 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCarl-Lead: Lidar-based End-to-End Autonomous Driving with Contrastive Deep Reinforcement Learning
Sep 17, 2021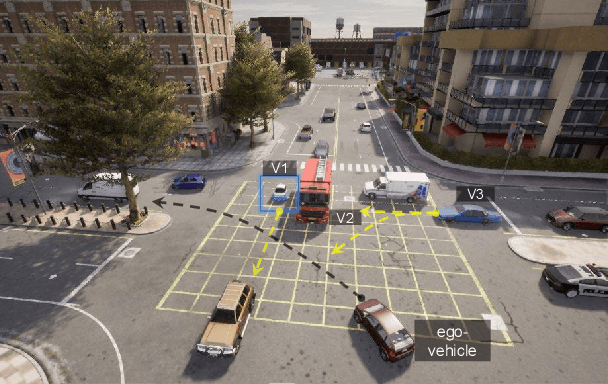
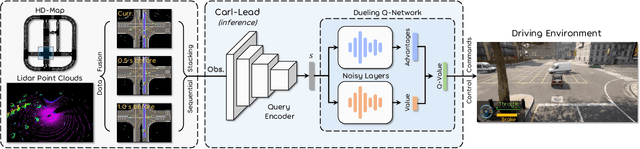
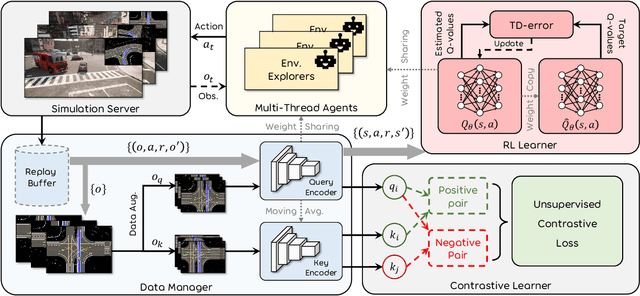
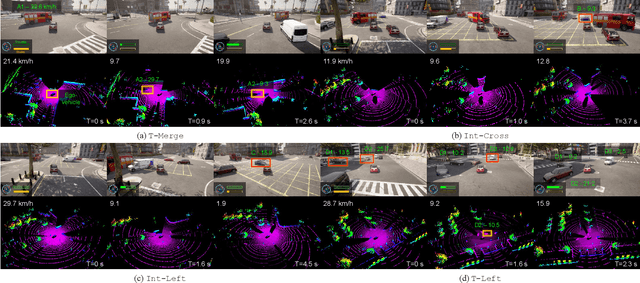
Autonomous driving in urban crowds at unregulated intersections is challenging, where dynamic occlusions and uncertain behaviors of other vehicles should be carefully considered. Traditional methods are heuristic and based on hand-engineered rules and parameters, but scale poorly in new situations. Therefore, they require high labor cost to design and maintain rules in all foreseeable scenarios. Recently, deep reinforcement learning (DRL) has shown promising results in urban driving scenarios. However, DRL is known to be sample inefficient, and most previous works assume perfect observations such as ground-truth locations and motions of vehicles without considering noises and occlusions, which might be a too strong assumption for policy deployment. In this work, we use DRL to train lidar-based end-to-end driving policies that naturally consider imperfect partial observations. We further use unsupervised contrastive representation learning as an auxiliary task to improve the sample efficiency. The comparative evaluation results reveal that our method achieves higher success rates than the state-of-the-art (SOTA) lidar-based end-to-end driving network, better trades off safety and efficiency than the carefully tuned rule-based method, and generalizes better to new scenarios than the baselines. Demo videos are available at https://caipeide.github.io/carl-lead/.
Graph Attention Layer Evolves Semantic Segmentation for Road Pothole Detection: A Benchmark and Algorithms
Sep 06, 2021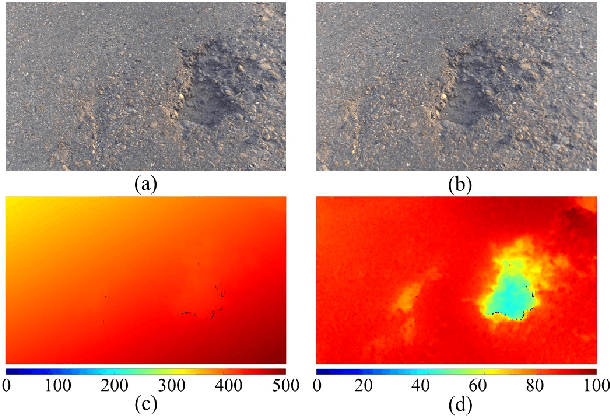
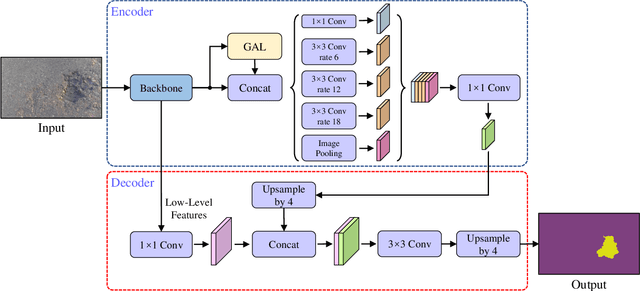
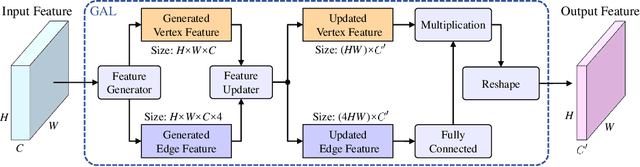
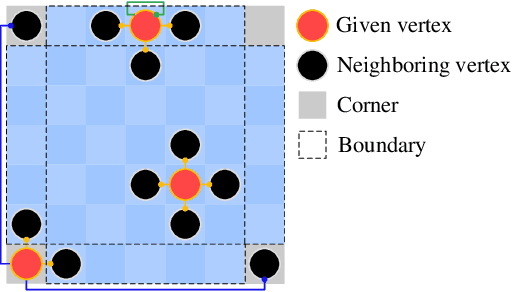
Existing road pothole detection approaches can be classified as computer vision-based or machine learning-based. The former approaches typically employ 2-D image analysis/understanding or 3-D point cloud modeling and segmentation algorithms to detect road potholes from vision sensor data. The latter approaches generally address road pothole detection using convolutional neural networks (CNNs) in an end-to-end manner. However, road potholes are not necessarily ubiquitous and it is challenging to prepare a large well-annotated dataset for CNN training. In this regard, while computer vision-based methods were the mainstream research trend in the past decade, machine learning-based methods were merely discussed. Recently, we published the first stereo vision-based road pothole detection dataset and a novel disparity transformation algorithm, whereby the damaged and undamaged road areas can be highly distinguished. However, there are no benchmarks currently available for state-of-the-art (SoTA) CNNs trained using either disparity images or transformed disparity images. Therefore, in this paper, we first discuss the SoTA CNNs designed for semantic segmentation and evaluate their performance for road pothole detection with extensive experiments. Additionally, inspired by graph neural network (GNN), we propose a novel CNN layer, referred to as graph attention layer (GAL), which can be easily deployed in any existing CNN to optimize image feature representations for semantic segmentation. Our experiments compare GAL-DeepLabv3+, our best-performing implementation, with nine SoTA CNNs on three modalities of training data: RGB images, disparity images, and transformed disparity images. The experimental results suggest that our proposed GAL-DeepLabv3+ achieves the best overall pothole detection accuracy on all training data modalities.
DQ-GAT: Towards Safe and Efficient Autonomous Driving with Deep Q-Learning and Graph Attention Networks
Aug 11, 2021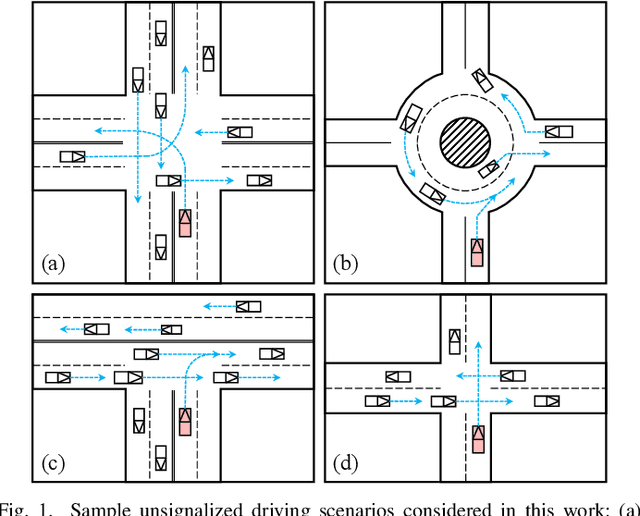


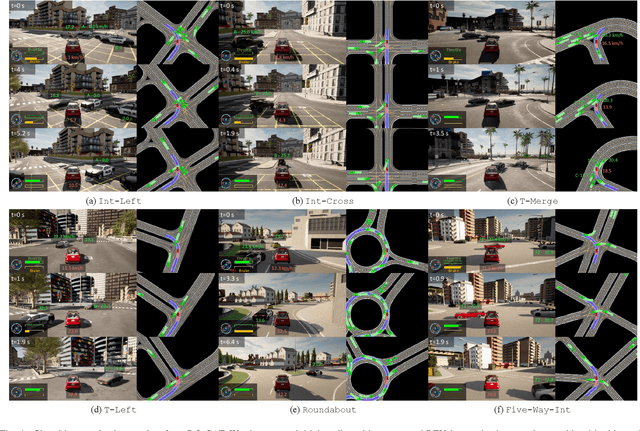
Autonomous driving in multi-agent and dynamic traffic scenarios is challenging, where the behaviors of other road agents are uncertain and hard to model explicitly, and the ego-vehicle should apply complicated negotiation skills with them to achieve both safe and efficient driving in various settings, such as giving way, merging and taking turns. Traditional planning methods are largely rule-based and scale poorly in these complex dynamic scenarios, often leading to reactive or even overly conservative behaviors. Therefore, they require tedious human efforts to maintain workability. Recently, deep learning-based methods have shown promising results with better generalization capability but less hand engineering effort. However, they are either implemented with supervised imitation learning (IL) that suffers from the dataset bias and distribution mismatch problems, or trained with deep reinforcement learning (DRL) but focus on one specific traffic scenario. In this work, we propose DQ-GAT to achieve scalable and proactive autonomous driving, where graph attention-based networks are used to implicitly model interactions, and asynchronous deep Q-learning is employed to train the network end-to-end in an unsupervised manner. Extensive experiments through a high-fidelity driving simulation show that our method can better trade-off safety and efficiency in both seen and unseen scenarios, achieving higher goal success rates than the baselines (at most 4.7$\times$) with comparable task completion time. Demonstration videos are available at https://caipeide.github.io/dq-gat/.
SNE-RoadSeg+: Rethinking Depth-Normal Translation and Deep Supervision for Freespace Detection
Jul 30, 2021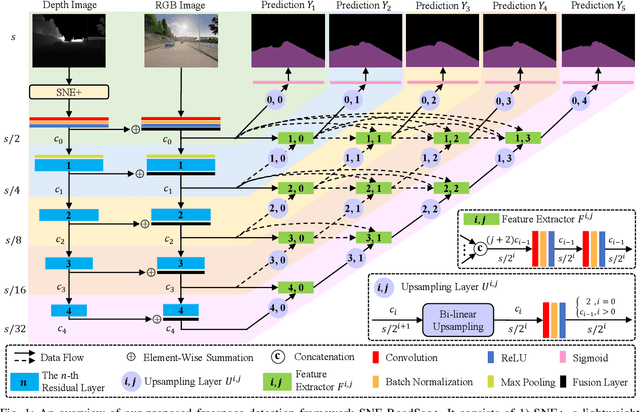

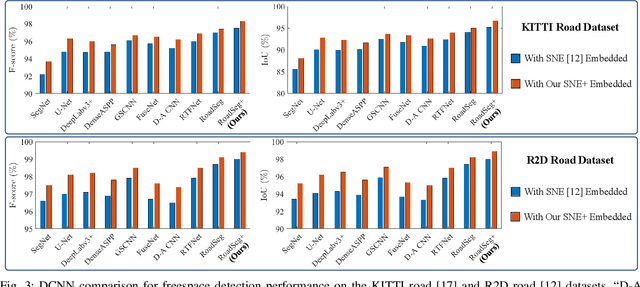

Freespace detection is a fundamental component of autonomous driving perception. Recently, deep convolutional neural networks (DCNNs) have achieved impressive performance for this task. In particular, SNE-RoadSeg, our previously proposed method based on a surface normal estimator (SNE) and a data-fusion DCNN (RoadSeg), has achieved impressive performance in freespace detection. However, SNE-RoadSeg is computationally intensive, and it is difficult to execute in real time. To address this problem, we introduce SNE-RoadSeg+, an upgraded version of SNE-RoadSeg. SNE-RoadSeg+ consists of 1) SNE+, a module for more accurate surface normal estimation, and 2) RoadSeg+, a data-fusion DCNN that can greatly minimize the trade-off between accuracy and efficiency with the use of deep supervision. Extensive experimental results have demonstrated the effectiveness of our SNE+ for surface normal estimation and the superior performance of our SNE-RoadSeg+ over all other freespace detection approaches. Specifically, our SNE-RoadSeg+ runs in real time, and meanwhile, achieves the state-of-the-art performance on the KITTI road benchmark. Our project page is at https://www.sne-roadseg.site/sne-roadseg-plus.
Vision-Based Autonomous Car Racing Using Deep Imitative Reinforcement Learning
Jul 18, 2021
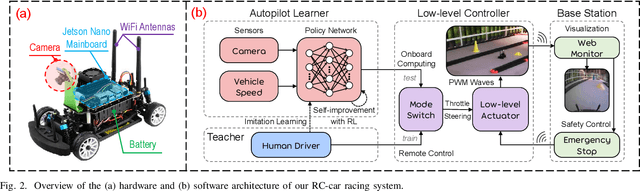

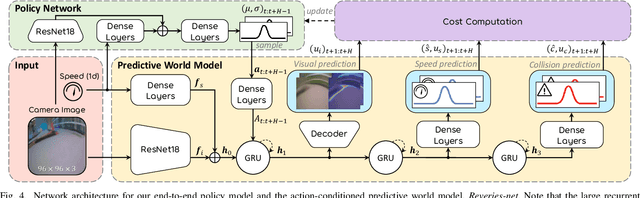
Autonomous car racing is a challenging task in the robotic control area. Traditional modular methods require accurate mapping, localization and planning, which makes them computationally inefficient and sensitive to environmental changes. Recently, deep-learning-based end-to-end systems have shown promising results for autonomous driving/racing. However, they are commonly implemented by supervised imitation learning (IL), which suffers from the distribution mismatch problem, or by reinforcement learning (RL), which requires a huge amount of risky interaction data. In this work, we present a general deep imitative reinforcement learning approach (DIRL), which successfully achieves agile autonomous racing using visual inputs. The driving knowledge is acquired from both IL and model-based RL, where the agent can learn from human teachers as well as perform self-improvement by safely interacting with an offline world model. We validate our algorithm both in a high-fidelity driving simulation and on a real-world 1/20-scale RC-car with limited onboard computation. The evaluation results demonstrate that our method outperforms previous IL and RL methods in terms of sample efficiency and task performance. Demonstration videos are available at https://caipeide.github.io/autorace-dirl/
SCV-Stereo: Learning Stereo Matching from a Sparse Cost Volume
Jul 17, 2021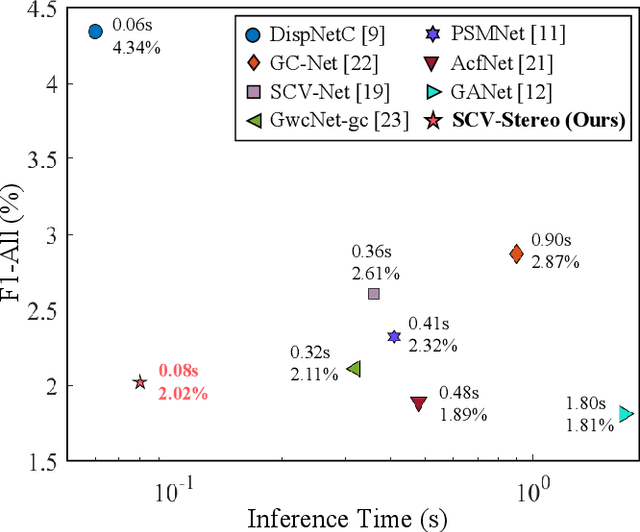
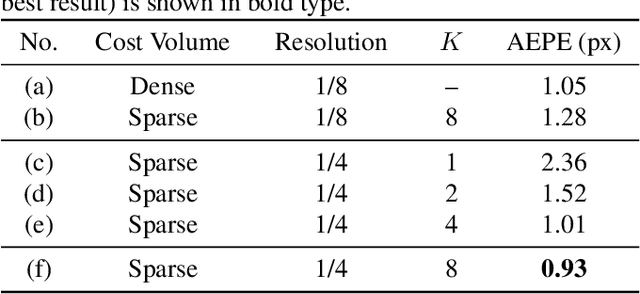
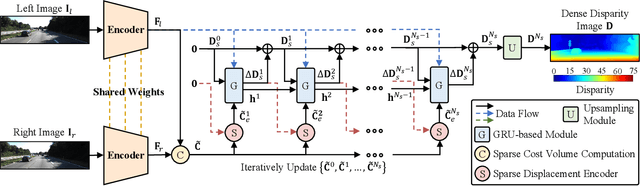
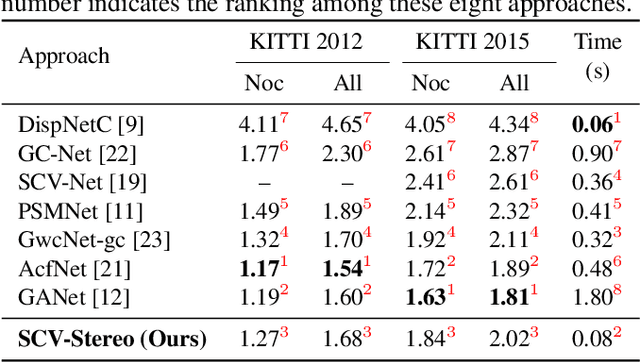
Convolutional neural network (CNN)-based stereo matching approaches generally require a dense cost volume (DCV) for disparity estimation. However, generating such cost volumes is computationally-intensive and memory-consuming, hindering CNN training and inference efficiency. To address this problem, we propose SCV-Stereo, a novel CNN architecture, capable of learning dense stereo matching from sparse cost volume (SCV) representations. Our inspiration is derived from the fact that DCV representations are somewhat redundant and can be replaced with SCV representations. Benefiting from these SCV representations, our SCV-Stereo can update disparity estimations in an iterative fashion for accurate and efficient stereo matching. Extensive experiments carried out on the KITTI Stereo benchmarks demonstrate that our SCV-Stereo can significantly minimize the trade-off between accuracy and efficiency for stereo matching. Our project page is https://sites.google.com/view/scv-stereo.
Co-Teaching: An Ark to Unsupervised Stereo Matching
Jul 17, 2021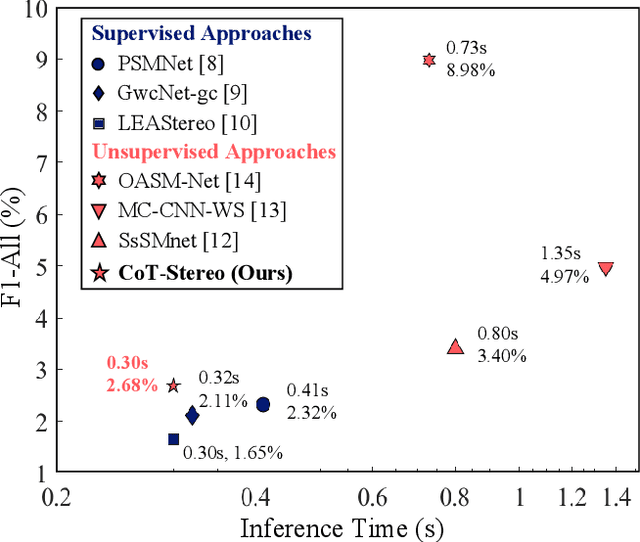
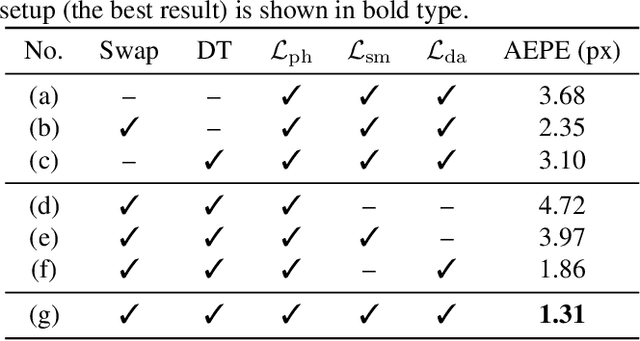
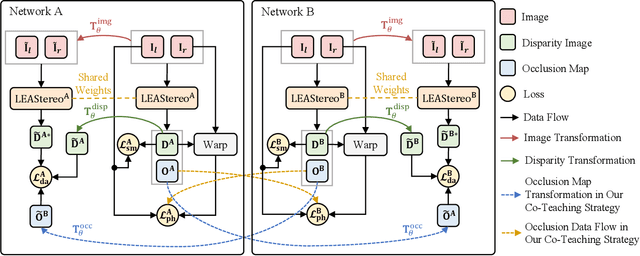

Stereo matching is a key component of autonomous driving perception. Recent unsupervised stereo matching approaches have received adequate attention due to their advantage of not requiring disparity ground truth. These approaches, however, perform poorly near occlusions. To overcome this drawback, in this paper, we propose CoT-Stereo, a novel unsupervised stereo matching approach. Specifically, we adopt a co-teaching framework where two networks interactively teach each other about the occlusions in an unsupervised fashion, which greatly improves the robustness of unsupervised stereo matching. Extensive experiments on the KITTI Stereo benchmarks demonstrate the superior performance of CoT-Stereo over all other state-of-the-art unsupervised stereo matching approaches in terms of both accuracy and speed. Our project webpage is https://sites.google.com/view/cot-stereo.
End-to-End Interactive Prediction and Planning with Optical Flow Distillation for Autonomous Driving
Apr 18, 2021
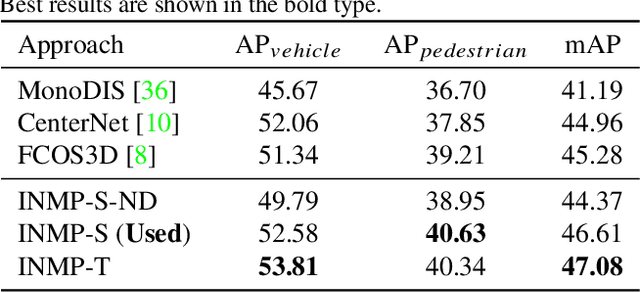
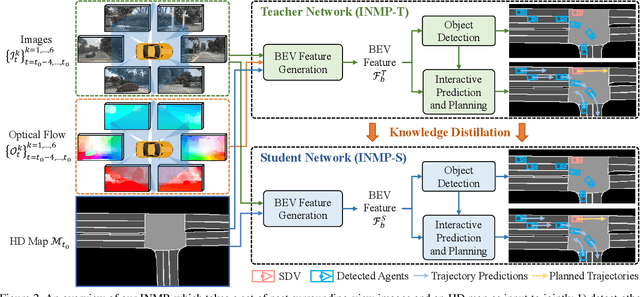
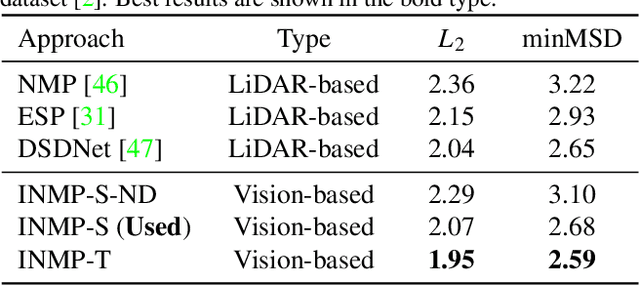
With the recent advancement of deep learning technology, data-driven approaches for autonomous car prediction and planning have achieved extraordinary performance. Nevertheless, most of these approaches follow a non-interactive prediction and planning paradigm, hypothesizing that a vehicle's behaviors do not affect others. The approaches based on such a non-interactive philosophy typically perform acceptably in sparse traffic scenarios but can easily fail in dense traffic scenarios. Therefore, we propose an end-to-end interactive neural motion planner (INMP) for autonomous driving in this paper. Given a set of past surrounding-view images and a high definition map, our INMP first generates a feature map in bird's-eye-view space, which is then processed to detect other agents and perform interactive prediction and planning jointly. Also, we adopt an optical flow distillation paradigm, which can effectively improve the network performance while still maintaining its real-time inference speed. Extensive experiments on the nuScenes dataset and in the closed-loop Carla simulation environment demonstrate the effectiveness and efficiency of our INMP for the detection, prediction, and planning tasks. Our project page is at sites.google.com/view/inmp-ofd.
Learning Interpretable End-to-End Vision-Based Motion Planning for Autonomous Driving with Optical Flow Distillation
Apr 18, 2021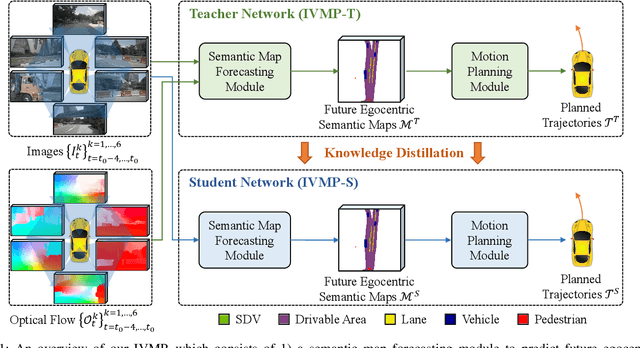
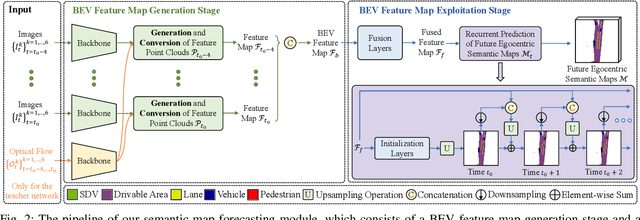

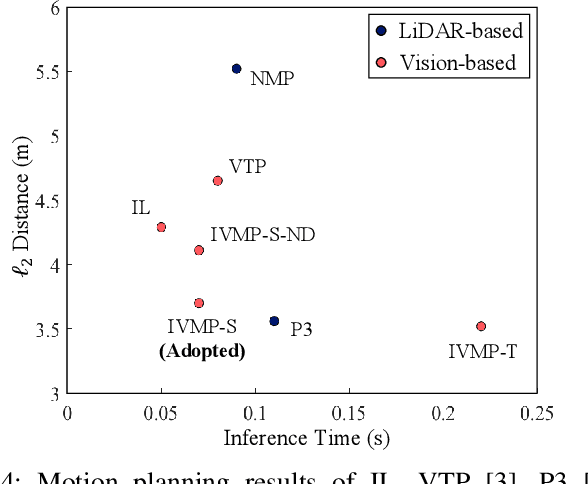
Recently, deep-learning based approaches have achieved impressive performance for autonomous driving. However, end-to-end vision-based methods typically have limited interpretability, making the behaviors of the deep networks difficult to explain. Hence, their potential applications could be limited in practice. To address this problem, we propose an interpretable end-to-end vision-based motion planning approach for autonomous driving, referred to as IVMP. Given a set of past surrounding-view images, our IVMP first predicts future egocentric semantic maps in bird's-eye-view space, which are then employed to plan trajectories for self-driving vehicles. The predicted future semantic maps not only provide useful interpretable information, but also allow our motion planning module to handle objects with low probability, thus improving the safety of autonomous driving. Moreover, we also develop an optical flow distillation paradigm, which can effectively enhance the network while still maintaining its real-time performance. Extensive experiments on the nuScenes dataset and closed-loop simulation show that our IVMP significantly outperforms the state-of-the-art approaches in imitating human drivers with a much higher success rate. Our project page is available at https://sites.google.com/view/ivmp.
S2P2: Self-Supervised Goal-Directed Path Planning Using RGB-D Data for Robotic Wheelchairs
Mar 18, 2021
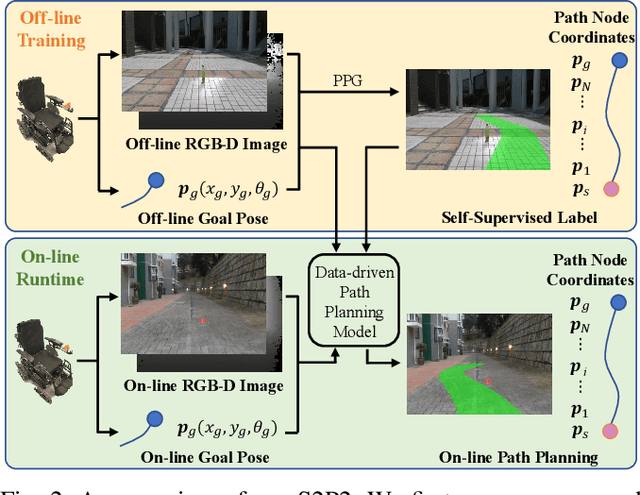
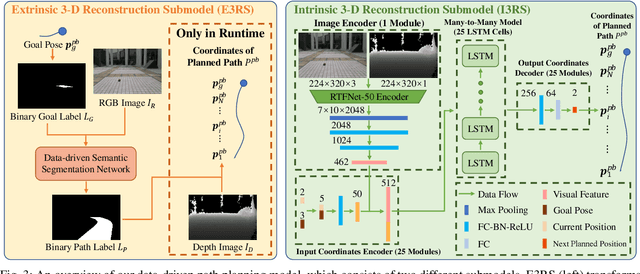
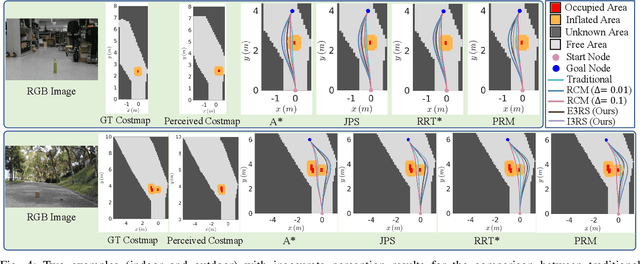
Path planning is a fundamental capability for autonomous navigation of robotic wheelchairs. With the impressive development of deep-learning technologies, imitation learning-based path planning approaches have achieved effective results in recent years. However, the disadvantages of these approaches are twofold: 1) they may need extensive time and labor to record expert demonstrations as training data; and 2) existing approaches could only receive high-level commands, such as turning left/right. These commands could be less sufficient for the navigation of mobile robots (e.g., robotic wheelchairs), which usually require exact poses of goals. We contribute a solution to this problem by proposing S2P2, a self-supervised goal-directed path planning approach. Specifically, we develop a pipeline to automatically generate planned path labels given as input RGB-D images and poses of goals. Then, we present a best-fit regression plane loss to train our data-driven path planning model based on the generated labels. Our S2P2 does not need pre-built maps, but it can be integrated into existing map-based navigation systems through our framework. Experimental results show that our S2P2 outperforms traditional path planning algorithms, and increases the robustness of existing map-based navigation systems. Our project page is available at https://sites.google.com/view/s2p2.