 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe RoboSense Challenge: Sense Anything, Navigate Anywhere, Adapt Across Platforms
Jan 08, 2026Autonomous systems are increasingly deployed in open and dynamic environments -- from city streets to aerial and indoor spaces -- where perception models must remain reliable under sensor noise, environmental variation, and platform shifts. However, even state-of-the-art methods often degrade under unseen conditions, highlighting the need for robust and generalizable robot sensing. The RoboSense 2025 Challenge is designed to advance robustness and adaptability in robot perception across diverse sensing scenarios. It unifies five complementary research tracks spanning language-grounded decision making, socially compliant navigation, sensor configuration generalization, cross-view and cross-modal correspondence, and cross-platform 3D perception. Together, these tasks form a comprehensive benchmark for evaluating real-world sensing reliability under domain shifts, sensor failures, and platform discrepancies. RoboSense 2025 provides standardized datasets, baseline models, and unified evaluation protocols, enabling large-scale and reproducible comparison of robust perception methods. The challenge attracted 143 teams from 85 institutions across 16 countries, reflecting broad community engagement. By consolidating insights from 23 winning solutions, this report highlights emerging methodological trends, shared design principles, and open challenges across all tracks, marking a step toward building robots that can sense reliably, act robustly, and adapt across platforms in real-world environments.
Yanyun-3: Enabling Cross-Platform Strategy Game Operation with Vision-Language Models
Nov 17, 2025Automated operation in cross-platform strategy games demands agents with robust generalization across diverse user interfaces and dynamic battlefield conditions. While vision-language models (VLMs) have shown considerable promise in multimodal reasoning, their application to complex human-computer interaction scenarios--such as strategy gaming--remains largely unexplored. Here, we introduce Yanyun-3, a general-purpose agent framework that, for the first time, enables autonomous cross-platform operation across three heterogeneous strategy game environments. By integrating the vision-language reasoning of Qwen2.5-VL with the precise execution capabilities of UI-TARS, Yanyun-3 successfully performs core tasks including target localization, combat resource allocation, and area control. Through systematic ablation studies, we evaluate the effects of various multimodal data combinations--static images, multi-image sequences, and videos--and propose the concept of combination granularity to differentiate between intra-sample fusion and inter-sample mixing strategies. We find that a hybrid strategy, which fuses multi-image and video data while mixing in static images (MV+S), substantially outperforms full fusion: it reduces inference time by 63% and boosts the BLEU-4 score by a factor of 12 (from 4.81% to 62.41%, approximately 12.98x). Operating via a closed-loop pipeline of screen capture, model inference, and action execution, the agent demonstrates strong real-time performance and cross-platform generalization. Beyond providing an efficient solution for strategy game automation, our work establishes a general paradigm for enhancing VLM performance through structured multimodal data organization, offering new insights into the interplay between static perception and dynamic reasoning in embodied intelligence.
Intellectual Property in Graph-Based Machine Learning as a Service: Attacks and Defenses
Aug 27, 2025Graph-structured data, which captures non-Euclidean relationships and interactions between entities, is growing in scale and complexity. As a result, training state-of-the-art graph machine learning (GML) models have become increasingly resource-intensive, turning these models and data into invaluable Intellectual Property (IP). To address the resource-intensive nature of model training, graph-based Machine-Learning-as-a-Service (GMLaaS) has emerged as an efficient solution by leveraging third-party cloud services for model development and management. However, deploying such models in GMLaaS also exposes them to potential threats from attackers. Specifically, while the APIs within a GMLaaS system provide interfaces for users to query the model and receive outputs, they also allow attackers to exploit and steal model functionalities or sensitive training data, posing severe threats to the safety of these GML models and the underlying graph data. To address these challenges, this survey systematically introduces the first taxonomy of threats and defenses at the level of both GML model and graph-structured data. Such a tailored taxonomy facilitates an in-depth understanding of GML IP protection. Furthermore, we present a systematic evaluation framework to assess the effectiveness of IP protection methods, introduce a curated set of benchmark datasets across various domains, and discuss their application scopes and future challenges. Finally, we establish an open-sourced versatile library named PyGIP, which evaluates various attack and defense techniques in GMLaaS scenarios and facilitates the implementation of existing benchmark methods. The library resource can be accessed at: https://labrai.github.io/PyGIP. We believe this survey will play a fundamental role in intellectual property protection for GML and provide practical recipes for the GML community.
RoadFormer+: Delivering RGB-X Scene Parsing through Scale-Aware Information Decoupling and Advanced Heterogeneous Feature Fusion
Jul 31, 2024



Task-specific data-fusion networks have marked considerable achievements in urban scene parsing. Among these networks, our recently proposed RoadFormer successfully extracts heterogeneous features from RGB images and surface normal maps and fuses these features through attention mechanisms, demonstrating compelling efficacy in RGB-Normal road scene parsing. However, its performance significantly deteriorates when handling other types/sources of data or performing more universal, all-category scene parsing tasks. To overcome these limitations, this study introduces RoadFormer+, an efficient, robust, and adaptable model capable of effectively fusing RGB-X data, where ``X'', represents additional types/modalities of data such as depth, thermal, surface normal, and polarization. Specifically, we propose a novel hybrid feature decoupling encoder to extract heterogeneous features and decouple them into global and local components. These decoupled features are then fused through a dual-branch multi-scale heterogeneous feature fusion block, which employs parallel Transformer attentions and convolutional neural network modules to merge multi-scale features across different scales and receptive fields. The fused features are subsequently fed into a decoder to generate the final semantic predictions. Notably, our proposed RoadFormer+ ranks first on the KITTI Road benchmark and achieves state-of-the-art performance in mean intersection over union on the Cityscapes, MFNet, FMB, and ZJU datasets. Moreover, it reduces the number of learnable parameters by 65\% compared to RoadFormer. Our source code will be publicly available at mias.group/RoadFormerPlus.
A General Implicit Framework for Fast NeRF Composition and Rendering
Aug 14, 2023A variety of Neural Radiance Fields (NeRF) methods have recently achieved remarkable success in high render speed. However, current accelerating methods are specialized and incompatible with various implicit methods, preventing real-time composition over various types of NeRF works. Because NeRF relies on sampling along rays, it is possible to provide general guidance for acceleration. To that end, we propose a general implicit pipeline for composing NeRF objects quickly. Our method enables the casting of dynamic shadows within or between objects using analytical light sources while allowing multiple NeRF objects to be seamlessly placed and rendered together with any arbitrary rigid transformations. Mainly, our work introduces a new surface representation known as Neural Depth Fields (NeDF) that quickly determines the spatial relationship between objects by allowing direct intersection computation between rays and implicit surfaces. It leverages an intersection neural network to query NeRF for acceleration instead of depending on an explicit spatial structure.Our proposed method is the first to enable both the progressive and interactive composition of NeRF objects. Additionally, it also serves as a previewing plugin for a range of existing NeRF works.
Adaptive-Mask Fusion Network for Segmentation of Drivable Road and Negative Obstacle With Untrustworthy Features
Apr 27, 2023Segmentation of drivable roads and negative obstacles is critical to the safe driving of autonomous vehicles. Currently, many multi-modal fusion methods have been proposed to improve segmentation accuracy, such as fusing RGB and depth images. However, we find that when fusing two modals of data with untrustworthy features, the performance of multi-modal networks could be degraded, even lower than those using a single modality. In this paper, the untrustworthy features refer to those extracted from regions (e.g., far objects that are beyond the depth measurement range) with invalid depth data (i.e., 0 pixel value) in depth images. The untrustworthy features can confuse the segmentation results, and hence lead to inferior results. To provide a solution to this issue, we propose the Adaptive-Mask Fusion Network (AMFNet) by introducing adaptive-weight masks in the fusion module to fuse features from RGB and depth images with inconsistency. In addition, we release a large-scale RGB-depth dataset with manually-labeled ground truth based on the NPO dataset for drivable roads and negative obstacles segmentation. Extensive experimental results demonstrate that our network achieves state-of-the-art performance compared with other networks. Our code and dataset are available at: https://github.com/lab-sun/AMFNet.
SLAMesh: Real-time LiDAR Simultaneous Localization and Meshing
Mar 09, 2023
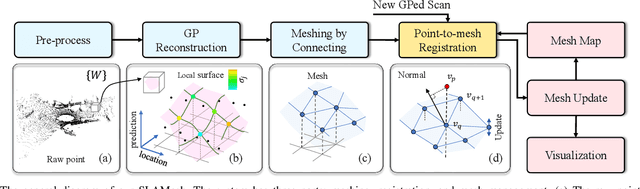
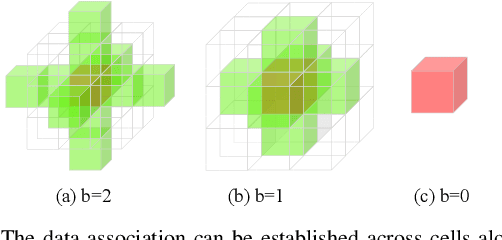

Most current LiDAR simultaneous localization and mapping (SLAM) systems build maps in point clouds, which are sparse when zoomed in, even though they seem dense to human eyes. Dense maps are essential for robotic applications, such as map-based navigation. Due to the low memory cost, mesh has become an attractive dense model for mapping in recent years. However, existing methods usually produce mesh maps by using an offline post-processing step to generate mesh maps. This two-step pipeline does not allow these methods to use the built mesh maps online and to enable localization and meshing to benefit each other. To solve this problem, we propose the first CPU-only real-time LiDAR SLAM system that can simultaneously build a mesh map and perform localization against the mesh map. A novel and direct meshing strategy with Gaussian process reconstruction realizes the fast building, registration, and updating of mesh maps. We perform experiments on several public datasets. The results show that our SLAM system can run at around $40$Hz. The localization and meshing accuracy also outperforms the state-of-the-art methods, including the TSDF map and Poisson reconstruction. Our code and video demos are available at: https://github.com/lab-sun/SLAMesh.
RNGDet++: Road Network Graph Detection by Transformer with Instance Segmentation and Multi-scale Features Enhancement
Sep 21, 2022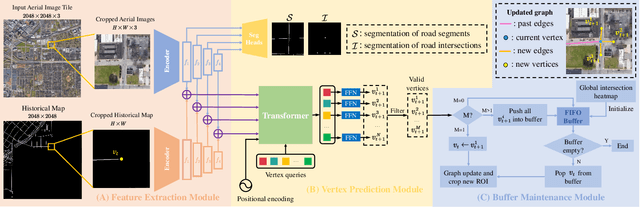
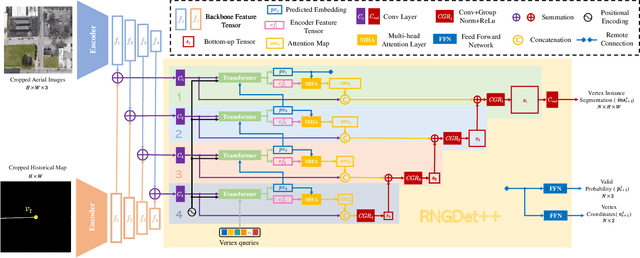
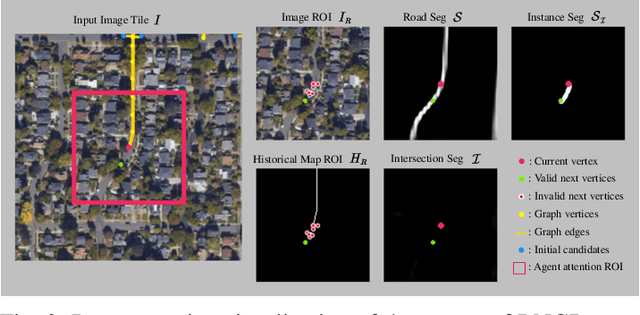
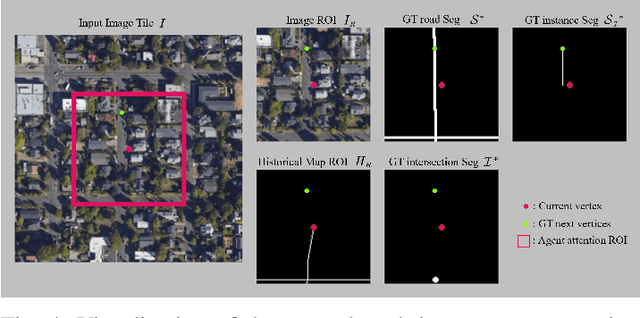
The graph structure of road networks is critical for downstream tasks of autonomous driving systems, such as global planning, motion prediction and control. In the past, the road network graph is usually manually annotated by human experts, which is time-consuming and labor-intensive. To obtain the road network graph with better effectiveness and efficiency, automatic approaches for road network graph detection are required. Previous works either post-process semantic segmentation maps or propose graph-based algorithms to directly predict the road network graph. However, previous works suffer from hard-coded heuristic processing algorithms and inferior final performance. To enhance the previous SOTA (State-of-the-Art) approach RNGDet, we add an instance segmentation head to better supervise the model training, and enable the model to leverage multi-scale features of the backbone network. Since the new proposed approach is improved from RNGDet, it is named RNGDet++. All approaches are evaluated on a large publicly available dataset. RNGDet++ outperforms baseline models on almost all metrics scores. It improves the topology correctness APLS (Average Path Length Similarity) by around 3\%. The demo video and supplementary materials are available on our project page \url{https://tonyxuqaq.github.io/projects/RNGDetPlusPlus/}.
CenterLineDet: Road Lane CenterLine Graph Detection With Vehicle-Mounted Sensors by Transformer for High-definition Map Creation
Sep 16, 2022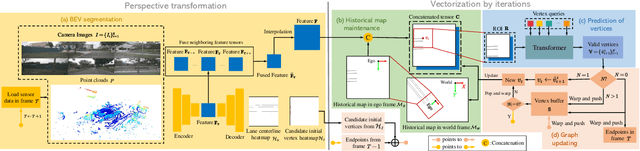
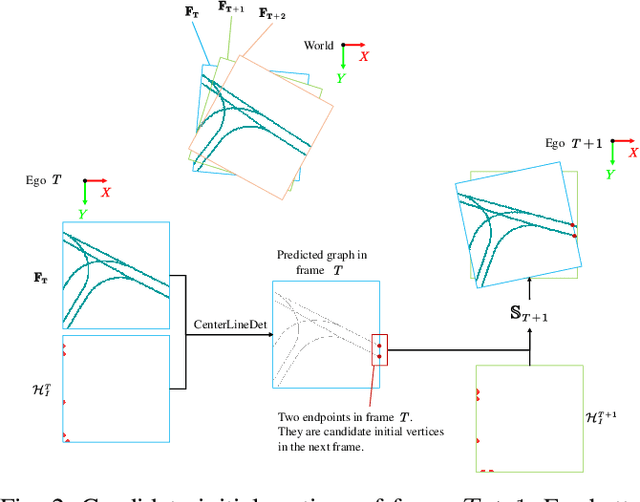

With the rapid development of autonomous vehicles, there witnesses a booming demand for high-definition maps (HD maps) that provide reliable and robust prior information of static surroundings in autonomous driving scenarios. As one of the main high-level elements in the HD map, the road lane centerline is critical for downstream tasks, such as prediction and planning. Manually annotating lane centerline HD maps by human annotators is labor-intensive, expensive and inefficient, severely restricting the wide application and fast deployment of autonomous driving systems. Previous works seldom explore the centerline HD map mapping problem due to the complicated topology and severe overlapping issues of road centerlines. In this paper, we propose a novel method named CenterLineDet to create the lane centerline HD map automatically. CenterLineDet is trained by imitation learning and can effectively detect the graph of lane centerlines by iterations with vehicle-mounted sensors. Due to the application of the DETR-like transformer network, CenterLineDet can handle complicated graph topology, such as lane intersections. The proposed approach is evaluated on a large publicly available dataset Nuscenes, and the superiority of CenterLineDet is well demonstrated by the comparison results. This paper is accompanied by a demo video and a supplementary document that are available at \url{https://tonyxuqaq.github.io/projects/CenterLineDet/}.
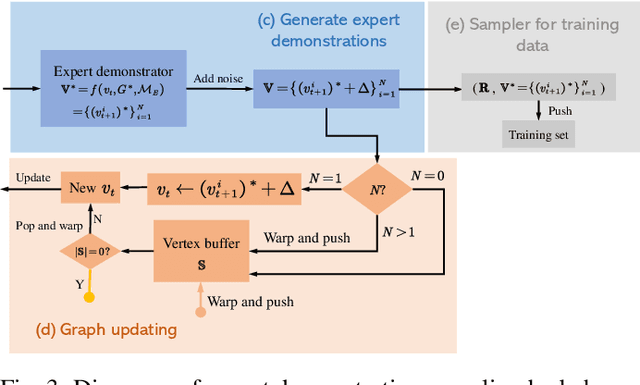
RNGDet: Road Network Graph Detection by Transformer in Aerial Images
Feb 16, 2022
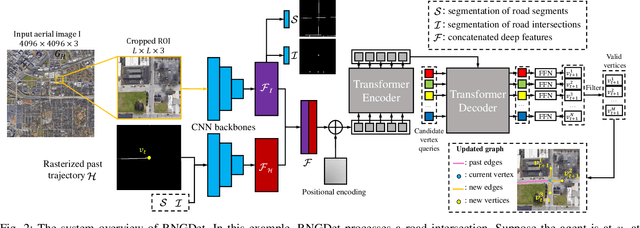
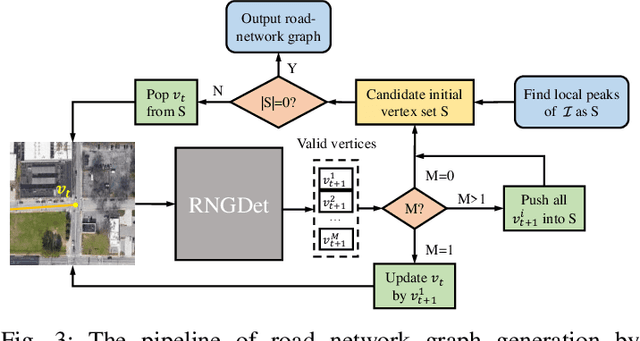
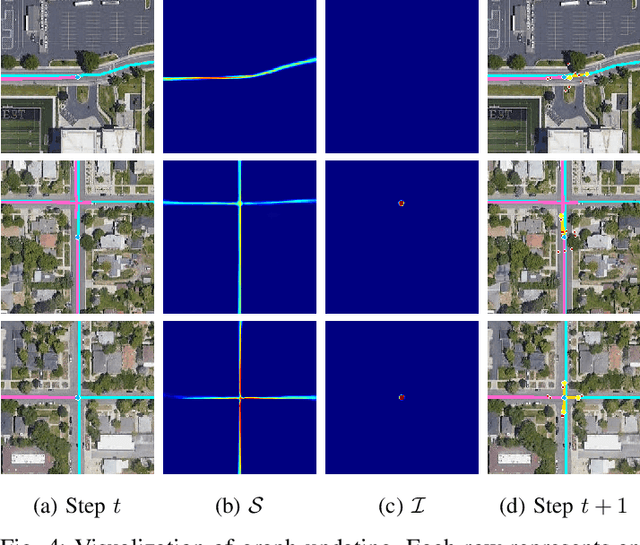
Road network graphs provide critical information for autonomous vehicle applications, such as motion planning on drivable areas. However, manually annotating road network graphs is inefficient and labor-intensive. Automatically detecting road network graphs could alleviate this issue, but existing works are either segmentation-based approaches that could not ensure satisfactory topology correctness, or graph-based approaches that could not present precise enough detection results. To provide a solution to these problems, we propose a novel approach based on transformer and imitation learning named RNGDet (\underline{R}oad \underline{N}etwork \underline{G}raph \underline{Det}ection by Transformer) in this paper. In view of that high-resolution aerial images could be easily accessed all over the world nowadays, we make use of aerial images in our approach. Taken as input an aerial image, our approach iteratively generates road network graphs vertex-by-vertex. Our approach can handle complicated intersection points of various numbers of road segments. We evaluate our approach on a publicly available dataset. The superiority of our approach is demonstrated through the comparative experiments.