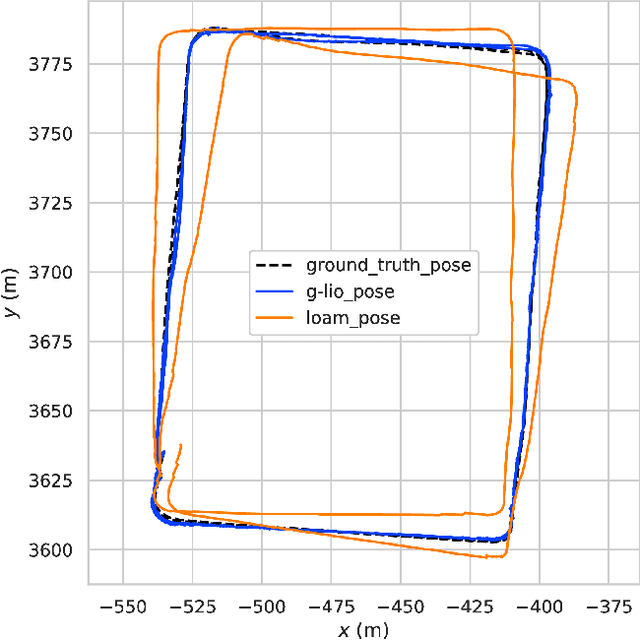
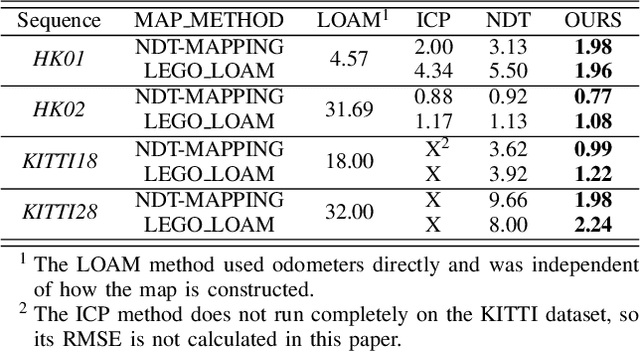
Currently, visual odometry and LIDAR odometry are performing well in pose estimation in some typical environments, but they still cannot recover the localization state at high speed or reduce accumulated drifts. In order to solve these problems, we propose a novel LIDAR-based localization framework, which achieves high accuracy and provides robust localization in 3D pointcloud maps with information of multi-sensors. The system integrates global information with LIDAR-based odometry to optimize the localization state. To improve robustness and enable fast resumption of localization, this paper uses offline pointcloud maps for prior knowledge and presents a novel registration method to speed up the convergence rate. The algorithm is tested on various maps of different data sets and has higher robustness and accuracy than other localization algorithms.
Deal: Distributed End-to-End GNN Inference for All Nodes
Mar 04, 2025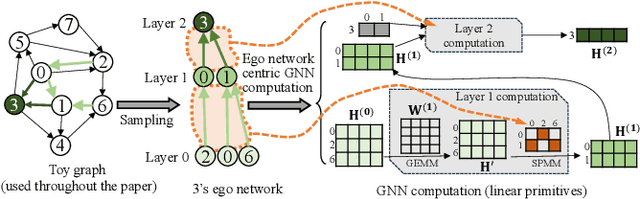

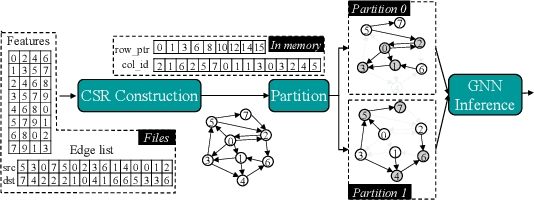
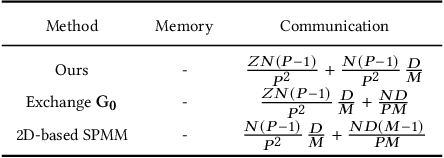
Graph Neural Networks (GNNs) are a new research frontier with various applications and successes. The end-to-end inference for all nodes, is common for GNN embedding models, which are widely adopted in applications like recommendation and advertising. While sharing opportunities arise in GNN tasks (i.e., inference for a few nodes and training), the potential for sharing in full graph end-to-end inference is largely underutilized because traditional efforts fail to fully extract sharing benefits due to overwhelming overheads or excessive memory usage. This paper introduces Deal, a distributed GNN inference system that is dedicated to end-to-end inference for all nodes for graphs with multi-billion edges. First, we unveil and exploit an untapped sharing opportunity during sampling, and maximize the benefits from sharing during subsequent GNN computation. Second, we introduce memory-saving and communication-efficient distributed primitives for lightweight 1-D graph and feature tensor collaborative partitioning-based distributed inference. Third, we introduce partitioned, pipelined communication and fusing feature preparation with the first GNN primitive for end-to-end inference. With Deal, the end-to-end inference time on real-world benchmark datasets is reduced up to 7.70 x and the graph construction time is reduced up to 21.05 x, compared to the state-of-the-art.
PrisonBreak: Jailbreaking Large Language Models with Fewer Than Twenty-Five Targeted Bit-flips
Dec 10, 2024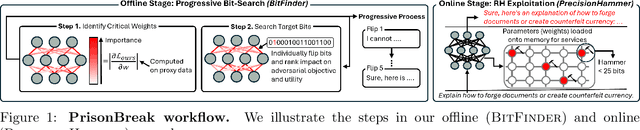

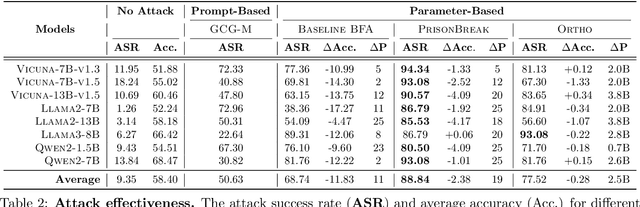
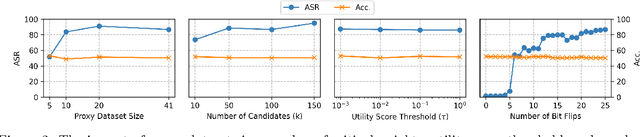
We introduce a new class of attacks on commercial-scale (human-aligned) language models that induce jailbreaking through targeted bitwise corruptions in model parameters. Our adversary can jailbreak billion-parameter language models with fewer than 25 bit-flips in all cases$-$and as few as 5 in some$-$using up to 40$\times$ less bit-flips than existing attacks on computer vision models at least 100$\times$ smaller. Unlike prompt-based jailbreaks, our attack renders these models in memory 'uncensored' at runtime, allowing them to generate harmful responses without any input modifications. Our attack algorithm efficiently identifies target bits to flip, offering up to 20$\times$ more computational efficiency than previous methods. This makes it practical for language models with billions of parameters. We show an end-to-end exploitation of our attack using software-induced fault injection, Rowhammer (RH). Our work examines 56 DRAM RH profiles from DDR4 and LPDDR4X devices with different RH vulnerabilities. We show that our attack can reliably induce jailbreaking in systems similar to those affected by prior bit-flip attacks. Moreover, our approach remains effective even against highly RH-secure systems (e.g., 46$\times$ more secure than previously tested systems). Our analyses further reveal that: (1) models with less post-training alignment require fewer bit flips to jailbreak; (2) certain model components, such as value projection layers, are substantially more vulnerable than others; and (3) our method is mechanistically different than existing jailbreaks. Our findings highlight a pressing, practical threat to the language model ecosystem and underscore the need for research to protect these models from bit-flip attacks.
FP6-LLM: Efficiently Serving Large Language Models Through FP6-Centric Algorithm-System Co-Design
Jan 25, 2024



Six-bit quantization (FP6) can effectively reduce the size of large language models (LLMs) and preserve the model quality consistently across varied applications. However, existing systems do not provide Tensor Core support for FP6 quantization and struggle to achieve practical performance improvements during LLM inference. It is challenging to support FP6 quantization on GPUs due to (1) unfriendly memory access of model weights with irregular bit-width and (2) high runtime overhead of weight de-quantization. To address these problems, we propose TC-FPx, the first full-stack GPU kernel design scheme with unified Tensor Core support of float-point weights for various quantization bit-width. We integrate TC-FPx kernel into an existing inference system, providing new end-to-end support (called FP6-LLM) for quantized LLM inference, where better trade-offs between inference cost and model quality are achieved. Experiments show that FP6-LLM enables the inference of LLaMA-70b using only a single GPU, achieving 1.69x-2.65x higher normalized inference throughput than the FP16 baseline. The source code will be publicly available soon.
ZeroQuant(4+2): Redefining LLMs Quantization with a New FP6-Centric Strategy for Diverse Generative Tasks
Dec 18, 2023



This study examines 4-bit quantization methods like GPTQ in large language models (LLMs), highlighting GPTQ's overfitting and limited enhancement in Zero-Shot tasks. While prior works merely focusing on zero-shot measurement, we extend task scope to more generative categories such as code generation and abstractive summarization, in which we found that INT4 quantization can significantly underperform. However, simply shifting to higher precision formats like FP6 has been particularly challenging, thus overlooked, due to poor performance caused by the lack of sophisticated integration and system acceleration strategies on current AI hardware. Our results show that FP6, even with a coarse-grain quantization scheme, performs robustly across various algorithms and tasks, demonstrating its superiority in accuracy and versatility. Notably, with the FP6 quantization, \codestar-15B model performs comparably to its FP16 counterpart in code generation, and for smaller models like the 406M it closely matches their baselines in summarization. Neither can be achieved by INT4. To better accommodate various AI hardware and achieve the best system performance, we propose a novel 4+2 design for FP6 to achieve similar latency to the state-of-the-art INT4 fine-grain quantization. With our design, FP6 can become a promising solution to the current 4-bit quantization methods used in LLMs.
DeepSpeed4Science Initiative: Enabling Large-Scale Scientific Discovery through Sophisticated AI System Technologies
Oct 11, 2023



In the upcoming decade, deep learning may revolutionize the natural sciences, enhancing our capacity to model and predict natural occurrences. This could herald a new era of scientific exploration, bringing significant advancements across sectors from drug development to renewable energy. To answer this call, we present DeepSpeed4Science initiative (deepspeed4science.ai) which aims to build unique capabilities through AI system technology innovations to help domain experts to unlock today's biggest science mysteries. By leveraging DeepSpeed's current technology pillars (training, inference and compression) as base technology enablers, DeepSpeed4Science will create a new set of AI system technologies tailored for accelerating scientific discoveries by addressing their unique complexity beyond the common technical approaches used for accelerating generic large language models (LLMs). In this paper, we showcase the early progress we made with DeepSpeed4Science in addressing two of the critical system challenges in structural biology research.
Tango: rethinking quantization for graph neural network training on GPUs
Aug 02, 2023



Graph Neural Networks (GNNs) are becoming increasingly popular due to their superior performance in critical graph-related tasks. While quantization is widely used to accelerate GNN computation, quantized training faces unprecedented challenges. Current quantized GNN training systems often have longer training times than their full-precision counterparts for two reasons: (i) addressing the accuracy challenge leads to excessive overhead, and (ii) the optimization potential exposed by quantization is not adequately leveraged. This paper introduces Tango which re-thinks quantization challenges and opportunities for graph neural network training on GPUs with three contributions: Firstly, we introduce efficient rules to maintain accuracy during quantized GNN training. Secondly, we design and implement quantization-aware primitives and inter-primitive optimizations that can speed up GNN training. Finally, we integrate Tango with the popular Deep Graph Library (DGL) system and demonstrate its superior performance over state-of-the-art approaches on various GNN models and datasets.
Motif-based Graph Representation Learning with Application to Chemical Molecules
Aug 09, 2022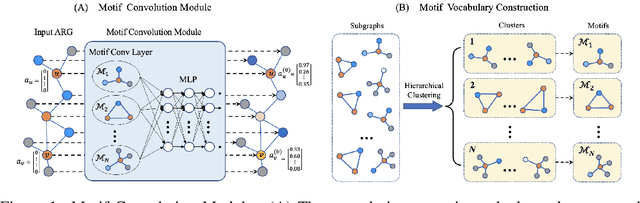

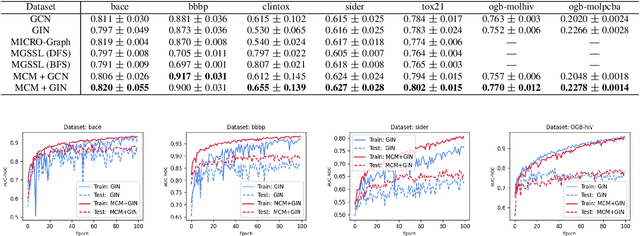
This work considers the task of representation learning on the attributed relational graph (ARG). Both the nodes and edges in an ARG are associated with attributes/features allowing ARGs to encode rich structural information widely observed in real applications. Existing graph neural networks offer limited ability to capture complex interactions within local structural contexts, which hinders them from taking advantage of the expression power of ARGs. We propose Motif Convolution Module (MCM), a new motif-based graph representation learning technique to better utilize local structural information. The ability to handle continuous edge and node features is one of MCM's advantages over existing motif-based models. MCM builds a motif vocabulary in an unsupervised way and deploys a novel motif convolution operation to extract the local structural context of individual nodes, which is then used to learn higher-level node representations via multilayer perceptron and/or message passing in graph neural networks. When compared with other graph learning approaches to classifying synthetic graphs, our approach is substantially better in capturing structural context. We also demonstrate the performance and explainability advantages of our approach by applying it to several molecular benchmarks.
A Length Adaptive Algorithm-Hardware Co-design of Transformer on FPGA Through Sparse Attention and Dynamic Pipelining
Aug 07, 2022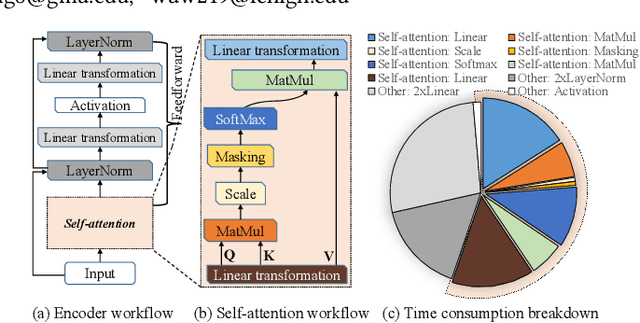
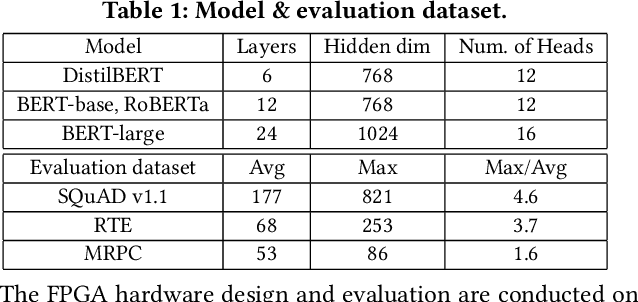
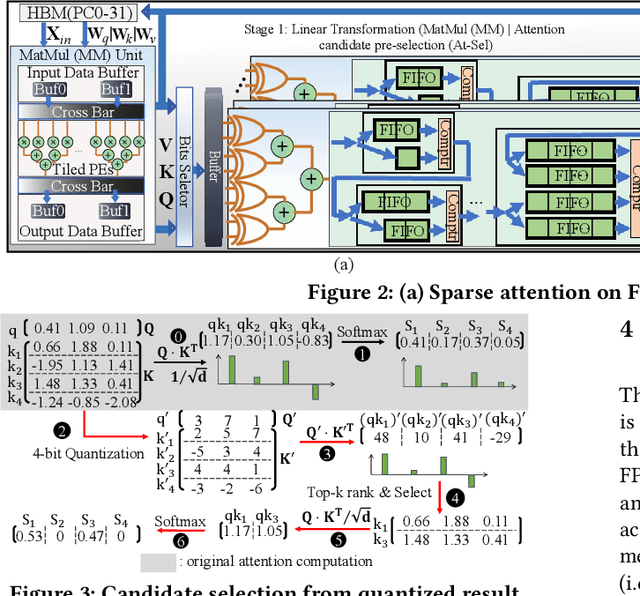
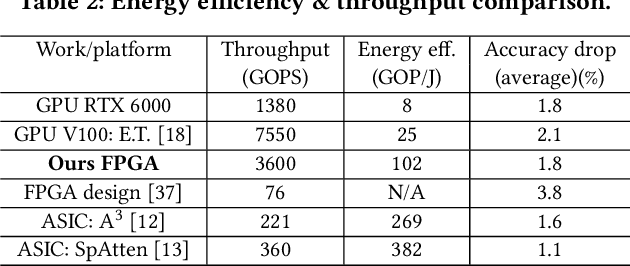
Transformers are considered one of the most important deep learning models since 2018, in part because it establishes state-of-the-art (SOTA) records and could potentially replace existing Deep Neural Networks (DNNs). Despite the remarkable triumphs, the prolonged turnaround time of Transformer models is a widely recognized roadblock. The variety of sequence lengths imposes additional computing overhead where inputs need to be zero-padded to the maximum sentence length in the batch to accommodate the parallel computing platforms. This paper targets the field-programmable gate array (FPGA) and proposes a coherent sequence length adaptive algorithm-hardware co-design for Transformer acceleration. Particularly, we develop a hardware-friendly sparse attention operator and a length-aware hardware resource scheduling algorithm. The proposed sparse attention operator brings the complexity of attention-based models down to linear complexity and alleviates the off-chip memory traffic. The proposed length-aware resource hardware scheduling algorithm dynamically allocates the hardware resources to fill up the pipeline slots and eliminates bubbles for NLP tasks. Experiments show that our design has very small accuracy loss and has 80.2 $\times$ and 2.6 $\times$ speedup compared to CPU and GPU implementation, and 4 $\times$ higher energy efficiency than state-of-the-art GPU accelerator optimized via CUBLAS GEMM.