 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuadruped Parkour Learning: Sparsely Gated Mixture of Experts with Visual Input
Apr 21, 2026Robotic parkour provides a compelling benchmark for advancing locomotion over highly challenging terrain, including large discontinuities such as elevated steps. Recent approaches have demonstrated impressive capabilities, including dynamic climbing and jumping, but typically rely on sequential multilayer perceptron (MLP) architectures with densely activated layers. In contrast, sparsely gated mixture-of-experts (MoE) architectures have emerged in the large language model domain as an effective paradigm for improving scalability and performance by activating only a subset of parameters at inference time. In this work, we investigate the application of sparsely gated MoE architectures to vision-based robotic parkour. We compare control policies based on standard MLPs and MoE architectures under a controlled setting where the number of active parameters at inference time is matched. Experimental results on a real Unitree Go2 quadruped robot demonstrate clear performance gains, with the MoE policy achieving double the number of successful trials in traversing large obstacles compared to a standard MLP baseline. We further show that achieving comparable performance with a standard MLP requires scaling its parameter count to match that of the total MoE model, resulting in a 14.3\% increase in computation time. These results highlight that sparsely gated MoE architectures provide a favorable trade-off between performance and computational efficiency, enabling improved scaling of control policies for vision-based robotic parkour. An anonymized link to the codebase is https://osf.io/v2kqj/files/github?view_only=7977dee10c0a44769184498eaba72e44.
ATA: Bridging Implicit Reasoning with Attention-Guided and Action-Guided Inference for Vision-Language Action Models
Mar 02, 2026Vision-Language-Action (VLA) models rely on current observations, including images, language instructions, and robot states, to predict actions and complete tasks. While accurate visual perception is crucial for precise action prediction and execution, recent work has attempted to further improve performance by introducing explicit reasoning during inference. However, such approaches face significant limitations. They often depend on data-intensive resources such as Chain-of-Thought (CoT) style annotations to decompose tasks into step-by-step reasoning, and in many cases require additional visual grounding annotations (e.g., bounding boxes or masks) to highlight relevant image regions. Moreover, they involve time-consuming dataset construction, labeling, and retraining, which ultimately results in longer inference sequences and reduced efficiency. To address these challenges, we propose ATA, a novel training-free framework that introduces implicit reasoning into VLA inference through complementary attention-guided and action-guided strategies. Unlike CoT or explicit visual-grounding methods, ATA formulates reasoning implicitly by integrating attention maps with an action-based region of interest (RoI), thereby adaptively refining visual inputs without requiring extra training or annotations. ATA is a plug-and-play implicit reasoning approach for VLA models, lightweight yet effective. Extensive experiments show that it consistently improves task success and robustness while preserving, and even enhancing, inference efficiency.
SanD-Planner: Sample-Efficient Diffusion Planner in B-Spline Space for Robust Local Navigation
Jan 31, 2026The challenge of generating reliable local plans has long hindered practical applications in highly cluttered and dynamic environments. Key fundamental bottlenecks include acquiring large-scale expert demonstrations across diverse scenes and improving learning efficiency with limited data. This paper proposes SanD-Planner, a sample-efficient diffusion-based local planner that conducts depth image-based imitation learning within the clamped B-spline space. By operating within this compact space, the proposed algorithm inherently yields smooth outputs with bounded prediction errors over local supports, naturally aligning with receding-horizon execution. Integration of an ESDF-based safety checker with explicit clearance and time-to-completion metrics further reduces the training burden associated with value-function learning for feasibility assessment. Experiments show that training with $500$ episodes (merely $0.25\%$ of the demonstration scale used by the baseline), SanD-Planner achieves state-of-the-art performance on the evaluated open benchmark, attaining success rates of $90.1\%$ in simulated cluttered environments and $72.0\%$ in indoor simulations. The performance is further proven by demonstrating zero-shot transferability to realistic experimentation in both 2D and 3D scenes. The dataset and pre-trained models will also be open-sourced.
OpenNavMap: Structure-Free Topometric Mapping via Large-Scale Collaborative Localization
Jan 18, 2026Scalable and maintainable map representations are fundamental to enabling large-scale visual navigation and facilitating the deployment of robots in real-world environments. While collaborative localization across multi-session mapping enhances efficiency, traditional structure-based methods struggle with high maintenance costs and fail in feature-less environments or under significant viewpoint changes typical of crowd-sourced data. To address this, we propose OPENNAVMAP, a lightweight, structure-free topometric system leveraging 3D geometric foundation models for on-demand reconstruction. Our method unifies dynamic programming-based sequence matching, geometric verification, and confidence-calibrated optimization to robust, coarse-to-fine submap alignment without requiring pre-built 3D models. Evaluations on the Map-Free benchmark demonstrate superior accuracy over structure-from-motion and regression baselines, achieving an average translation error of 0.62m. Furthermore, the system maintains global consistency across 15km of multi-session data with an absolute trajectory error below 3m for map merging. Finally, we validate practical utility through 12 successful autonomous image-goal navigation tasks on simulated and physical robots. Code and datasets will be publicly available in https://rpl-cs-ucl.github.io/OpenNavMap_page.
The Starlink Robot: A Platform and Dataset for Mobile Satellite Communication
Jun 24, 2025The integration of satellite communication into mobile devices represents a paradigm shift in connectivity, yet the performance characteristics under motion and environmental occlusion remain poorly understood. We present the Starlink Robot, the first mobile robotic platform equipped with Starlink satellite internet, comprehensive sensor suite including upward-facing camera, LiDAR, and IMU, designed to systematically study satellite communication performance during movement. Our multi-modal dataset captures synchronized communication metrics, motion dynamics, sky visibility, and 3D environmental context across diverse scenarios including steady-state motion, variable speeds, and different occlusion conditions. This platform and dataset enable researchers to develop motion-aware communication protocols, predict connectivity disruptions, and optimize satellite communication for emerging mobile applications from smartphones to autonomous vehicles. The project is available at https://github.com/StarlinkRobot.
Event-Driven Dynamic Scene Depth Completion
May 19, 2025



Depth completion in dynamic scenes poses significant challenges due to rapid ego-motion and object motion, which can severely degrade the quality of input modalities such as RGB images and LiDAR measurements. Conventional RGB-D sensors often struggle to align precisely and capture reliable depth under such conditions. In contrast, event cameras with their high temporal resolution and sensitivity to motion at the pixel level provide complementary cues that are %particularly beneficial in dynamic environments.To this end, we propose EventDC, the first event-driven depth completion framework. It consists of two key components: Event-Modulated Alignment (EMA) and Local Depth Filtering (LDF). Both modules adaptively learn the two fundamental components of convolution operations: offsets and weights conditioned on motion-sensitive event streams. In the encoder, EMA leverages events to modulate the sampling positions of RGB-D features to achieve pixel redistribution for improved alignment and fusion. In the decoder, LDF refines depth estimations around moving objects by learning motion-aware masks from events. Additionally, EventDC incorporates two loss terms to further benefit global alignment and enhance local depth recovery. Moreover, we establish the first benchmark for event-based depth completion comprising one real-world and two synthetic datasets to facilitate future research. Extensive experiments on this benchmark demonstrate the superiority of our EventDC.
Follow Everything: A Leader-Following and Obstacle Avoidance Framework with Goal-Aware Adaptation
May 01, 2025



Robust and flexible leader-following is a critical capability for robots to integrate into human society. While existing methods struggle to generalize to leaders of arbitrary form and often fail when the leader temporarily leaves the robot's field of view, this work introduces a unified framework addressing both challenges. First, traditional detection models are replaced with a segmentation model, allowing the leader to be anything. To enhance recognition robustness, a distance frame buffer is implemented that stores leader embeddings at multiple distances, accounting for the unique characteristics of leader-following tasks. Second, a goal-aware adaptation mechanism is designed to govern robot planning states based on the leader's visibility and motion, complemented by a graph-based planner that generates candidate trajectories for each state, ensuring efficient following with obstacle avoidance. Simulations and real-world experiments with a legged robot follower and various leaders (human, ground robot, UAV, legged robot, stop sign) in both indoor and outdoor environments show competitive improvements in follow success rate, reduced visual loss duration, lower collision rate, and decreased leader-follower distance.
Watch Your STEPP: Semantic Traversability Estimation using Pose Projected Features
Jan 29, 2025Understanding the traversability of terrain is essential for autonomous robot navigation, particularly in unstructured environments such as natural landscapes. Although traditional methods, such as occupancy mapping, provide a basic framework, they often fail to account for the complex mobility capabilities of some platforms such as legged robots. In this work, we propose a method for estimating terrain traversability by learning from demonstrations of human walking. Our approach leverages dense, pixel-wise feature embeddings generated using the DINOv2 vision Transformer model, which are processed through an encoder-decoder MLP architecture to analyze terrain segments. The averaged feature vectors, extracted from the masked regions of interest, are used to train the model in a reconstruction-based framework. By minimizing reconstruction loss, the network distinguishes between familiar terrain with a low reconstruction error and unfamiliar or hazardous terrain with a higher reconstruction error. This approach facilitates the detection of anomalies, allowing a legged robot to navigate more effectively through challenging terrain. We run real-world experiments on the ANYmal legged robot both indoor and outdoor to prove our proposed method. The code is open-source, while video demonstrations can be found on our website: https://rpl-cs-ucl.github.io/STEPP
Real-Time Metric-Semantic Mapping for Autonomous Navigation in Outdoor Environments
Nov 30, 2024


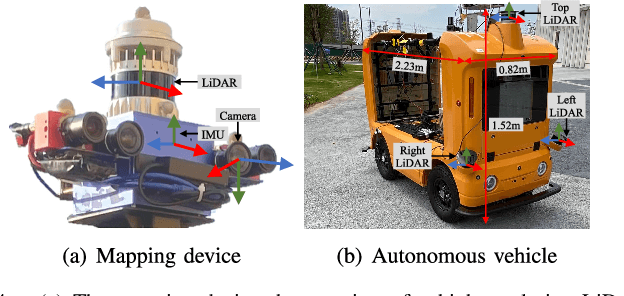
The creation of a metric-semantic map, which encodes human-prior knowledge, represents a high-level abstraction of environments. However, constructing such a map poses challenges related to the fusion of multi-modal sensor data, the attainment of real-time mapping performance, and the preservation of structural and semantic information consistency. In this paper, we introduce an online metric-semantic mapping system that utilizes LiDAR-Visual-Inertial sensing to generate a global metric-semantic mesh map of large-scale outdoor environments. Leveraging GPU acceleration, our mapping process achieves exceptional speed, with frame processing taking less than 7ms, regardless of scenario scale. Furthermore, we seamlessly integrate the resultant map into a real-world navigation system, enabling metric-semantic-based terrain assessment and autonomous point-to-point navigation within a campus environment. Through extensive experiments conducted on both publicly available and self-collected datasets comprising 24 sequences, we demonstrate the effectiveness of our mapping and navigation methodologies. Code has been publicly released: https://github.com/gogojjh/cobra
LoGS: Visual Localization via Gaussian Splatting with Fewer Training Images
Oct 15, 2024



Visual localization involves estimating a query image's 6-DoF (degrees of freedom) camera pose, which is a fundamental component in various computer vision and robotic tasks. This paper presents LoGS, a vision-based localization pipeline utilizing the 3D Gaussian Splatting (GS) technique as scene representation. This novel representation allows high-quality novel view synthesis. During the mapping phase, structure-from-motion (SfM) is applied first, followed by the generation of a GS map. During localization, the initial position is obtained through image retrieval, local feature matching coupled with a PnP solver, and then a high-precision pose is achieved through the analysis-by-synthesis manner on the GS map. Experimental results on four large-scale datasets demonstrate the proposed approach's SoTA accuracy in estimating camera poses and robustness under challenging few-shot conditions.