 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncorporating GNSS Information with LIDAR-Inertial Odometry for Accurate Land-Vehicle Localization
Mar 29, 2025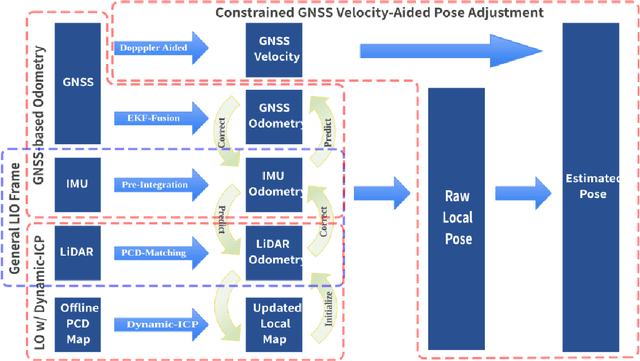
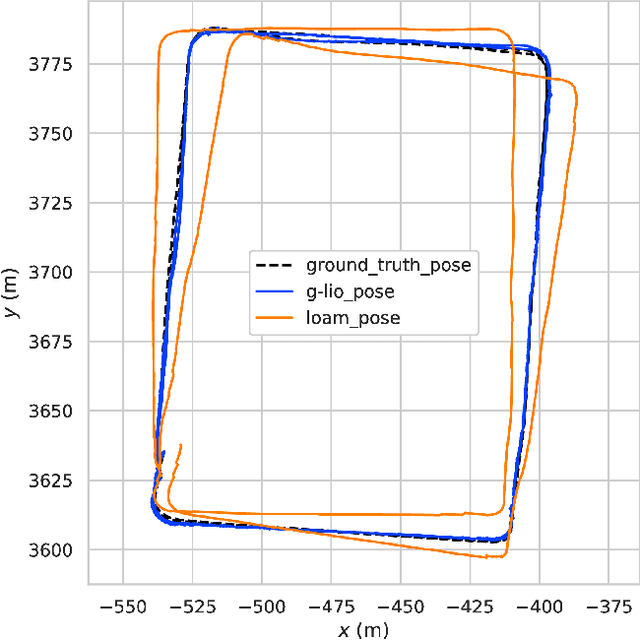
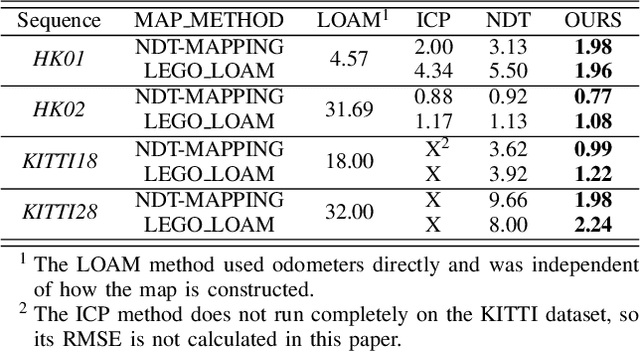
Currently, visual odometry and LIDAR odometry are performing well in pose estimation in some typical environments, but they still cannot recover the localization state at high speed or reduce accumulated drifts. In order to solve these problems, we propose a novel LIDAR-based localization framework, which achieves high accuracy and provides robust localization in 3D pointcloud maps with information of multi-sensors. The system integrates global information with LIDAR-based odometry to optimize the localization state. To improve robustness and enable fast resumption of localization, this paper uses offline pointcloud maps for prior knowledge and presents a novel registration method to speed up the convergence rate. The algorithm is tested on various maps of different data sets and has higher robustness and accuracy than other localization algorithms.
MambaFlow: A Novel and Flow-guided State Space Model for Scene Flow Estimation
Feb 24, 2025Scene flow estimation aims to predict 3D motion from consecutive point cloud frames, which is of great interest in autonomous driving field. Existing methods face challenges such as insufficient spatio-temporal modeling and inherent loss of fine-grained feature during voxelization. However, the success of Mamba, a representative state space model (SSM) that enables global modeling with linear complexity, provides a promising solution. In this paper, we propose MambaFlow, a novel scene flow estimation network with a mamba-based decoder. It enables deep interaction and coupling of spatio-temporal features using a well-designed backbone. Innovatively, we steer the global attention modeling of voxel-based features with point offset information using an efficient Mamba-based decoder, learning voxel-to-point patterns that are used to devoxelize shared voxel representations into point-wise features. To further enhance the model's generalization capabilities across diverse scenarios, we propose a novel scene-adaptive loss function that automatically adapts to different motion patterns.Extensive experiments on the Argoverse 2 benchmark demonstrate that MambaFlow achieves state-of-the-art performance with real-time inference speed among existing works, enabling accurate flow estimation in real-world urban scenarios. The code is available at https://github.com/SCNU-RISLAB/MambaFlow.
CV-MOS: A Cross-View Model for Motion Segmentation
Aug 25, 2024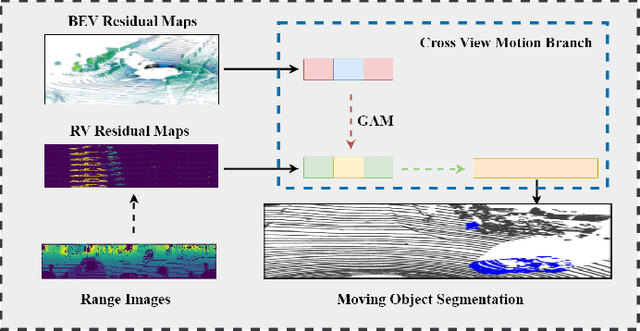
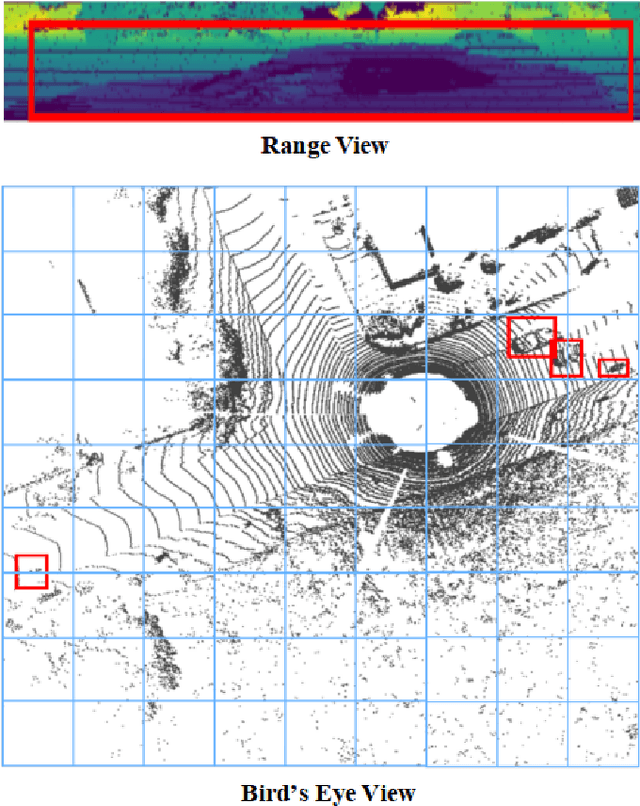
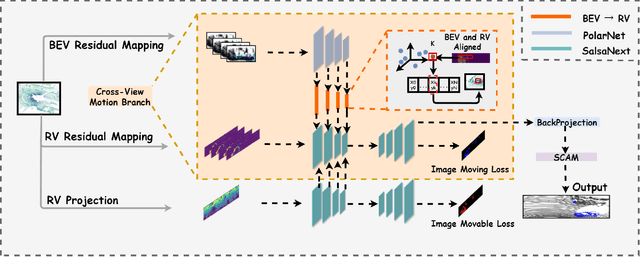
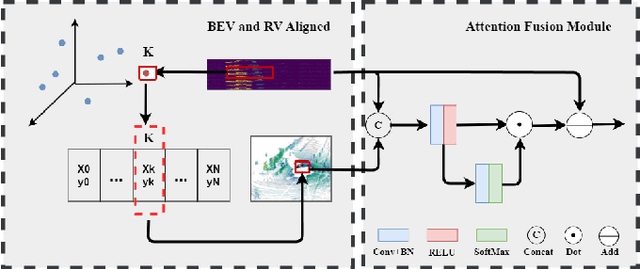
In autonomous driving, accurately distinguishing between static and moving objects is crucial for the autonomous driving system. When performing the motion object segmentation (MOS) task, effectively leveraging motion information from objects becomes a primary challenge in improving the recognition of moving objects. Previous methods either utilized range view (RV) or bird's eye view (BEV) residual maps to capture motion information. Unlike traditional approaches, we propose combining RV and BEV residual maps to exploit a greater potential of motion information jointly. Thus, we introduce CV-MOS, a cross-view model for moving object segmentation. Novelty, we decouple spatial-temporal information by capturing the motion from BEV and RV residual maps and generating semantic features from range images, which are used as moving object guidance for the motion branch. Our direct and unique solution maximizes the use of range images and RV and BEV residual maps, significantly enhancing the performance of LiDAR-based MOS task. Our method achieved leading IoU(\%) scores of 77.5\% and 79.2\% on the validation and test sets of the SemanticKitti dataset. In particular, CV-MOS demonstrates SOTA performance to date on various datasets. The CV-MOS implementation is available at https://github.com/SCNU-RISLAB/CV-MOS
Efficient Global Navigational Planning in 3D Structures based on Point Cloud Tomography
Mar 12, 2024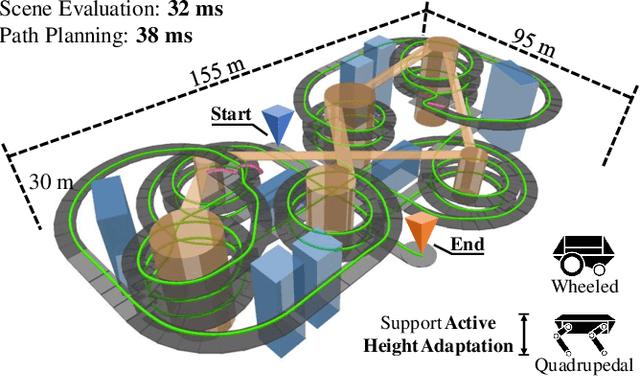
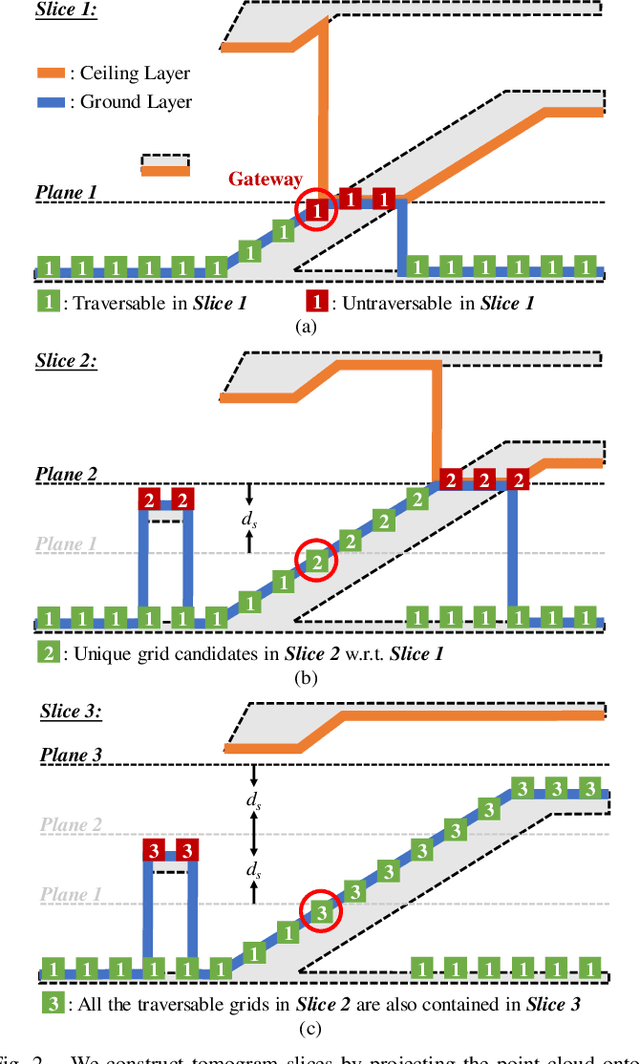
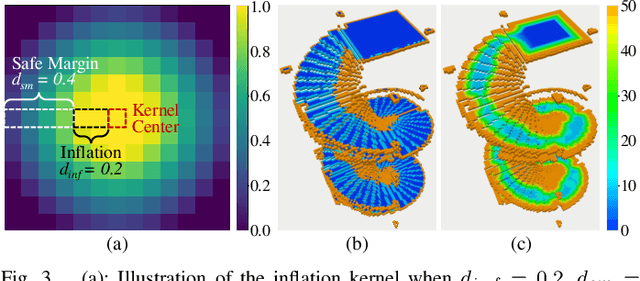
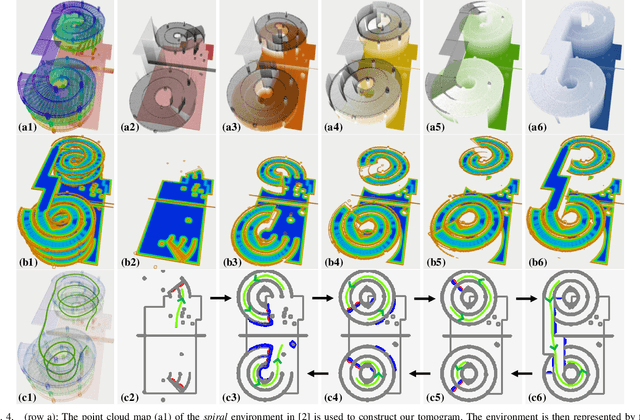
Navigation in complex 3D scenarios requires appropriate environment representation for efficient scene understanding and trajectory generation. We propose a highly efficient and extensible global navigation framework based on a tomographic understanding of the environment to navigate ground robots in multi-layer structures. Our approach generates tomogram slices using the point cloud map to encode the geometric structure as ground and ceiling elevations. Then it evaluates the scene traversability considering the robot's motion capabilities. Both the tomogram construction and the scene evaluation are accelerated through parallel computation. Our approach further alleviates the trajectory generation complexity compared with planning in 3D spaces directly. It generates 3D trajectories by searching through multiple tomogram slices and separately adjusts the robot height to avoid overhangs. We evaluate our framework in various simulation scenarios and further test it in the real world on a quadrupedal robot. Our approach reduces the scene evaluation time by 3 orders of magnitude and improves the path planning speed by 3 times compared with existing approaches, demonstrating highly efficient global navigation in various complex 3D environments. The code is available at: https://github.com/byangw/PCT_planner.
Three-Filters-to-Normal+: Revisiting Discontinuity Discrimination in Depth-to-Normal Translation
Dec 13, 2023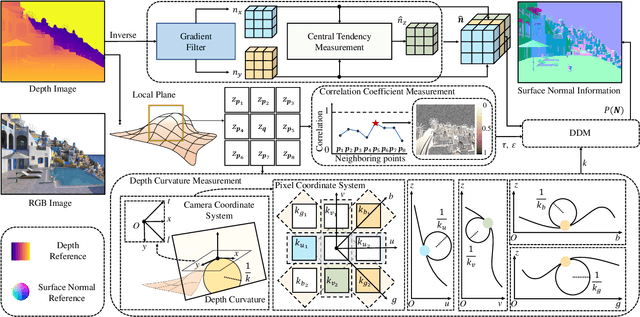
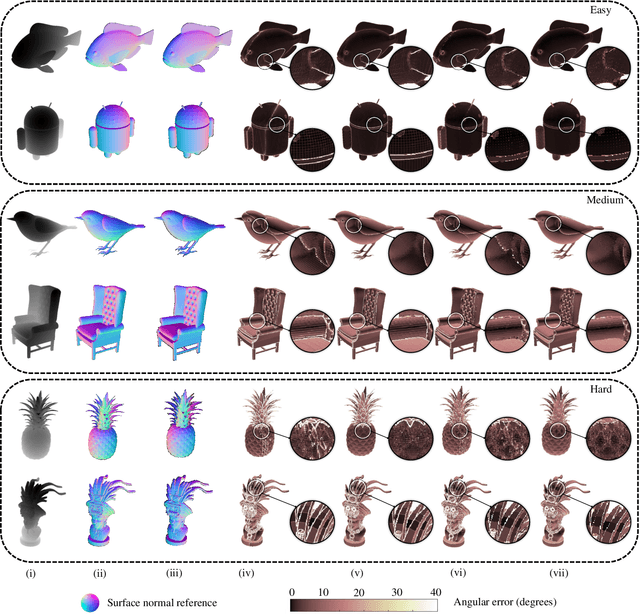
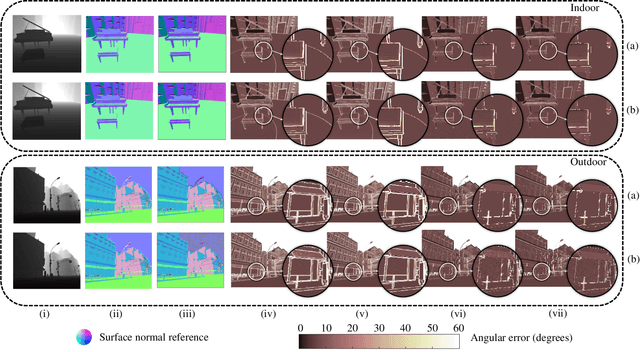
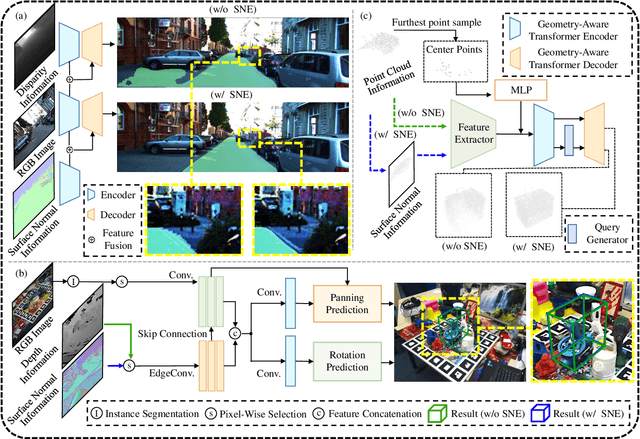
This article introduces three-filters-to-normal+ (3F2N+), an extension of our previous work three-filters-to-normal (3F2N), with a specific focus on incorporating discontinuity discrimination capability into surface normal estimators (SNEs). 3F2N+ achieves this capability by utilizing a novel discontinuity discrimination module (DDM), which combines depth curvature minimization and correlation coefficient maximization through conditional random fields (CRFs). To evaluate the robustness of SNEs on noisy data, we create a large-scale synthetic surface normal (SSN) dataset containing 20 scenarios (ten indoor scenarios and ten outdoor scenarios with and without random Gaussian noise added to depth images). Extensive experiments demonstrate that 3F2N+ achieves greater performance than all other geometry-based surface normal estimators, with average angular errors of 7.85$^\circ$, 8.95$^\circ$, 9.25$^\circ$, and 11.98$^\circ$ on the clean-indoor, clean-outdoor, noisy-indoor, and noisy-outdoor datasets, respectively. We conduct three additional experiments to demonstrate the effectiveness of incorporating our proposed 3F2N+ into downstream robot perception tasks, including freespace detection, 6D object pose estimation, and point cloud completion. Our source code and datasets are publicly available at https://mias.group/3F2Nplus.
D2NT: A High-Performing Depth-to-Normal Translator
Apr 24, 2023Surface normal holds significant importance in visual environmental perception, serving as a source of rich geometric information. However, the state-of-the-art (SoTA) surface normal estimators (SNEs) generally suffer from an unsatisfactory trade-off between efficiency and accuracy. To resolve this dilemma, this paper first presents a superfast depth-to-normal translator (D2NT), which can directly translate depth images into surface normal maps without calculating 3D coordinates. We then propose a discontinuity-aware gradient (DAG) filter, which adaptively generates gradient convolution kernels to improve depth gradient estimation. Finally, we propose a surface normal refinement module that can easily be integrated into any depth-to-normal SNEs, substantially improving the surface normal estimation accuracy. Our proposed algorithm demonstrates the best accuracy among all other existing real-time SNEs and achieves the SoTA trade-off between efficiency and accuracy.
V2HDM-Mono: A Framework of Building a Marking-Level HD Map with One or More Monocular Cameras
Sep 16, 2022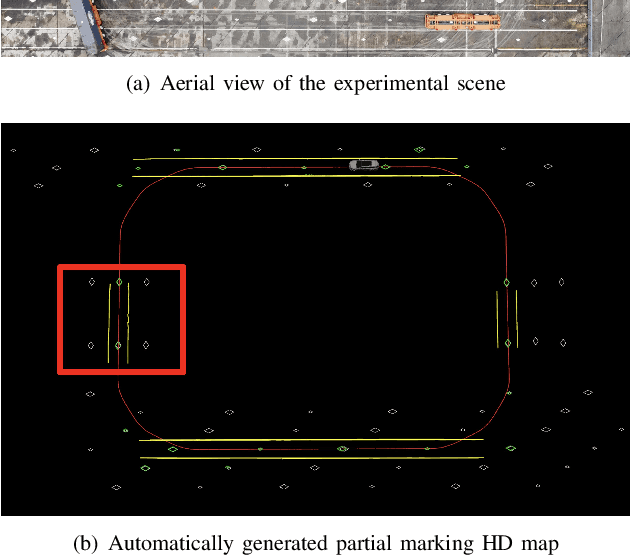
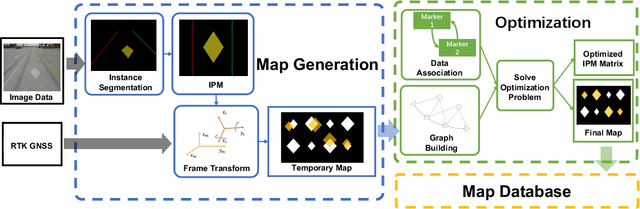

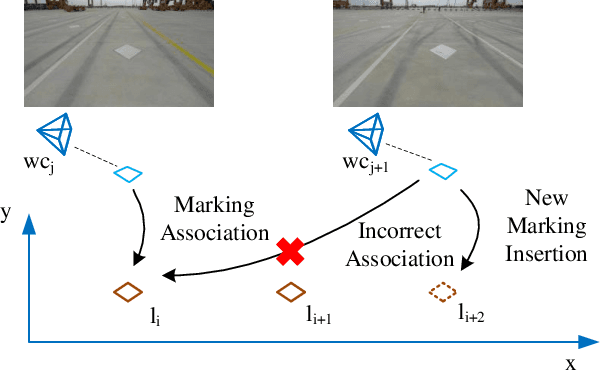
Marking-level high-definition maps (HD maps) are of great significance for autonomous vehicles, especially in large-scale, appearance-changing scenarios where autonomous vehicles rely on markings for localization and lanes for safe driving. In this paper, we propose a highly feasible framework for automatically building a marking-level HD map using a simple sensor setup (one or more monocular cameras). We optimize the position of the marking corners to fit the result of marking segmentation and simultaneously optimize the inverse perspective mapping (IPM) matrix of the corresponding camera to obtain an accurate transformation from the front view image to the bird's-eye view (BEV). In the quantitative evaluation, the built HD map almost attains centimeter-level accuracy. The accuracy of the optimized IPM matrix is similar to that of the manual calibration. The method can also be generalized to build HD maps in a broader sense by increasing the types of recognizable markings.
Three-Filters-to-Normal: An Accurate and Ultrafast Surface Normal Estimator
May 23, 2020
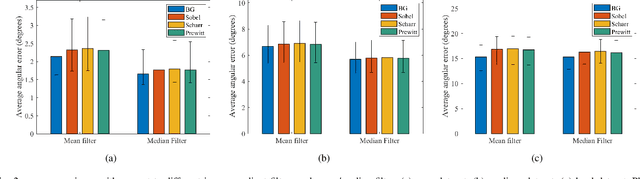
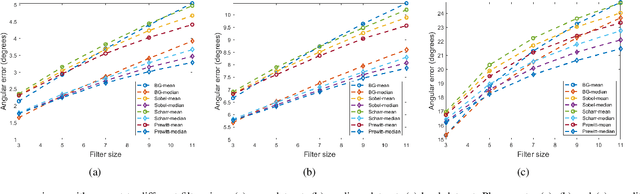
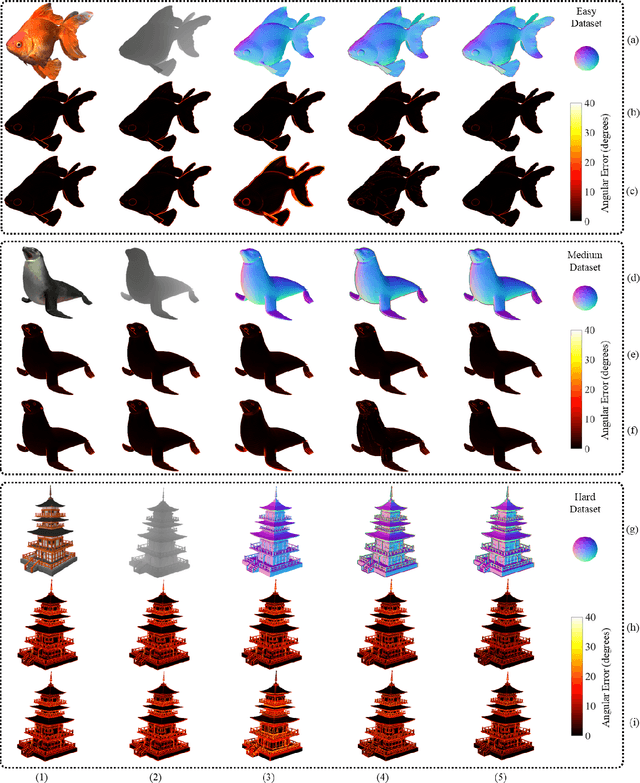
Over the past decade, significant efforts have been made to improve the trade-off between speed and accuracy of surface normal estimators (SNEs). This paper introduces an accurate and ultrafast SNE for structured range data. The proposed approach computes surface normals by simply performing three filtering operations, namely, two image gradient filters (in horizontal and vertical directions, respectively) and a mean/median filter, on an inverse depth image or a disparity image. Despite the simplicity of the method, no similar method already exists in the literature. In our experiments, we created three large-scale synthetic datasets (easy, medium and hard) using 24 3-dimensional (3D) mesh models. Each mesh model is used to generate 1800--2500 pairs of 480x640 pixel depth images and the corresponding surface normal ground truth from different views. The average angular errors with respect to the easy, medium and hard datasets are 1.6 degrees, 5.6 degrees and 15.3 degrees, respectively. Our C++ and CUDA implementations achieve a processing speed of over 260 Hz and 21 kHz, respectively. Our proposed SNE achieves a better overall performance than all other existing computer vision-based SNEs. Our datasets and source code are publicly available at: sites.google.com/view/3f2n.
Road Curb Detection Using A Novel Tensor Voting Algorithm
Nov 29, 2019

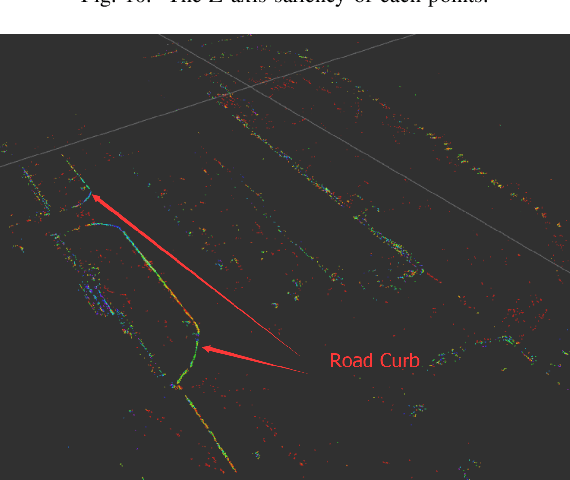
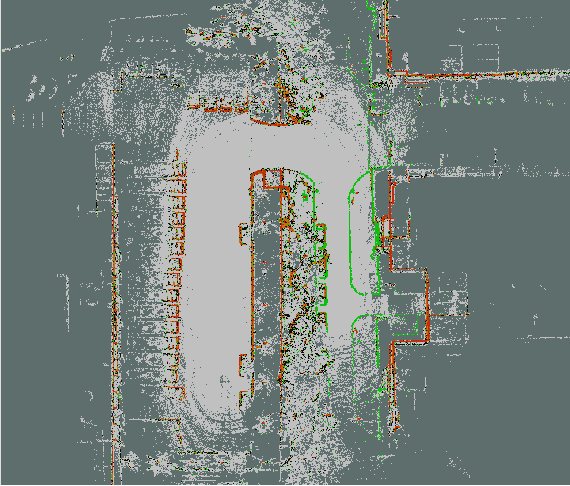
Road curb detection is very important and necessary for autonomous driving because it can improve the safety and robustness of robot navigation in the outdoor environment. In this paper, a novel road curb detection method based on tensor voting is presented. The proposed method processes the dense point cloud acquired using a 3D LiDAR. Firstly, we utilize a sparse tensor voting approach to extract the line and surface features. Then, we use an adaptive height threshold and a surface vector to extract the point clouds of the road curbs. Finally, we utilize the height threshold to segment different obstacles from the occupancy grid map. This also provides an effective way of generating high-definition maps. The experimental results illustrate that our proposed algorithm can detect road curbs with near real-time performance.
Robust Lane Marking Detection Algorithm Using Drivable Area Segmentation and Extended SLT
Nov 20, 2019


In this paper, a robust lane detection algorithm is proposed, where the vertical road profile of the road is estimated using dynamic programming from the v-disparity map and, based on the estimated profile, the road area is segmented. Since the lane markings are on the road area and any feature point above the ground will be a noise source for the lane detection, a mask is created for the road area to remove some of the noise for lane detection. The estimated mask is multiplied by the lane feature map in a bird's eye view (BEV). The lane feature points are extracted by using an extended version of symmetrical local threshold (SLT), which not only considers dark light dark transition (DLD) of the lane markings, like (SLT), but also considers parallelism on the lane marking borders. The segmentation then uses only the feature points that are on the road area. A maximum of two linear lane markings are detected using an efficient 1D Hough transform. Then, the detected linear lane markings are used to create a region of interest (ROI) for parabolic lane detection. Finally, based on the estimated region of interest, parabolic lane models are fitted using robust fitting. Due to the robust lane feature extraction and road area segmentation, the proposed algorithm robustly detects lane markings and achieves lane marking detection with an accuracy of 91% when tested on a sequence from the KITTI dataset.