 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccurate Prior-centric Monocular Positioning with Offline LiDAR Fusion
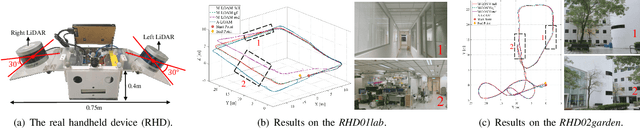
Jul 12, 2024Unmanned vehicles usually rely on Global Positioning System (GPS) and Light Detection and Ranging (LiDAR) sensors to achieve high-precision localization results for navigation purpose. However, this combination with their associated costs and infrastructure demands, poses challenges for widespread adoption in mass-market applications. In this paper, we aim to use only a monocular camera to achieve comparable onboard localization performance by tracking deep-learning visual features on a LiDAR-enhanced visual prior map. Experiments show that the proposed algorithm can provide centimeter-level global positioning results with scale, which is effortlessly integrated and favorable for low-cost robot system deployment in real-world applications.
FSNet: Redesign Self-Supervised MonoDepth for Full-Scale Depth Prediction for Autonomous Driving
Apr 21, 2023Predicting accurate depth with monocular images is important for low-cost robotic applications and autonomous driving. This study proposes a comprehensive self-supervised framework for accurate scale-aware depth prediction on autonomous driving scenes utilizing inter-frame poses obtained from inertial measurements. In particular, we introduce a Full-Scale depth prediction network named FSNet. FSNet contains four important improvements over existing self-supervised models: (1) a multichannel output representation for stable training of depth prediction in driving scenarios, (2) an optical-flow-based mask designed for dynamic object removal, (3) a self-distillation training strategy to augment the training process, and (4) an optimization-based post-processing algorithm in test time, fusing the results from visual odometry. With this framework, robots and vehicles with only one well-calibrated camera can collect sequences of training image frames and camera poses, and infer accurate 3D depths of the environment without extra labeling work or 3D data. Extensive experiments on the KITTI dataset, KITTI-360 dataset and the nuScenes dataset demonstrate the potential of FSNet. More visualizations are presented in \url{https://sites.google.com/view/fsnet/home}
FusionPortable: A Multi-Sensor Campus-Scene Dataset for Evaluation of Localization and Mapping Accuracy on Diverse Platforms
Aug 25, 2022

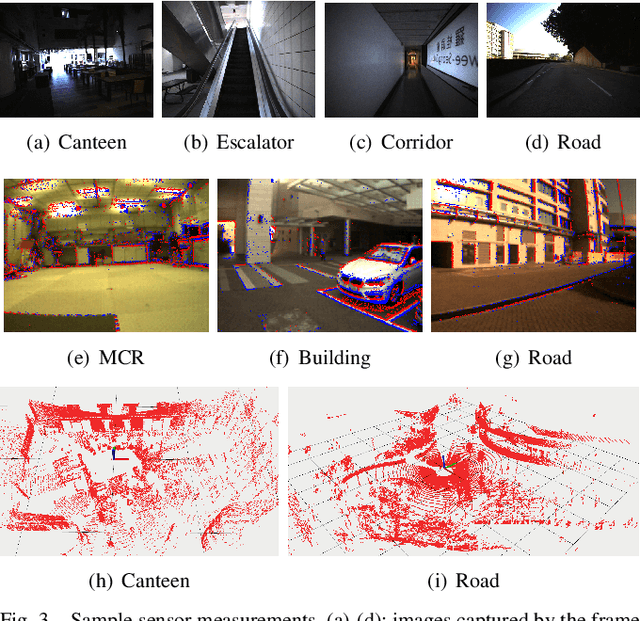

Combining multiple sensors enables a robot to maximize its perceptual awareness of environments and enhance its robustness to external disturbance, crucial to robotic navigation. This paper proposes the FusionPortable benchmark, a complete multi-sensor dataset with a diverse set of sequences for mobile robots. This paper presents three contributions. We first advance a portable and versatile multi-sensor suite that offers rich sensory measurements: 10Hz LiDAR point clouds, 20Hz stereo frame images, high-rate and asynchronous events from stereo event cameras, 200Hz inertial readings from an IMU, and 10Hz GPS signal. Sensors are already temporally synchronized in hardware. This device is lightweight, self-contained, and has plug-and-play support for mobile robots. Second, we construct a dataset by collecting 17 sequences that cover a variety of environments on the campus by exploiting multiple robot platforms for data collection. Some sequences are challenging to existing SLAM algorithms. Third, we provide ground truth for the decouple localization and mapping performance evaluation. We additionally evaluate state-of-the-art SLAM approaches and identify their limitations. The dataset, consisting of raw sensor easurements, ground truth, calibration data, and evaluated algorithms, will be released: https://ram-lab.com/file/site/multi-sensor-dataset.
On Bundle Adjustment for Multiview PointCloud Registration
Aug 06, 2021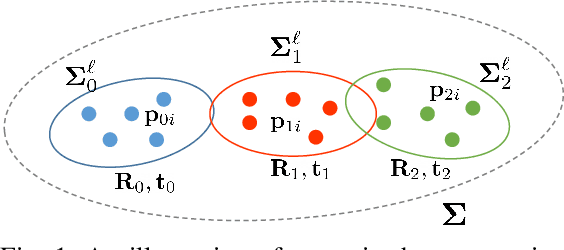
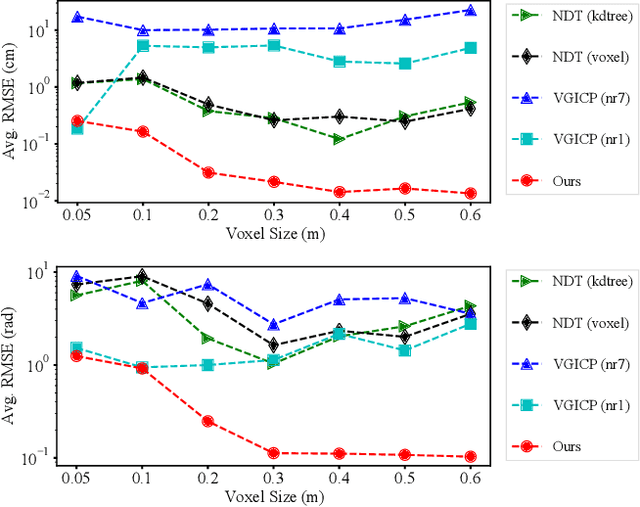
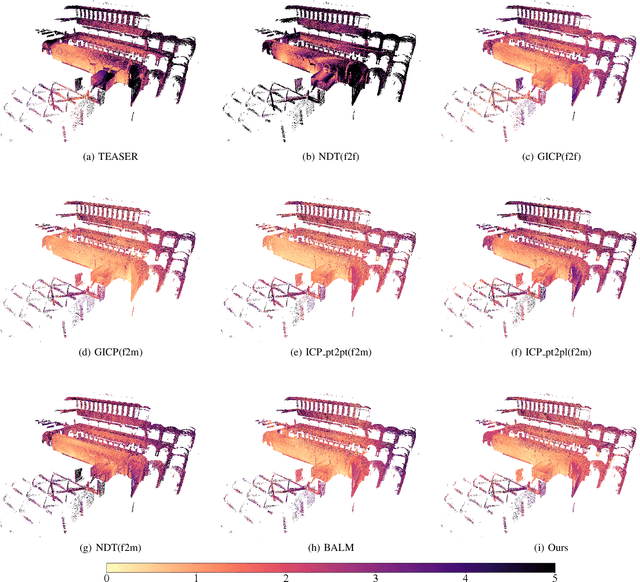
Multiview registration is used to estimate Rigid Body Transformations (RBTs) from multiple frames and reconstruct a scene with corresponding scans. Despite the success of pairwise registration and pose synchronization, the concept of Bundle Adjustment (BA) has been proven to better maintain global consistency. So in this work, we make the multiview point-cloud registration more tractable from a different perspective in resolving range-based BA. Based on this analysis, we propose an objective function that takes both measurement noises and computational cost into account. For the feature parameter update, instead of calculating the global distribution parameters from the raw measurements, we aggregate the local distributions upon the pose update at each iteration. The computational cost of feature update is then only dependent on the number of scans. Finally, we develop a multiview registration system using voxel-based quantization that can be applied in real-world scenarios. The experimental results demonstrate our superiority over the baselines in terms of both accuracy and speed. Moreover, the results also show that our average positioning errors achieve the centimeter level.
Incorporating Learnt Local and Global Embeddings into Monocular Visual SLAM
Aug 04, 2021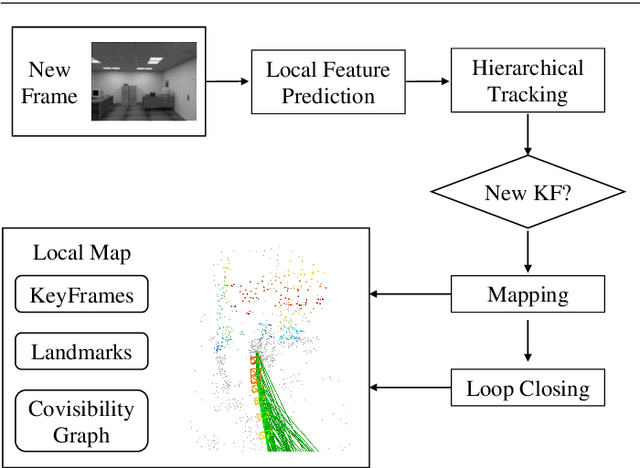

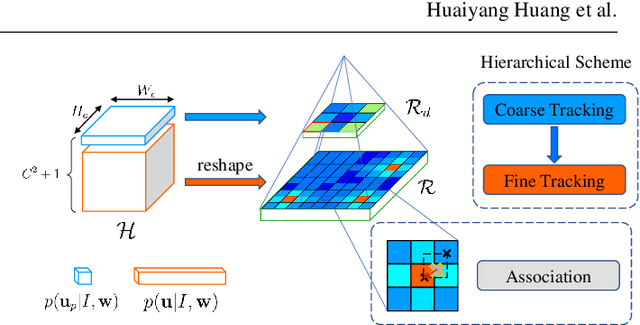
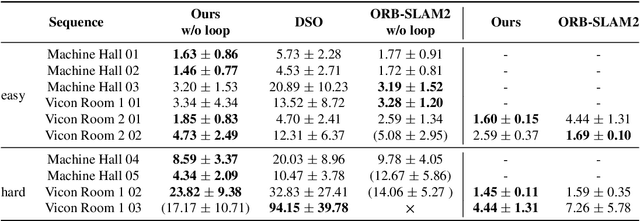
Traditional approaches for Visual Simultaneous Localization and Mapping (VSLAM) rely on low-level vision information for state estimation, such as handcrafted local features or the image gradient. While significant progress has been made through this track, under more challenging configuration for monocular VSLAM, e.g., varying illumination, the performance of state-of-the-art systems generally degrades. As a consequence, robustness and accuracy for monocular VSLAM are still widely concerned. This paper presents a monocular VSLAM system that fully exploits learnt features for better state estimation. The proposed system leverages both learnt local features and global embeddings at different modules of the system: direct camera pose estimation, inter-frame feature association, and loop closure detection. With a probabilistic explanation of keypoint prediction, we formulate the camera pose tracking in a direct manner and parameterize local features with uncertainty taken into account. To alleviate the quantization effect, we adapt the mapping module to generate 3D landmarks better to guarantee the system's robustness. Detecting temporal loop closure via deep global embeddings further improves the robustness and accuracy of the proposed system. The proposed system is extensively evaluated on public datasets (Tsukuba, EuRoC, and KITTI), and compared against the state-of-the-art methods. The competitive performance of camera pose estimation confirms the effectiveness of our method.
Vision-Based Autonomous Car Racing Using Deep Imitative Reinforcement Learning
Jul 18, 2021
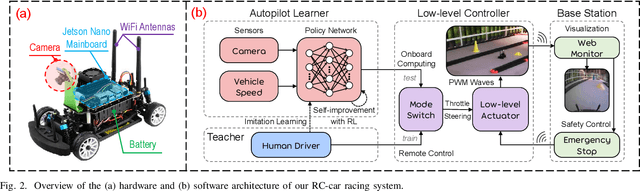

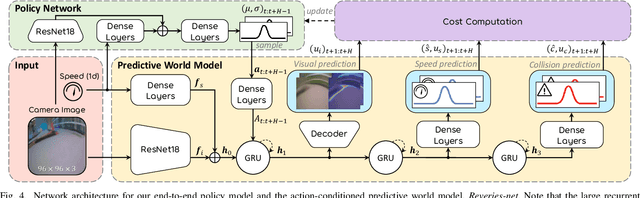
Autonomous car racing is a challenging task in the robotic control area. Traditional modular methods require accurate mapping, localization and planning, which makes them computationally inefficient and sensitive to environmental changes. Recently, deep-learning-based end-to-end systems have shown promising results for autonomous driving/racing. However, they are commonly implemented by supervised imitation learning (IL), which suffers from the distribution mismatch problem, or by reinforcement learning (RL), which requires a huge amount of risky interaction data. In this work, we present a general deep imitative reinforcement learning approach (DIRL), which successfully achieves agile autonomous racing using visual inputs. The driving knowledge is acquired from both IL and model-based RL, where the agent can learn from human teachers as well as perform self-improvement by safely interacting with an offline world model. We validate our algorithm both in a high-fidelity driving simulation and on a real-world 1/20-scale RC-car with limited onboard computation. The evaluation results demonstrate that our method outperforms previous IL and RL methods in terms of sample efficiency and task performance. Demonstration videos are available at https://caipeide.github.io/autorace-dirl/
Comparing Representations in Tracking for Event Camera-based SLAM
Apr 20, 2021
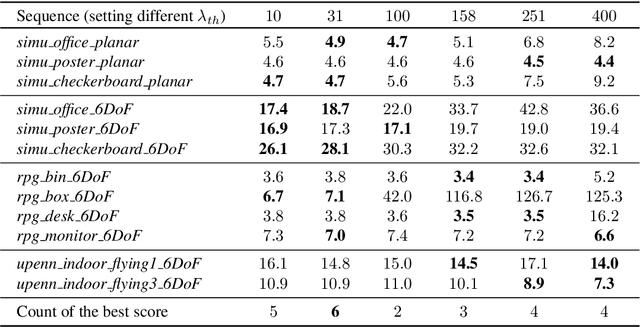

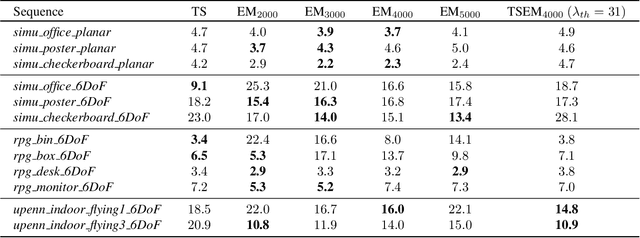
This paper investigates two typical image-type representations for event camera-based tracking: time surface (TS) and event map (EM). Based on the original TS-based tracker, we make use of these two representations' complementary strengths to develop an enhanced version. The proposed tracker consists of a general strategy to evaluate the optimization problem's degeneracy online and then switch proper representations. Both TS and EM are motion- and scene-dependent, and thus it is important to figure out their limitations in tracking. We develop six tracker variations and conduct a thorough comparison of them on sequences covering various scenarios and motion complexities. We release our implementations and detailed results to benefit the research community on event cameras: https: //github.com/gogojjh/ESVO_extension.
3D Surfel Map-Aided Visual Relocalization with Learned Descriptors
Apr 08, 2021
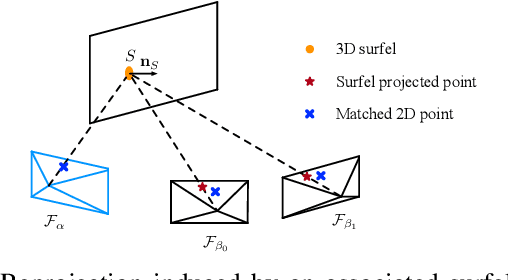


In this paper, we introduce a method for visual relocalization using the geometric information from a 3D surfel map. A visual database is first built by global indices from the 3D surfel map rendering, which provides associations between image points and 3D surfels. Surfel reprojection constraints are utilized to optimize the keyframe poses and map points in the visual database. A hierarchical camera relocalization algorithm then utilizes the visual database to estimate 6-DoF camera poses. Learned descriptors are further used to improve the performance in challenging cases. We present evaluation under real-world conditions and simulation to show the effectiveness and efficiency of our method, and make the final camera poses consistently well aligned with the 3D environment.
Greedy-Based Feature Selection for Efficient LiDAR SLAM
Mar 24, 2021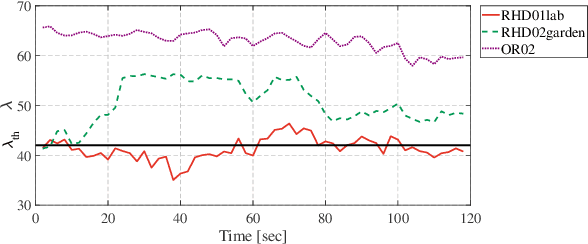
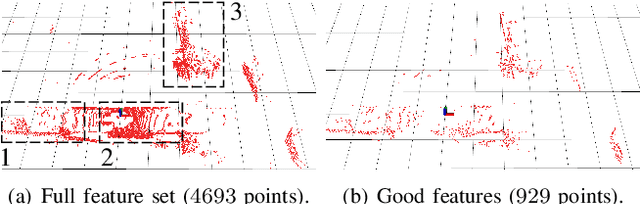
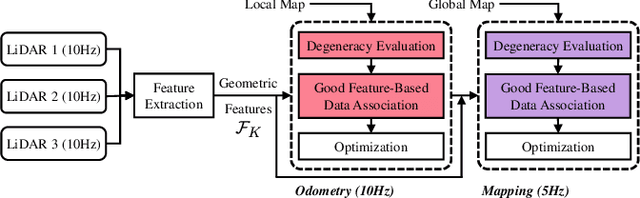
Modern LiDAR-SLAM (L-SLAM) systems have shown excellent results in large-scale, real-world scenarios. However, they commonly have a high latency due to the expensive data association and nonlinear optimization. This paper demonstrates that actively selecting a subset of features significantly improves both the accuracy and efficiency of an L-SLAM system. We formulate the feature selection as a combinatorial optimization problem under a cardinality constraint to preserve the information matrix's spectral attributes. The stochastic-greedy algorithm is applied to approximate the optimal results in real-time. To avoid ill-conditioned estimation, we also propose a general strategy to evaluate the environment's degeneracy and modify the feature number online. The proposed feature selector is integrated into a multi-LiDAR SLAM system. We validate this enhanced system with extensive experiments covering various scenarios on two sensor setups and computation platforms. We show that our approach exhibits low localization error and speedup compared to the state-of-the-art L-SLAM systems. To benefit the community, we have released the source code: https://ram-lab.com/file/site/m-loam.
Geometric Structure Aided Visual Inertial Localization
Nov 09, 2020


Visual Localization is an essential component in autonomous navigation. Existing approaches are either based on the visual structure from SLAM/SfM or the geometric structure from dense mapping. To take the advantages of both, in this work, we present a complete visual inertial localization system based on a hybrid map representation to reduce the computational cost and increase the positioning accuracy. Specially, we propose two modules for data association and batch optimization, respectively. To this end, we develop an efficient data association module to associate map components with local features, which takes only $2$ms to generate temporal landmarks. For batch optimization, instead of using visual factors, we develop a module to estimate a pose prior from the instant localization results to constrain poses. The experimental results on the EuRoC MAV dataset demonstrate a competitive performance compared to the state of the arts. Specially, our system achieves an average position error in 1.7 cm with 100% recall. The timings show that the proposed modules reduce the computational cost by 20-30%. We will make our implementation open source at http://github.com/hyhuang1995/gmmloc.