 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Policy Exploitation in Online Reinforcement Learning with Instant Retrospect Action
Jan 27, 2026Existing value-based online reinforcement learning (RL) algorithms suffer from slow policy exploitation due to ineffective exploration and delayed policy updates. To address these challenges, we propose an algorithm called Instant Retrospect Action (IRA). Specifically, we propose Q-Representation Discrepancy Evolution (RDE) to facilitate Q-network representation learning, enabling discriminative representations for neighboring state-action pairs. In addition, we adopt an explicit method to policy constraints by enabling Greedy Action Guidance (GAG). This is achieved through backtracking historical actions, which effectively enhances the policy update process. Our proposed method relies on providing the learning algorithm with accurate $k$-nearest-neighbor action value estimates and learning to design a fast-adaptable policy through policy constraints. We further propose the Instant Policy Update (IPU) mechanism, which enhances policy exploitation by systematically increasing the frequency of policy updates. We further discover that the early-stage training conservatism of the IRA method can alleviate the overestimation bias problem in value-based RL. Experimental results show that IRA can significantly improve the learning efficiency and final performance of online RL algorithms on eight MuJoCo continuous control tasks.
Machine Learning Co-pilot for Screening of Organic Molecular Additives for Perovskite Solar Cells
Dec 18, 2024



Machine learning (ML) has been extensively employed in planar perovskite photovoltaics to screen effective organic molecular additives, while encountering predictive biases for novel materials due to small datasets and reliance on predefined descriptors. Present work thus proposes an effective approach, Co-Pilot for Perovskite Additive Screener (Co-PAS), an ML-driven framework designed to accelerate additive screening for perovskite solar cells (PSCs). Co-PAS overcomes predictive biases by integrating the Molecular Scaffold Classifier (MSC) for scaffold-based pre-screening and utilizing Junction Tree Variational Autoencoder (JTVAE) latent vectors to enhance molecular structure representation, thereby enhancing the accuracy of power conversion efficiency (PCE) predictions. Leveraging Co-PAS, we integrate domain knowledge to screen an extensive dataset of 250,000 molecules from PubChem, prioritizing candidates based on predicted PCE values and key molecular properties such as donor number, dipole moment, and hydrogen bond acceptor count. This workflow leads to the identification of several promising passivating molecules, including the novel Boc-L-threonine N-hydroxysuccinimide ester (BTN), which, to our knowledge, has not been explored as an additive in PSCs and achieves a device PCE of 25.20%. Our results underscore the potential of Co-PAS in advancing additive discovery for high-performance PSCs.
Sequence-aware Pre-training for Echocardiography Probe Guidance
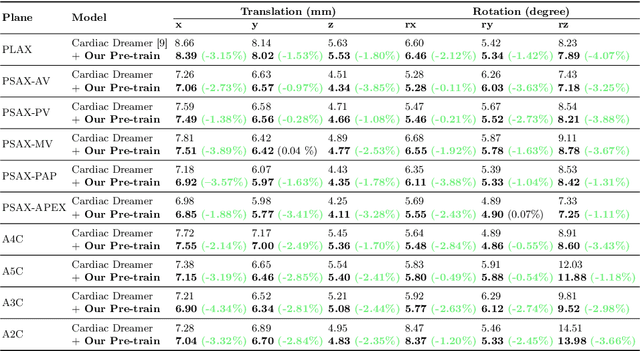
Aug 27, 2024Cardiac ultrasound probe guidance aims to help novices adjust the 6-DOF probe pose to obtain high-quality sectional images. Cardiac ultrasound faces two major challenges: (1) the inherently complex structure of the heart, and (2) significant individual variations. Previous works have only learned the population-averaged 2D and 3D structures of the heart rather than personalized cardiac structural features, leading to a performance bottleneck. Clinically, we observed that sonographers adjust their understanding of a patient's cardiac structure based on prior scanning sequences, thereby modifying their scanning strategies. Inspired by this, we propose a sequence-aware self-supervised pre-training method. Specifically, our approach learns personalized 2D and 3D cardiac structural features by predicting the masked-out images and actions in a scanning sequence. We hypothesize that if the model can predict the missing content it has acquired a good understanding of the personalized cardiac structure. In the downstream probe guidance task, we also introduced a sequence modeling approach that models individual cardiac structural information based on the images and actions from historical scan data, enabling more accurate navigation decisions. Experiments on a large-scale dataset with 1.36 million samples demonstrated that our proposed sequence-aware paradigm can significantly reduce navigation errors, with translation errors decreasing by 15.90% to 36.87% and rotation errors decreasing by 11.13% to 20.77%, compared to state-of-the-art methods.
RoadFormer+: Delivering RGB-X Scene Parsing through Scale-Aware Information Decoupling and Advanced Heterogeneous Feature Fusion
Jul 31, 2024



Task-specific data-fusion networks have marked considerable achievements in urban scene parsing. Among these networks, our recently proposed RoadFormer successfully extracts heterogeneous features from RGB images and surface normal maps and fuses these features through attention mechanisms, demonstrating compelling efficacy in RGB-Normal road scene parsing. However, its performance significantly deteriorates when handling other types/sources of data or performing more universal, all-category scene parsing tasks. To overcome these limitations, this study introduces RoadFormer+, an efficient, robust, and adaptable model capable of effectively fusing RGB-X data, where ``X'', represents additional types/modalities of data such as depth, thermal, surface normal, and polarization. Specifically, we propose a novel hybrid feature decoupling encoder to extract heterogeneous features and decouple them into global and local components. These decoupled features are then fused through a dual-branch multi-scale heterogeneous feature fusion block, which employs parallel Transformer attentions and convolutional neural network modules to merge multi-scale features across different scales and receptive fields. The fused features are subsequently fed into a decoder to generate the final semantic predictions. Notably, our proposed RoadFormer+ ranks first on the KITTI Road benchmark and achieves state-of-the-art performance in mean intersection over union on the Cityscapes, MFNet, FMB, and ZJU datasets. Moreover, it reduces the number of learnable parameters by 65\% compared to RoadFormer. Our source code will be publicly available at mias.group/RoadFormerPlus.
Structure-aware World Model for Probe Guidance via Large-scale Self-supervised Pre-train
Jun 28, 2024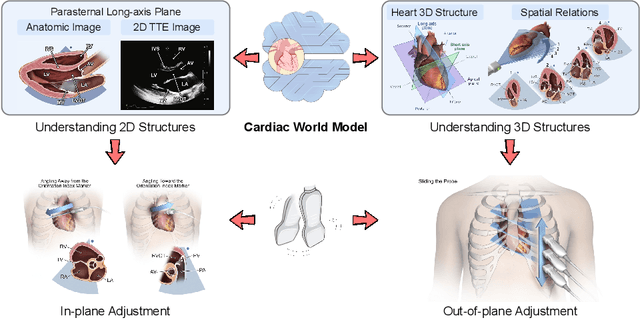
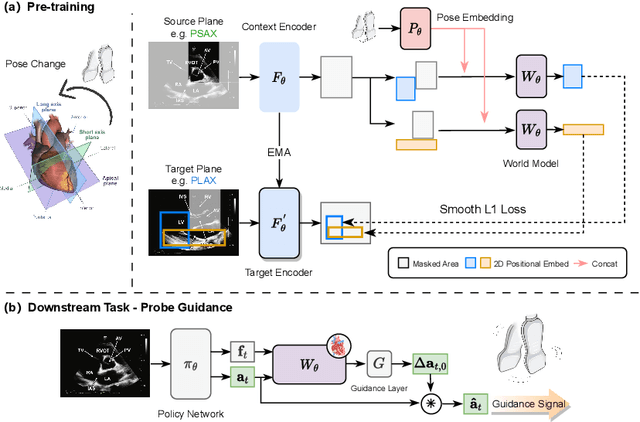

The complex structure of the heart leads to significant challenges in echocardiography, especially in acquisition cardiac ultrasound images. Successful echocardiography requires a thorough understanding of the structures on the two-dimensional plane and the spatial relationships between planes in three-dimensional space. In this paper, we innovatively propose a large-scale self-supervised pre-training method to acquire a cardiac structure-aware world model. The core innovation lies in constructing a self-supervised task that requires structural inference by predicting masked structures on a 2D plane and imagining another plane based on pose transformation in 3D space. To support large-scale pre-training, we collected over 1.36 million echocardiograms from ten standard views, along with their 3D spatial poses. In the downstream probe guidance task, we demonstrate that our pre-trained model consistently reduces guidance errors across the ten most common standard views on the test set with 0.29 million samples from 74 routine clinical scans, indicating that structure-aware pre-training benefits the scanning.
Cardiac Copilot: Automatic Probe Guidance for Echocardiography with World Model
Jun 19, 2024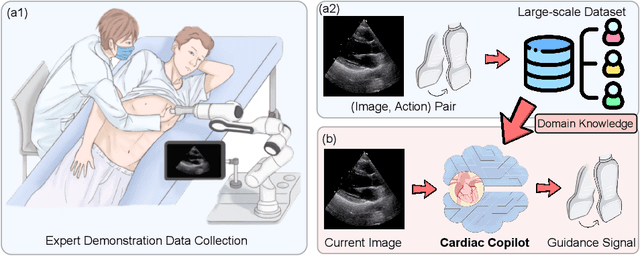
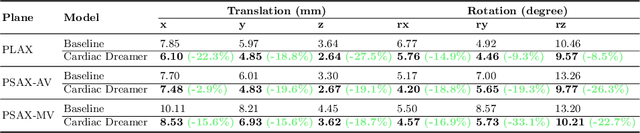
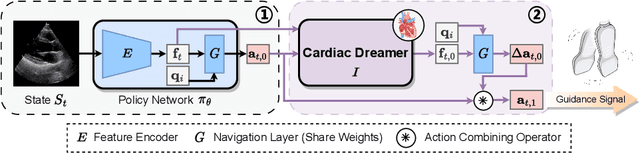
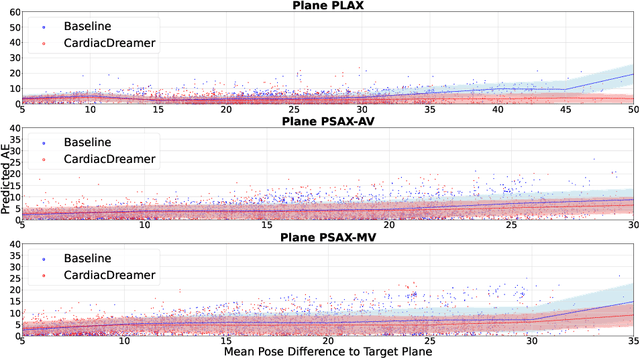
Echocardiography is the only technique capable of real-time imaging of the heart and is vital for diagnosing the majority of cardiac diseases. However, there is a severe shortage of experienced cardiac sonographers, due to the heart's complex structure and significant operational challenges. To mitigate this situation, we present a Cardiac Copilot system capable of providing real-time probe movement guidance to assist less experienced sonographers in conducting freehand echocardiography. This system can enable non-experts, especially in primary departments and medically underserved areas, to perform cardiac ultrasound examinations, potentially improving global healthcare delivery. The core innovation lies in proposing a data-driven world model, named Cardiac Dreamer, for representing cardiac spatial structures. This world model can provide structure features of any cardiac planes around the current probe position in the latent space, serving as an precise navigation map for autonomous plane localization. We train our model with real-world ultrasound data and corresponding probe motion from 110 routine clinical scans with 151K sample pairs by three certified sonographers. Evaluations on three standard planes with 37K sample pairs demonstrate that the world model can reduce navigation errors by up to 33\% and exhibit more stable performance.
Train Once, Get a Family: State-Adaptive Balances for Offline-to-Online Reinforcement Learning
Oct 30, 2023Offline-to-online reinforcement learning (RL) is a training paradigm that combines pre-training on a pre-collected dataset with fine-tuning in an online environment. However, the incorporation of online fine-tuning can intensify the well-known distributional shift problem. Existing solutions tackle this problem by imposing a policy constraint on the policy improvement objective in both offline and online learning. They typically advocate a single balance between policy improvement and constraints across diverse data collections. This one-size-fits-all manner may not optimally leverage each collected sample due to the significant variation in data quality across different states. To this end, we introduce Family Offline-to-Online RL (FamO2O), a simple yet effective framework that empowers existing algorithms to determine state-adaptive improvement-constraint balances. FamO2O utilizes a universal model to train a family of policies with different improvement/constraint intensities, and a balance model to select a suitable policy for each state. Theoretically, we prove that state-adaptive balances are necessary for achieving a higher policy performance upper bound. Empirically, extensive experiments show that FamO2O offers a statistically significant improvement over various existing methods, achieving state-of-the-art performance on the D4RL benchmark. Codes are available at https://github.com/LeapLabTHU/FamO2O.
Camera Bias in a Fine Grained Classification Task
Jul 16, 2020
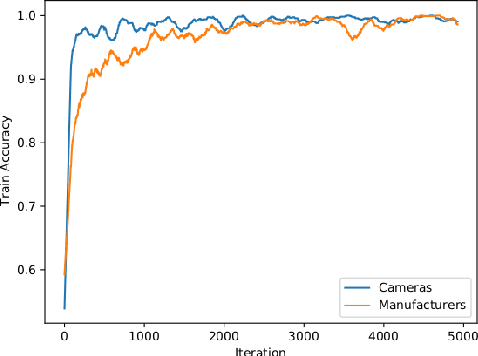
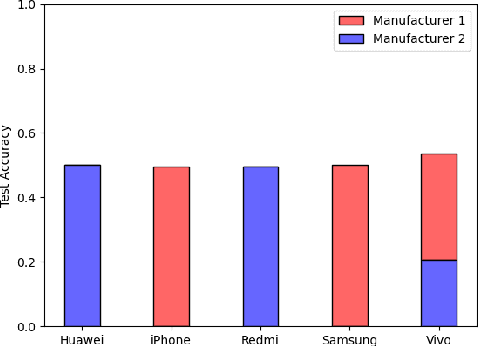
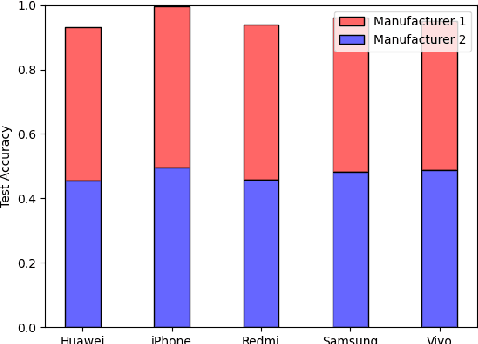
We show that correlations between the camera used to acquire an image and the class label of that image can be exploited by convolutional neural networks (CNN), resulting in a model that "cheats" at an image classification task by recognizing which camera took the image and inferring the class label from the camera. We show that models trained on a dataset with camera / label correlations do not generalize well to images in which those correlations are absent, nor to images from unencountered cameras. Furthermore, we investigate which visual features they are exploiting for camera recognition. Our experiments present evidence against the importance of global color statistics, lens deformation and chromatic aberration, and in favor of high frequency features, which may be introduced by image processing algorithms built into the cameras.
A study of the effect of the illumination model on the generation of synthetic training datasets
Jun 15, 2020


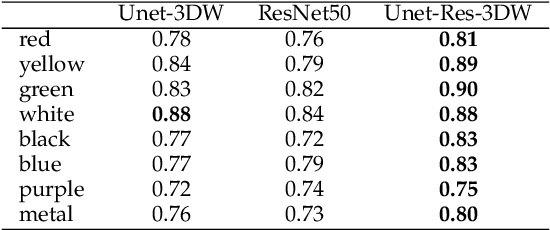
The use of computer generated images to train Deep Neural Networks is a viable alternative to real images when the latter are scarce or expensive. In this paper, we study how the illumination model used by the rendering software affects the quality of the generated images. We created eight training sets, each one with a different illumination model, and tested them on three different network architectures, ResNet, U-Net and a combined architecture developed by us. The test set consisted of photos of 3D printed objects produced from the same CAD models used to generate the training set. The effect of the other parameters of the rendering process, such as textures and camera position, was randomized. Our results show that the effect of the illumination model is important, comparable in significance to the network architecture. We also show that both light probes capturing natural environmental light, and modelled lighting environments, can give good results. In the case of light probes, we identified as two significant factors affecting performance the similarity between the light probe and the test environment, as well as the light probe's resolution. Regarding modelled lighting environment, similarity with the test environment was again identified as a significant factor.
Watermark retrieval from 3D printed objects via synthetic data training
May 23, 2019
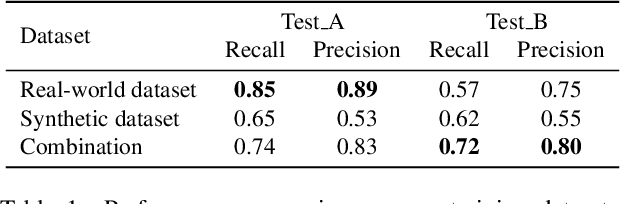
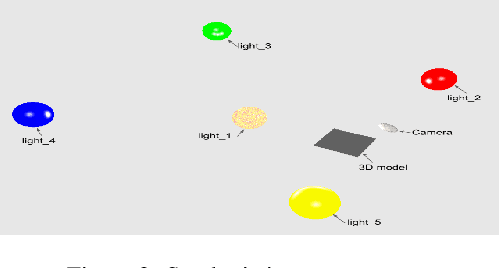
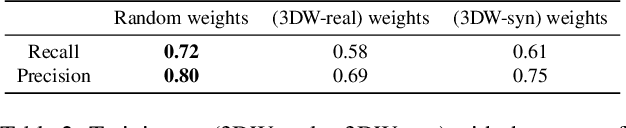
We present a deep neural network based method for the retrieval of watermarks from images of 3D printed objects. To deal with the variability of all possible 3D printing and image acquisition settings we train the network with synthetic data. The main simulator parameters such as texture, illumination and camera position are dynamically randomized in non-realistic ways, forcing the neural network to learn the intrinsic features of the 3D printed watermarks. At the end of the pipeline, the watermark, in the form of a two-dimensional bit array, is retrieved through a series of simple image processing and statistical operations applied on the confidence map generated by the neural network. The results demonstrate that the inclusion of synthetic DR data in the training set increases the generalization power of the network, which performs better on images from previously unseen 3D printed objects. We conclude that in our application domain of information retrieval from 3D printed objects, where access to the exact CAD files of the printed objects can be assumed, one can use inexpensive synthetic data to enhance neural network training, reducing the need for the labour intensive process of creating large amounts of hand labelled real data or the need to generate photorealistic synthetic data.