 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Camera Exposure Control for Visual Odometry via Deep Reinforcement Learning
Aug 30, 2024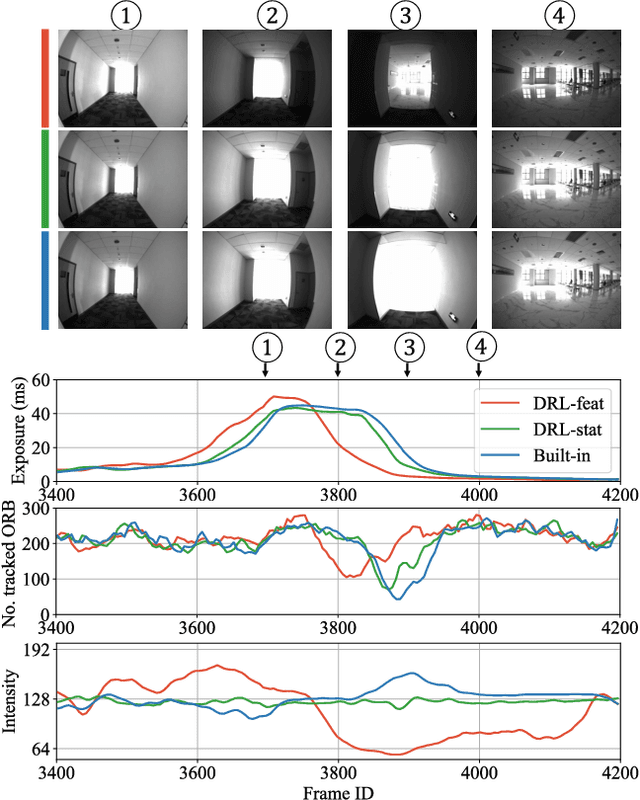
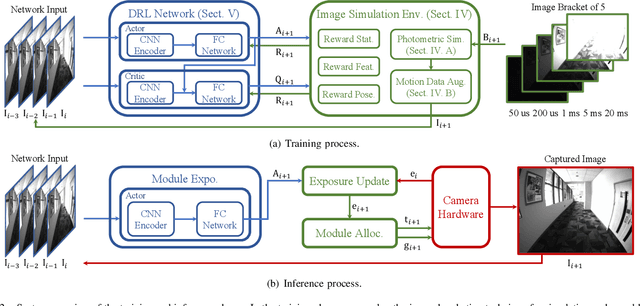
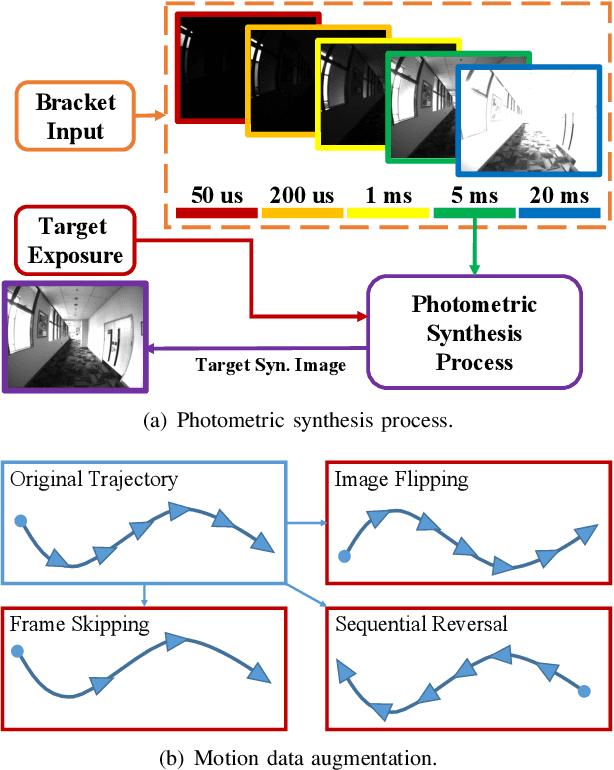

The stability of visual odometry (VO) systems is undermined by degraded image quality, especially in environments with significant illumination changes. This study employs a deep reinforcement learning (DRL) framework to train agents for exposure control, aiming to enhance imaging performance in challenging conditions. A lightweight image simulator is developed to facilitate the training process, enabling the diversification of image exposure and sequence trajectory. This setup enables completely offline training, eliminating the need for direct interaction with camera hardware and the real environments. Different levels of reward functions are crafted to enhance the VO systems, equipping the DRL agents with varying intelligence. Extensive experiments have shown that our exposure control agents achieve superior efficiency-with an average inference duration of 1.58 ms per frame on a CPU-and respond more quickly than traditional feedback control schemes. By choosing an appropriate reward function, agents acquire an intelligent understanding of motion trends and anticipate future illumination changes. This predictive capability allows VO systems to deliver more stable and precise odometry results. The codes and datasets are available at https://github.com/ShuyangUni/drl_exposure_ctrl.
FusionPortableV2: A Unified Multi-Sensor Dataset for Generalized SLAM Across Diverse Platforms and Scalable Environments
Apr 12, 2024Simultaneous Localization and Mapping (SLAM) technology has been widely applied in various robotic scenarios, from rescue operations to autonomous driving. However, the generalization of SLAM algorithms remains a significant challenge, as current datasets often lack scalability in terms of platforms and environments. To address this limitation, we present FusionPortableV2, a multi-sensor SLAM dataset featuring notable sensor diversity, varied motion patterns, and a wide range of environmental scenarios. Our dataset comprises $27$ sequences, spanning over $2.5$ hours and collected from four distinct platforms: a handheld suite, wheeled and legged robots, and vehicles. These sequences cover diverse settings, including buildings, campuses, and urban areas, with a total length of $38.7km$. Additionally, the dataset includes ground-truth (GT) trajectories and RGB point cloud maps covering approximately $0.3km^2$. To validate the utility of our dataset in advancing SLAM research, we assess several state-of-the-art (SOTA) SLAM algorithms. Furthermore, we demonstrate the dataset's broad applicability beyond traditional SLAM tasks by investigating its potential for monocular depth estimation. The complete dataset, including sensor data, GT, and calibration details, is accessible at https://fusionportable.github.io/dataset/fusionportable_v2.
FusionPortable: A Multi-Sensor Campus-Scene Dataset for Evaluation of Localization and Mapping Accuracy on Diverse Platforms
Aug 25, 2022

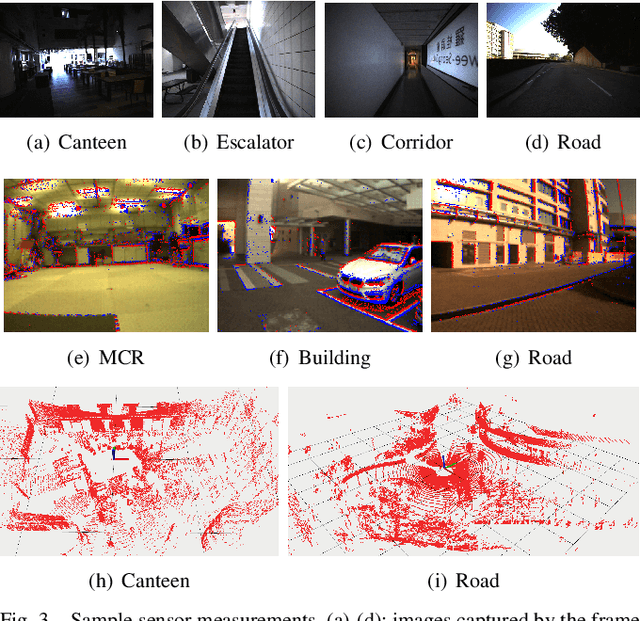

Combining multiple sensors enables a robot to maximize its perceptual awareness of environments and enhance its robustness to external disturbance, crucial to robotic navigation. This paper proposes the FusionPortable benchmark, a complete multi-sensor dataset with a diverse set of sequences for mobile robots. This paper presents three contributions. We first advance a portable and versatile multi-sensor suite that offers rich sensory measurements: 10Hz LiDAR point clouds, 20Hz stereo frame images, high-rate and asynchronous events from stereo event cameras, 200Hz inertial readings from an IMU, and 10Hz GPS signal. Sensors are already temporally synchronized in hardware. This device is lightweight, self-contained, and has plug-and-play support for mobile robots. Second, we construct a dataset by collecting 17 sequences that cover a variety of environments on the campus by exploiting multiple robot platforms for data collection. Some sequences are challenging to existing SLAM algorithms. Third, we provide ground truth for the decouple localization and mapping performance evaluation. We additionally evaluate state-of-the-art SLAM approaches and identify their limitations. The dataset, consisting of raw sensor easurements, ground truth, calibration data, and evaluated algorithms, will be released: https://ram-lab.com/file/site/multi-sensor-dataset.
Comparing Representations in Tracking for Event Camera-based SLAM
Apr 20, 2021
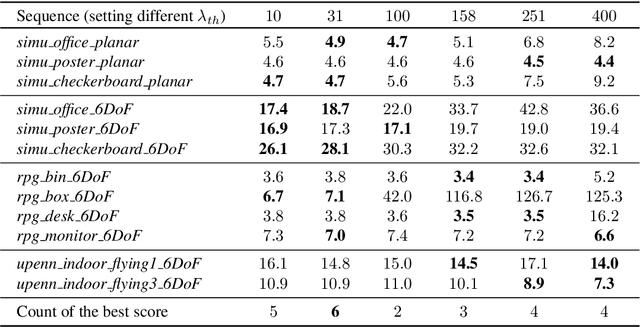

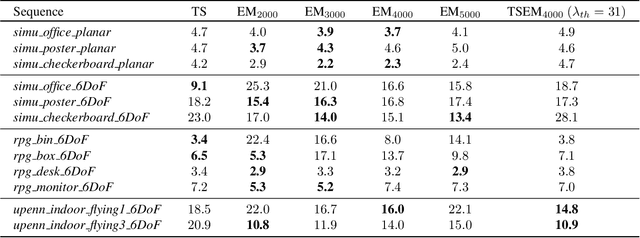
This paper investigates two typical image-type representations for event camera-based tracking: time surface (TS) and event map (EM). Based on the original TS-based tracker, we make use of these two representations' complementary strengths to develop an enhanced version. The proposed tracker consists of a general strategy to evaluate the optimization problem's degeneracy online and then switch proper representations. Both TS and EM are motion- and scene-dependent, and thus it is important to figure out their limitations in tracking. We develop six tracker variations and conduct a thorough comparison of them on sequences covering various scenarios and motion complexities. We release our implementations and detailed results to benefit the research community on event cameras: https: //github.com/gogojjh/ESVO_extension.
Greedy-Based Feature Selection for Efficient LiDAR SLAM
Mar 24, 2021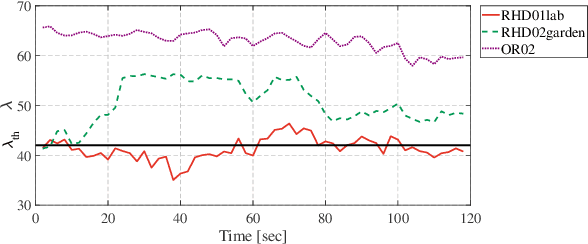
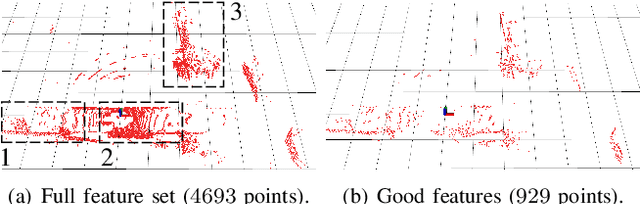
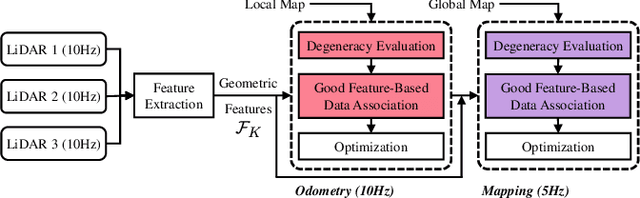
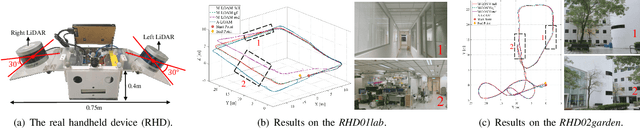
Modern LiDAR-SLAM (L-SLAM) systems have shown excellent results in large-scale, real-world scenarios. However, they commonly have a high latency due to the expensive data association and nonlinear optimization. This paper demonstrates that actively selecting a subset of features significantly improves both the accuracy and efficiency of an L-SLAM system. We formulate the feature selection as a combinatorial optimization problem under a cardinality constraint to preserve the information matrix's spectral attributes. The stochastic-greedy algorithm is applied to approximate the optimal results in real-time. To avoid ill-conditioned estimation, we also propose a general strategy to evaluate the environment's degeneracy and modify the feature number online. The proposed feature selector is integrated into a multi-LiDAR SLAM system. We validate this enhanced system with extensive experiments covering various scenarios on two sensor setups and computation platforms. We show that our approach exhibits low localization error and speedup compared to the state-of-the-art L-SLAM systems. To benefit the community, we have released the source code: https://ram-lab.com/file/site/m-loam.
Robust Odometry and Mapping for Multi-LiDAR Systems with Online Extrinsic Calibration
Oct 27, 2020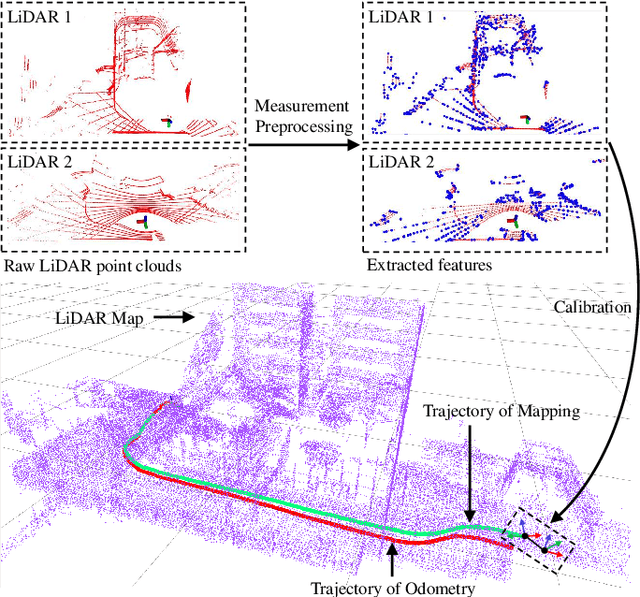
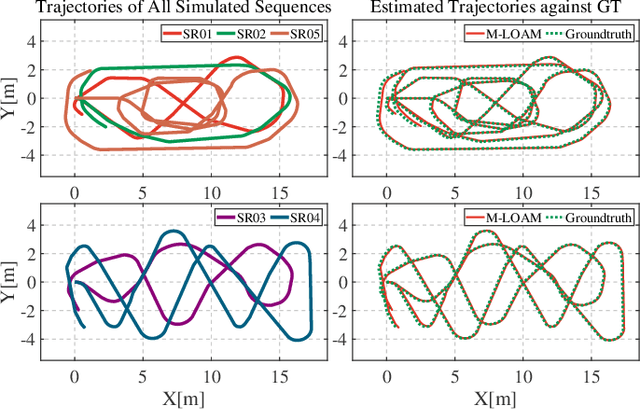
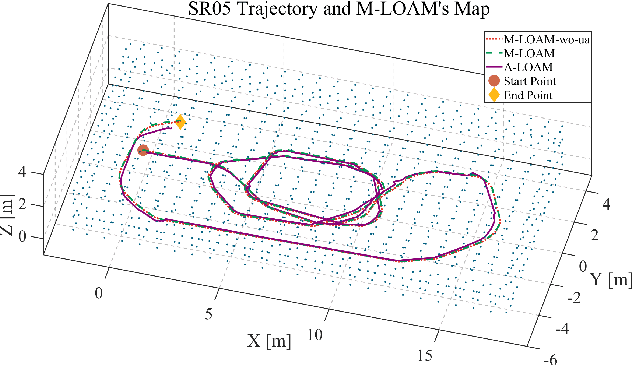
Combining multiple LiDARs enables a robot to maximize its perceptual awareness of environments and obtain sufficient measurements, which is promising for simultaneous localization and mapping (SLAM). This paper proposes a system to achieve robust and simultaneous extrinsic calibration, odometry, and mapping for multiple LiDARs. Our approach starts with measurement preprocessing to extract edge and planar features from raw measurements. After a motion and extrinsic initialization procedure, a sliding window-based multi-LiDAR odometry runs onboard to estimate poses with online calibration refinement and convergence identification. We further develop a mapping algorithm to construct a global map and optimize poses with sufficient features together with a method to model and reduce data uncertainty. We validate our approach's performance with extensive experiments on ten sequences (4.60km total length) for the calibration and SLAM and compare them against the state-of-the-art. We demonstrate that the proposed work is a complete, robust, and extensible system for various multi-LiDAR setups. The source code, datasets, and demonstrations are available at https://ram-lab.com/file/site/m-loam.
Hercules: An Autonomous Logistic Vehicle for Contact-less Goods Transportation During the COVID-19 Outbreak
Apr 16, 2020
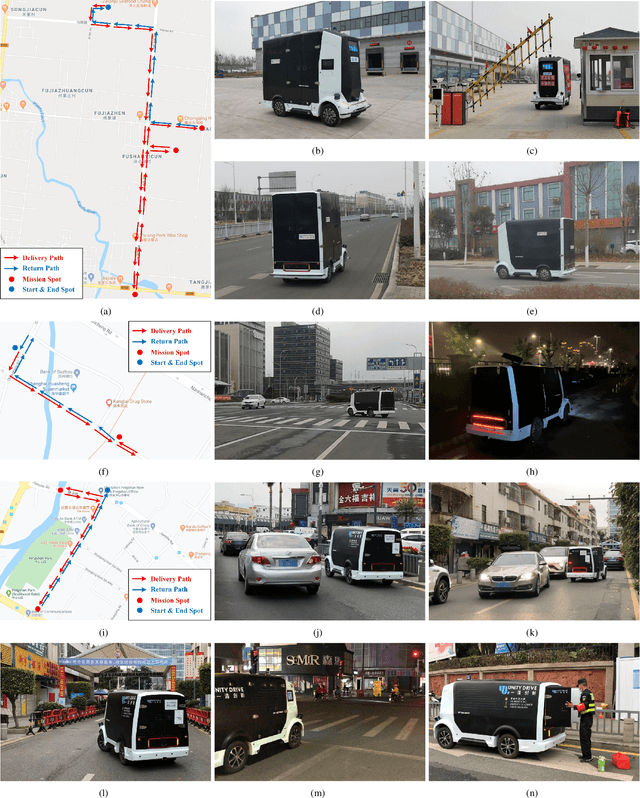
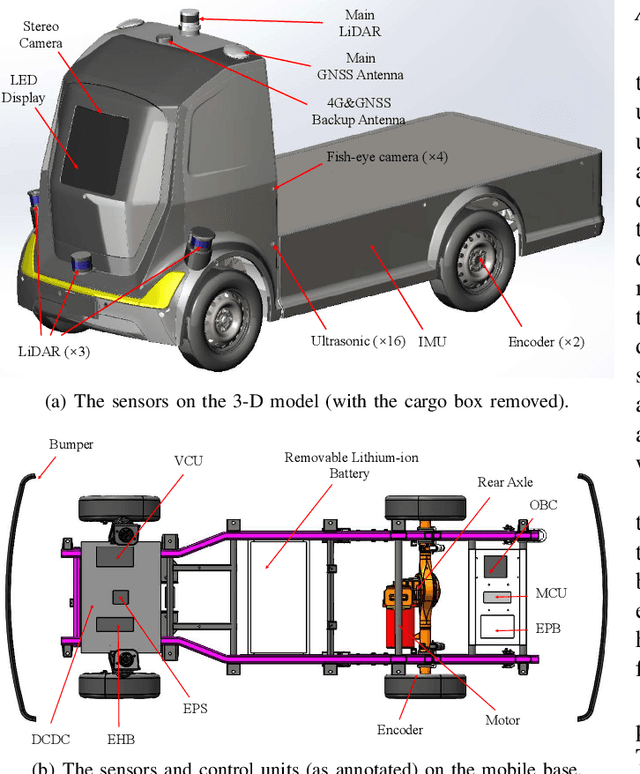
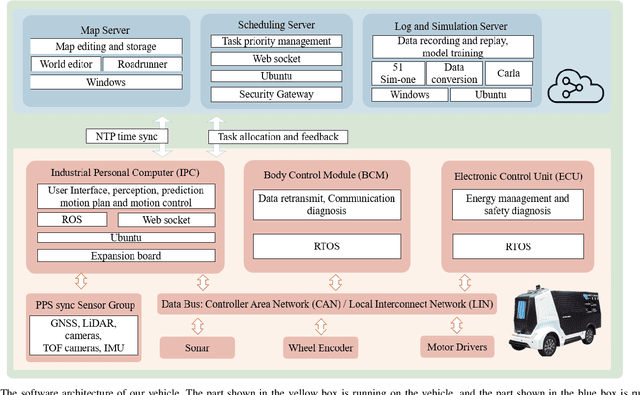
Since December 2019, the coronavirus disease 2019 (COVID-19) has spread rapidly across China. As at the date of writing this article, the disease has been globally reported in 100 countries, infected over 100,000 people and caused over 3,000 deaths. Avoiding person-to-person transmission is an effective approach to control and prevent the epidemic. However, many daily activities, such as logistics transporting goods in our daily life, inevitably involve person-to-person contact. To achieve contact-less goods transportation, using an autonomous logistic vehicle has become the preferred choice. This article presents Hercules, an autonomous logistic vehicle used for contact-less goods transportation during the outbreak of COVID-19. The vehicle is designed with autonomous navigation capability. We provide details on the hardware and software, as well as the algorithms to achieve autonomous navigation including perception, planning and control. This paper is accompanied by a demonstration video and a dataset, which are available here: https://sites.google.com/view/contact-less-transportation.
Road Curb Detection Using A Novel Tensor Voting Algorithm
Nov 29, 2019

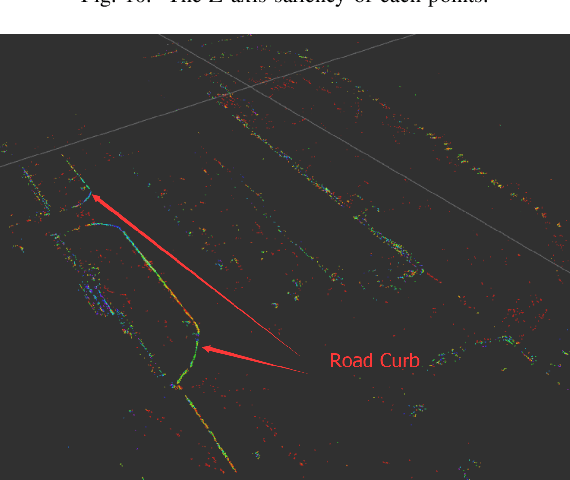
Road curb detection is very important and necessary for autonomous driving because it can improve the safety and robustness of robot navigation in the outdoor environment. In this paper, a novel road curb detection method based on tensor voting is presented. The proposed method processes the dense point cloud acquired using a 3D LiDAR. Firstly, we utilize a sparse tensor voting approach to extract the line and surface features. Then, we use an adaptive height threshold and a surface vector to extract the point clouds of the road curbs. Finally, we utilize the height threshold to segment different obstacles from the occupancy grid map. This also provides an effective way of generating high-definition maps. The experimental results illustrate that our proposed algorithm can detect road curbs with near real-time performance.
Robust Lane Marking Detection Algorithm Using Drivable Area Segmentation and Extended SLT
Nov 20, 2019


In this paper, a robust lane detection algorithm is proposed, where the vertical road profile of the road is estimated using dynamic programming from the v-disparity map and, based on the estimated profile, the road area is segmented. Since the lane markings are on the road area and any feature point above the ground will be a noise source for the lane detection, a mask is created for the road area to remove some of the noise for lane detection. The estimated mask is multiplied by the lane feature map in a bird's eye view (BEV). The lane feature points are extracted by using an extended version of symmetrical local threshold (SLT), which not only considers dark light dark transition (DLD) of the lane markings, like (SLT), but also considers parallelism on the lane marking borders. The segmentation then uses only the feature points that are on the road area. A maximum of two linear lane markings are detected using an efficient 1D Hough transform. Then, the detected linear lane markings are used to create a region of interest (ROI) for parabolic lane detection. Finally, based on the estimated region of interest, parabolic lane models are fitted using robust fitting. Due to the robust lane feature extraction and road area segmentation, the proposed algorithm robustly detects lane markings and achieves lane marking detection with an accuracy of 91% when tested on a sequence from the KITTI dataset.
Automatic Calibration of Dual-LiDARs Using Two Poles Stickered with Retro-Reflective Tape
Nov 02, 2019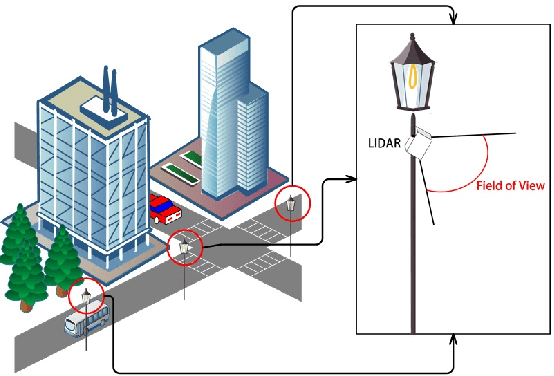

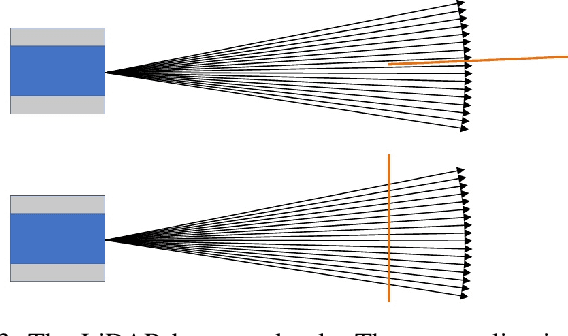
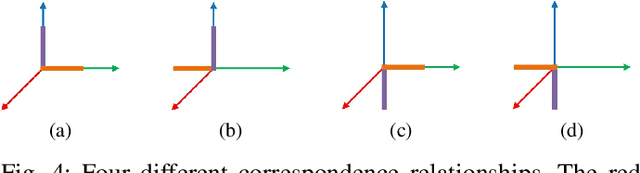
Multi-LiDAR systems have been prevalently applied in modern autonomous vehicles to render a broad view of the environments. The rapid development of 5G wireless technologies has brought a breakthrough for current cellular vehicle-to-everything (C-V2X) applications. Therefore, a novel localization and perception system in which multiple LiDARs are mounted around cities for autonomous vehicles has been proposed. However, the existing calibration methods require specific hard-to-move markers, ego-motion, or good initial values given by users. In this paper, we present a novel approach that enables automatic multi-LiDAR calibration using two poles stickered with retro-reflective tape. This method does not depend on prior environmental information, initial values of the extrinsic parameters, or movable platforms like a car. We analyze the LiDAR-pole model, verify the feasibility of the algorithm through simulation data, and present a simple method to measure the calibration errors w.r.t the ground truth. Experimental results demonstrate that our approach gains better flexibility and higher accuracy when compared with the state-of-the-art approach.