 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRareAgents: Autonomous Multi-disciplinary Team for Rare Disease Diagnosis and Treatment
Dec 17, 2024



Rare diseases, despite their low individual incidence, collectively impact around 300 million people worldwide due to the huge number of diseases. The complexity of symptoms and the shortage of specialized doctors with relevant experience make diagnosing and treating rare diseases more challenging than common diseases. Recently, agents powered by large language models (LLMs) have demonstrated notable improvements across various domains. In the medical field, some agent methods have outperformed direct prompts in question-answering tasks from medical exams. However, current agent frameworks lack adaptation for real-world clinical scenarios, especially those involving the intricate demands of rare diseases. To address these challenges, we present RareAgents, the first multi-disciplinary team of LLM-based agents tailored to the complex clinical context of rare diseases. RareAgents integrates advanced planning capabilities, memory mechanisms, and medical tools utilization, leveraging Llama-3.1-8B/70B as the base model. Experimental results show that RareAgents surpasses state-of-the-art domain-specific models, GPT-4o, and existing agent frameworks in both differential diagnosis and medication recommendation for rare diseases. Furthermore, we contribute a novel dataset, MIMIC-IV-Ext-Rare, derived from MIMIC-IV, to support further advancements in this field.
Deep Uncertainty-aware Tracking for Maneuvering Targets
Oct 18, 2024When tracking maneuvering targets, model-driven approaches encounter difficulties in comprehensively delineating complex real-world scenarios and are prone to model mismatch when the targets maneuver. Meanwhile, contemporary data-driven methods have overlooked measurements' confidence, markedly escalating the challenge of fitting a mapping from measurement sequences to target state sequences. To address these issues, this paper presents a deep maneuvering target tracking methodology based on target state space projection. The proposed methodology initially establishes a projection from the target measurement sequence to the target state space by formulating the probability density function of measurement error and samples the distribution information of measurement noise within the target state space as a measurement representation. Under this representation, the sequential regression task of target state estimation can be transmuted into a task of detecting the target location in the state space. Subsequently, a deep detection network is devised to accomplish target location detection in the target state space. Finally, a loss function is designed to facilitate the network's training for attaining the desired network performance. Simulation experiments suggest that the proposed method can maintain satisfactory tracking performance even when the target maneuvers, and can rapidly converge and achieve higher estimation accuracy compared with existing methods after the target maneuvers.
Efficient Camera Exposure Control for Visual Odometry via Deep Reinforcement Learning
Aug 30, 2024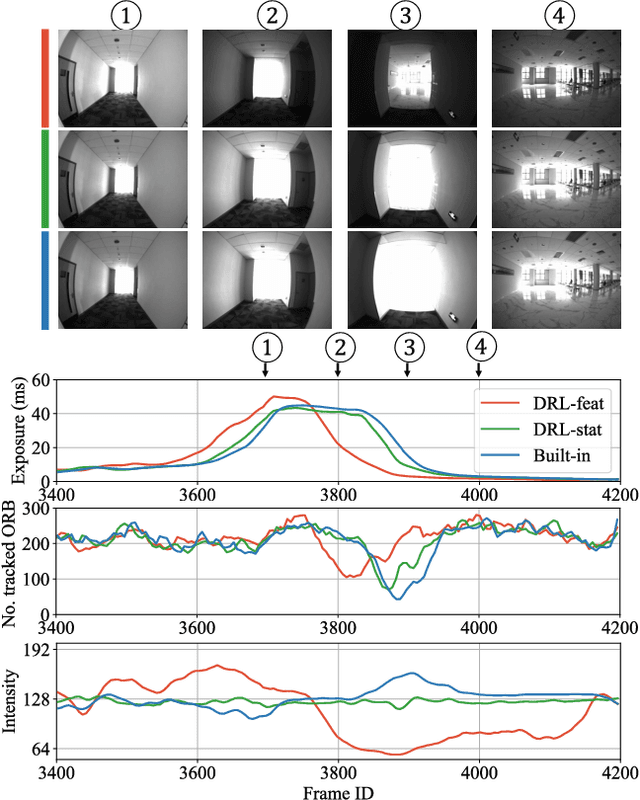
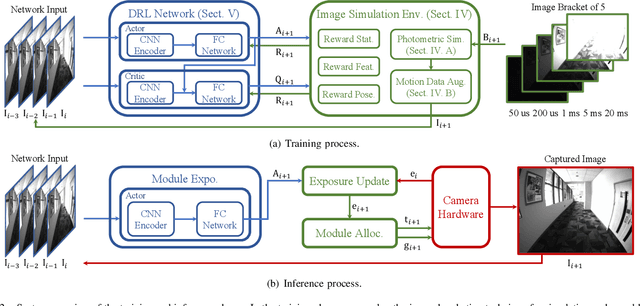
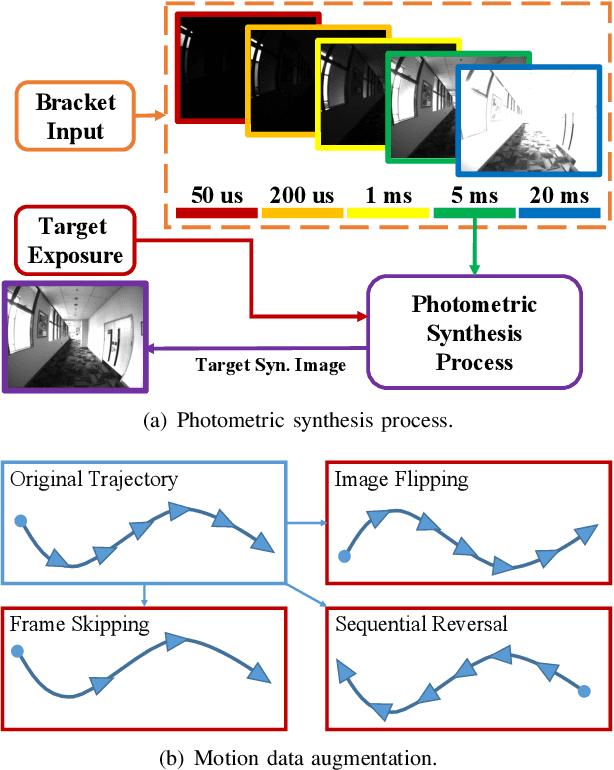

The stability of visual odometry (VO) systems is undermined by degraded image quality, especially in environments with significant illumination changes. This study employs a deep reinforcement learning (DRL) framework to train agents for exposure control, aiming to enhance imaging performance in challenging conditions. A lightweight image simulator is developed to facilitate the training process, enabling the diversification of image exposure and sequence trajectory. This setup enables completely offline training, eliminating the need for direct interaction with camera hardware and the real environments. Different levels of reward functions are crafted to enhance the VO systems, equipping the DRL agents with varying intelligence. Extensive experiments have shown that our exposure control agents achieve superior efficiency-with an average inference duration of 1.58 ms per frame on a CPU-and respond more quickly than traditional feedback control schemes. By choosing an appropriate reward function, agents acquire an intelligent understanding of motion trends and anticipate future illumination changes. This predictive capability allows VO systems to deliver more stable and precise odometry results. The codes and datasets are available at https://github.com/ShuyangUni/drl_exposure_ctrl.
Accurate Prior-centric Monocular Positioning with Offline LiDAR Fusion
Jul 12, 2024Unmanned vehicles usually rely on Global Positioning System (GPS) and Light Detection and Ranging (LiDAR) sensors to achieve high-precision localization results for navigation purpose. However, this combination with their associated costs and infrastructure demands, poses challenges for widespread adoption in mass-market applications. In this paper, we aim to use only a monocular camera to achieve comparable onboard localization performance by tracking deep-learning visual features on a LiDAR-enhanced visual prior map. Experiments show that the proposed algorithm can provide centimeter-level global positioning results with scale, which is effortlessly integrated and favorable for low-cost robot system deployment in real-world applications.
RareBench: Can LLMs Serve as Rare Diseases Specialists?
Feb 09, 2024



Generalist Large Language Models (LLMs), such as GPT-4, have shown considerable promise in various domains, including medical diagnosis. Rare diseases, affecting approximately 300 million people worldwide, often have unsatisfactory clinical diagnosis rates primarily due to a lack of experienced physicians and the complexity of differentiating among many rare diseases. In this context, recent news such as "ChatGPT correctly diagnosed a 4-year-old's rare disease after 17 doctors failed" underscore LLMs' potential, yet underexplored, role in clinically diagnosing rare diseases. To bridge this research gap, we introduce RareBench, a pioneering benchmark designed to systematically evaluate the capabilities of LLMs on 4 critical dimensions within the realm of rare diseases. Meanwhile, we have compiled the largest open-source dataset on rare disease patients, establishing a benchmark for future studies in this domain. To facilitate differential diagnosis of rare diseases, we develop a dynamic few-shot prompt methodology, leveraging a comprehensive rare disease knowledge graph synthesized from multiple knowledge bases, significantly enhancing LLMs' diagnostic performance. Moreover, we present an exhaustive comparative study of GPT-4's diagnostic capabilities against those of specialist physicians. Our experimental findings underscore the promising potential of integrating LLMs into the clinical diagnostic process for rare diseases. This paves the way for exciting possibilities in future advancements in this field.
CANAMRF: An Attention-Based Model for Multimodal Depression Detection
Jan 04, 2024Multimodal depression detection is an important research topic that aims to predict human mental states using multimodal data. Previous methods treat different modalities equally and fuse each modality by na\"ive mathematical operations without measuring the relative importance between them, which cannot obtain well-performed multimodal representations for downstream depression tasks. In order to tackle the aforementioned concern, we present a Cross-modal Attention Network with Adaptive Multi-modal Recurrent Fusion (CANAMRF) for multimodal depression detection. CANAMRF is constructed by a multimodal feature extractor, an Adaptive Multimodal Recurrent Fusion module, and a Hybrid Attention Module. Through experimentation on two benchmark datasets, CANAMRF demonstrates state-of-the-art performance, underscoring the effectiveness of our proposed approach.
Outram: One-shot Global Localization via Triangulated Scene Graph and Global Outlier Pruning
Sep 16, 2023



One-shot LiDAR localization refers to the ability to estimate the robot pose from one single point cloud, which yields significant advantages in initialization and relocalization processes. In the point cloud domain, the topic has been extensively studied as a global descriptor retrieval (i.e., loop closure detection) and pose refinement (i.e., point cloud registration) problem both in isolation or combined. However, few have explicitly considered the relationship between candidate retrieval and correspondence generation in pose estimation, leaving them brittle to substructure ambiguities. To this end, we propose a hierarchical one-shot localization algorithm called Outram that leverages substructures of 3D scene graphs for locally consistent correspondence searching and global substructure-wise outlier pruning. Such a hierarchical process couples the feature retrieval and the correspondence extraction to resolve the substructure ambiguities by conducting a local-to-global consistency refinement. We demonstrate the capability of Outram in a variety of scenarios in multiple large-scale outdoor datasets. Our implementation is open-sourced: https://github.com/Pamphlett/Outram.
Segregator: Global Point Cloud Registration with Semantic and Geometric Cues
Jan 18, 2023This paper presents Segregator, a global point cloud registration framework that exploits both semantic information and geometric distribution to efficiently build up outlier-robust correspondences and search for inliers. Current state-of-the-art algorithms rely on point features to set up putative correspondences and refine them by employing pair-wise distance consistency checks. However, such a scheme suffers from degenerate cases, where the descriptive capability of local point features downgrades, and unconstrained cases, where length-preserving (l-TRIMs)-based checks cannot sufficiently constrain whether the current observation is consistent with others, resulting in a complexified NP-complete problem to solve. To tackle these problems, on the one hand, we propose a novel degeneracy-robust and efficient corresponding procedure consisting of both instance-level semantic clusters and geometric-level point features. On the other hand, Gaussian distribution-based translation and rotation invariant measurements (G-TRIMs) are proposed to conduct the consistency check and further constrain the problem size. We validated our proposed algorithm on extensive real-world data-based experiments. The code is available: https://github.com/Pamphlett/Segregator.
Directed Acyclic Graph Structure Learning from Dynamic Graphs
Nov 30, 2022



Estimating the structure of directed acyclic graphs (DAGs) of features (variables) plays a vital role in revealing the latent data generation process and providing causal insights in various applications. Although there have been many studies on structure learning with various types of data, the structure learning on the dynamic graph has not been explored yet, and thus we study the learning problem of node feature generation mechanism on such ubiquitous dynamic graph data. In a dynamic graph, we propose to simultaneously estimate contemporaneous relationships and time-lagged interaction relationships between the node features. These two kinds of relationships form a DAG, which could effectively characterize the feature generation process in a concise way. To learn such a DAG, we cast the learning problem as a continuous score-based optimization problem, which consists of a differentiable score function to measure the validity of the learned DAGs and a smooth acyclicity constraint to ensure the acyclicity of the learned DAGs. These two components are translated into an unconstraint augmented Lagrangian objective which could be minimized by mature continuous optimization techniques. The resulting algorithm, named GraphNOTEARS, outperforms baselines on simulated data across a wide range of settings that may encounter in real-world applications. We also apply the proposed approach on two dynamic graphs constructed from the real-world Yelp dataset, demonstrating our method could learn the connections between node features, which conforms with the domain knowledge.
Weakly Supervised Vessel Segmentation in X-ray Angiograms by Self-Paced Learning from Noisy Labels with Suggestive Annotation
May 27, 2020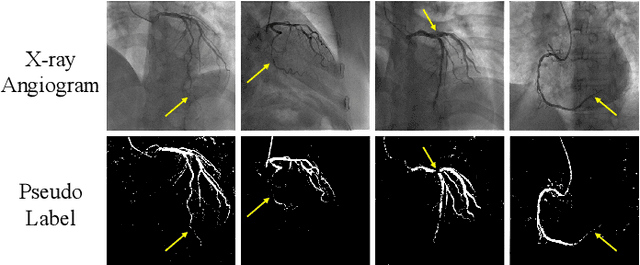
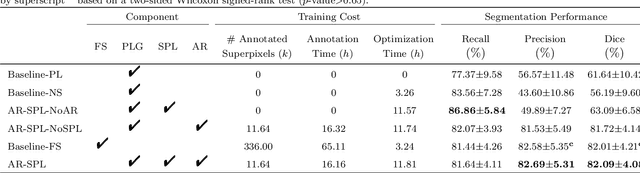
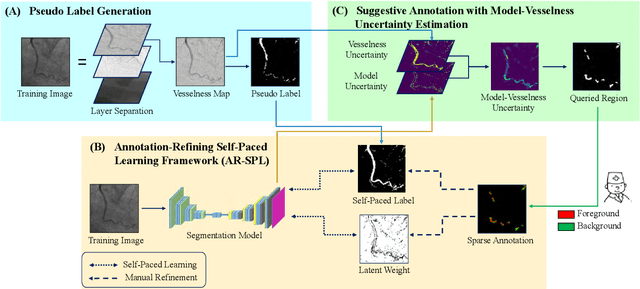
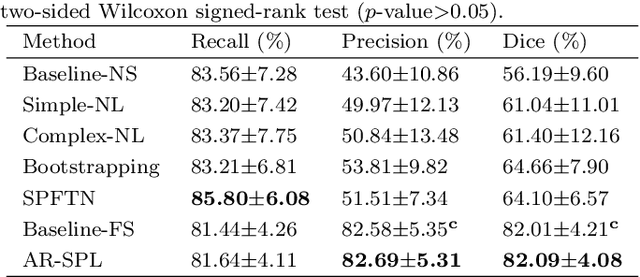
The segmentation of coronary arteries in X-ray angiograms by convolutional neural networks (CNNs) is promising yet limited by the requirement of precisely annotating all pixels in a large number of training images, which is extremely labor-intensive especially for complex coronary trees. To alleviate the burden on the annotator, we propose a novel weakly supervised training framework that learns from noisy pseudo labels generated from automatic vessel enhancement, rather than accurate labels obtained by fully manual annotation. A typical self-paced learning scheme is used to make the training process robust against label noise while challenged by the systematic biases in pseudo labels, thus leading to the decreased performance of CNNs at test time. To solve this problem, we propose an annotation-refining self-paced learning framework (AR-SPL) to correct the potential errors using suggestive annotation. An elaborate model-vesselness uncertainty estimation is also proposed to enable the minimal annotation cost for suggestive annotation, based on not only the CNNs in training but also the geometric features of coronary arteries derived directly from raw data. Experiments show that our proposed framework achieves 1) comparable accuracy to fully supervised learning, which also significantly outperforms other weakly supervised learning frameworks; 2) largely reduced annotation cost, i.e., 75.18% of annotation time is saved, and only 3.46% of image regions are required to be annotated; and 3) an efficient intervention process, leading to superior performance with even fewer manual interactions.