 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDepthMatch: Semi-Supervised RGB-D Scene Parsing through Depth-Guided Regularization
May 26, 2025RGB-D scene parsing methods effectively capture both semantic and geometric features of the environment, demonstrating great potential under challenging conditions such as extreme weather and low lighting. However, existing RGB-D scene parsing methods predominantly rely on supervised training strategies, which require a large amount of manually annotated pixel-level labels that are both time-consuming and costly. To overcome these limitations, we introduce DepthMatch, a semi-supervised learning framework that is specifically designed for RGB-D scene parsing. To make full use of unlabeled data, we propose complementary patch mix-up augmentation to explore the latent relationships between texture and spatial features in RGB-D image pairs. We also design a lightweight spatial prior injector to replace traditional complex fusion modules, improving the efficiency of heterogeneous feature fusion. Furthermore, we introduce depth-guided boundary loss to enhance the model's boundary prediction capabilities. Experimental results demonstrate that DepthMatch exhibits high applicability in both indoor and outdoor scenes, achieving state-of-the-art results on the NYUv2 dataset and ranking first on the KITTI Semantics benchmark.
RoadFormer+: Delivering RGB-X Scene Parsing through Scale-Aware Information Decoupling and Advanced Heterogeneous Feature Fusion
Jul 31, 2024



Task-specific data-fusion networks have marked considerable achievements in urban scene parsing. Among these networks, our recently proposed RoadFormer successfully extracts heterogeneous features from RGB images and surface normal maps and fuses these features through attention mechanisms, demonstrating compelling efficacy in RGB-Normal road scene parsing. However, its performance significantly deteriorates when handling other types/sources of data or performing more universal, all-category scene parsing tasks. To overcome these limitations, this study introduces RoadFormer+, an efficient, robust, and adaptable model capable of effectively fusing RGB-X data, where ``X'', represents additional types/modalities of data such as depth, thermal, surface normal, and polarization. Specifically, we propose a novel hybrid feature decoupling encoder to extract heterogeneous features and decouple them into global and local components. These decoupled features are then fused through a dual-branch multi-scale heterogeneous feature fusion block, which employs parallel Transformer attentions and convolutional neural network modules to merge multi-scale features across different scales and receptive fields. The fused features are subsequently fed into a decoder to generate the final semantic predictions. Notably, our proposed RoadFormer+ ranks first on the KITTI Road benchmark and achieves state-of-the-art performance in mean intersection over union on the Cityscapes, MFNet, FMB, and ZJU datasets. Moreover, it reduces the number of learnable parameters by 65\% compared to RoadFormer. Our source code will be publicly available at mias.group/RoadFormerPlus.
Ctrl-VIO: Continuous-Time Visual-Inertial Odometry for Rolling Shutter Cameras
Aug 25, 2022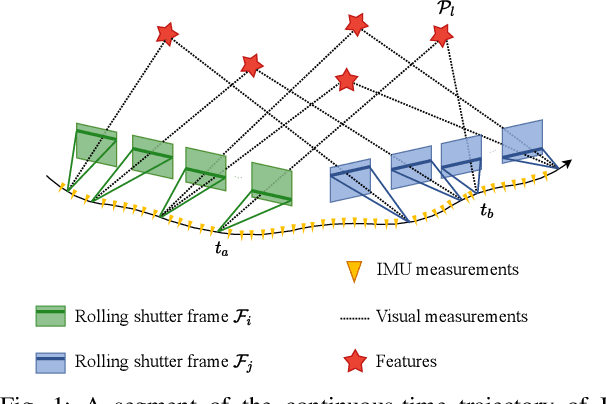
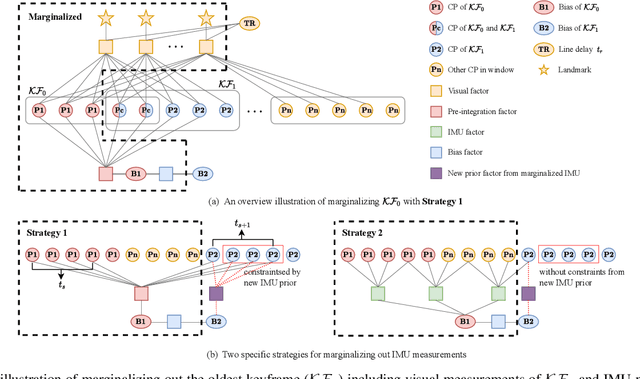
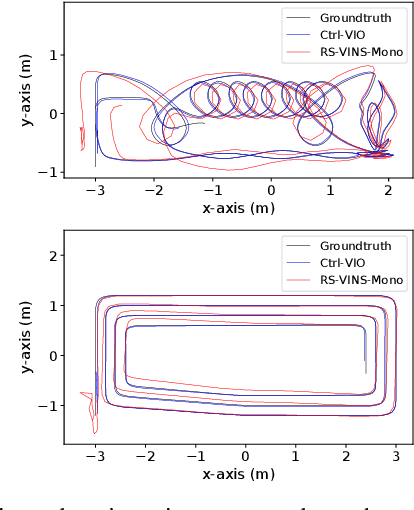
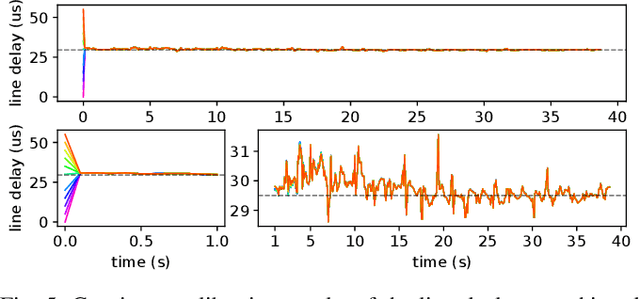
In this paper, we propose a probabilistic continuous-time visual-inertial odometry (VIO) for rolling shutter cameras. The continuous-time trajectory formulation naturally facilitates the fusion of asynchronized high-frequency IMU data and motion-distorted rolling shutter images. To prevent intractable computation load, the proposed VIO is sliding-window and keyframe-based. We propose to probabilistically marginalize the control points to keep the constant number of keyframes in the sliding window. Furthermore, the line exposure time difference (line delay) of the rolling shutter camera can be online calibrated in our continuous-time VIO. To extensively examine the performance of our continuous-time VIO, experiments are conducted on publicly-available WHU-RSVI, TUM-RSVI, and SenseTime-RSVI rolling shutter datasets. The results demonstrate the proposed continuous-time VIO significantly outperforms the existing state-of-the-art VIO methods. The codebase of this paper will also be open-sourced at \url{https://github.com/APRIL-ZJU/Ctrl-VIO}.