 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiteVLoc: Map-Lite Visual Localization for Image Goal Navigation
Oct 06, 2024



This paper presents LiteVLoc, a hierarchical visual localization framework that uses a lightweight topo-metric map to represent the environment. The method consists of three sequential modules that estimate camera poses in a coarse-to-fine manner. Unlike mainstream approaches relying on detailed 3D representations, LiteVLoc reduces storage overhead by leveraging learning-based feature matching and geometric solvers for metric pose estimation. A novel dataset for the map-free relocalization task is also introduced. Extensive experiments including localization and navigation in both simulated and real-world scenarios have validate the system's performance and demonstrated its precision and efficiency for large-scale deployment. Code and data will be made publicly available.
EgoHDM: An Online Egocentric-Inertial Human Motion Capture, Localization, and Dense Mapping System
Aug 31, 2024



We present EgoHDM, an online egocentric-inertial human motion capture (mocap), localization, and dense mapping system. Our system uses 6 inertial measurement units (IMUs) and a commodity head-mounted RGB camera. EgoHDM is the first human mocap system that offers dense scene mapping in near real-time. Further, it is fast and robust to initialize and fully closes the loop between physically plausible map-aware global human motion estimation and mocap-aware 3D scene reconstruction. Our key idea is integrating camera localization and mapping information with inertial human motion capture bidirectionally in our system. To achieve this, we design a tightly coupled mocap-aware dense bundle adjustment and physics-based body pose correction module leveraging a local body-centric elevation map. The latter introduces a novel terrain-aware contact PD controller, which enables characters to physically contact the given local elevation map thereby reducing human floating or penetration. We demonstrate the performance of our system on established synthetic and real-world benchmarks. The results show that our method reduces human localization, camera pose, and mapping accuracy error by 41%, 71%, 46%, respectively, compared to the state of the art. Our qualitative evaluations on newly captured data further demonstrate that EgoHDM can cover challenging scenarios in non-flat terrain including stepping over stairs and outdoor scenes in the wild.
Efficient Camera Exposure Control for Visual Odometry via Deep Reinforcement Learning
Aug 30, 2024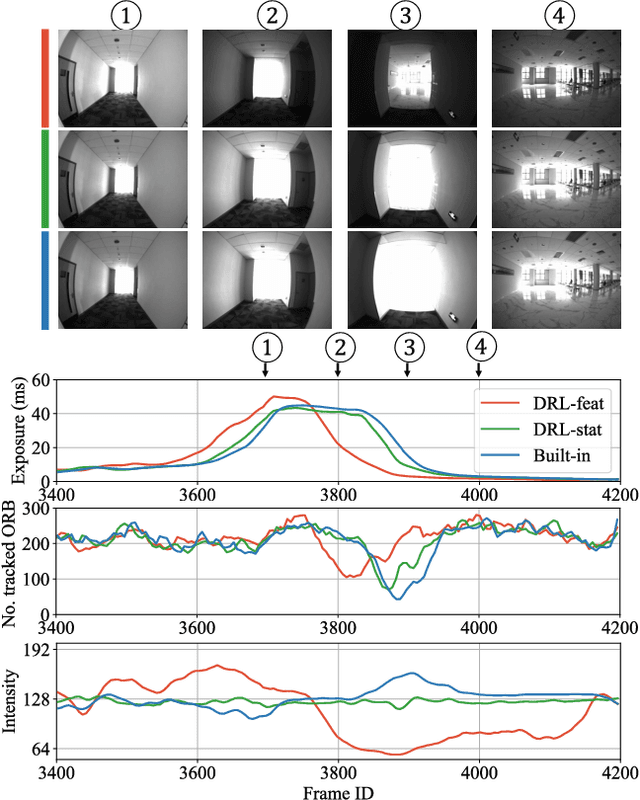
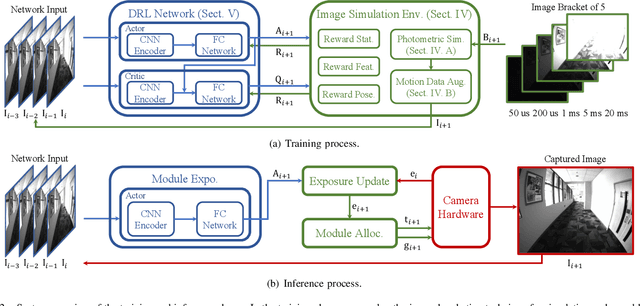
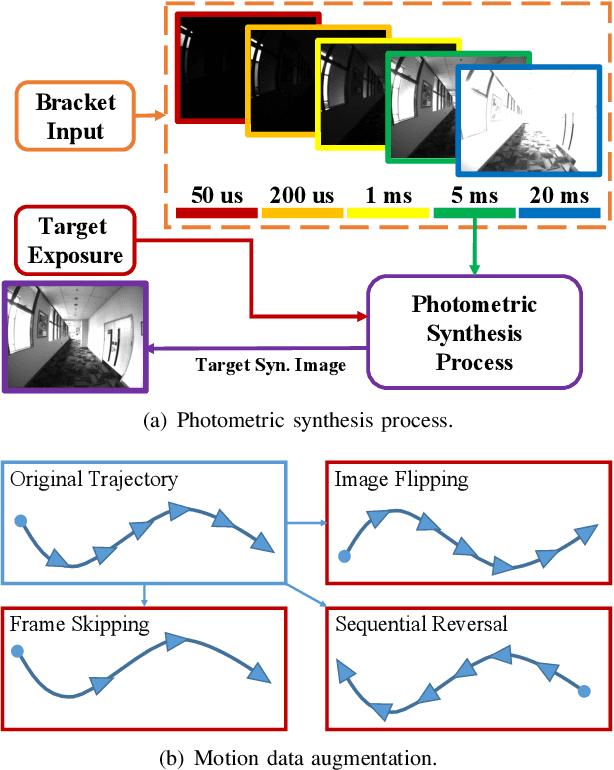

The stability of visual odometry (VO) systems is undermined by degraded image quality, especially in environments with significant illumination changes. This study employs a deep reinforcement learning (DRL) framework to train agents for exposure control, aiming to enhance imaging performance in challenging conditions. A lightweight image simulator is developed to facilitate the training process, enabling the diversification of image exposure and sequence trajectory. This setup enables completely offline training, eliminating the need for direct interaction with camera hardware and the real environments. Different levels of reward functions are crafted to enhance the VO systems, equipping the DRL agents with varying intelligence. Extensive experiments have shown that our exposure control agents achieve superior efficiency-with an average inference duration of 1.58 ms per frame on a CPU-and respond more quickly than traditional feedback control schemes. By choosing an appropriate reward function, agents acquire an intelligent understanding of motion trends and anticipate future illumination changes. This predictive capability allows VO systems to deliver more stable and precise odometry results. The codes and datasets are available at https://github.com/ShuyangUni/drl_exposure_ctrl.
Accurate Prior-centric Monocular Positioning with Offline LiDAR Fusion
Jul 12, 2024Unmanned vehicles usually rely on Global Positioning System (GPS) and Light Detection and Ranging (LiDAR) sensors to achieve high-precision localization results for navigation purpose. However, this combination with their associated costs and infrastructure demands, poses challenges for widespread adoption in mass-market applications. In this paper, we aim to use only a monocular camera to achieve comparable onboard localization performance by tracking deep-learning visual features on a LiDAR-enhanced visual prior map. Experiments show that the proposed algorithm can provide centimeter-level global positioning results with scale, which is effortlessly integrated and favorable for low-cost robot system deployment in real-world applications.