 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Human Interpretation and Machine Representation: A Landscape of Qualitative Data Analysis in the LLM Era
Jan 16, 2026LLMs are increasingly used to support qualitative research, yet existing systems produce outputs that vary widely--from trace-faithful summaries to theory-mediated explanations and system models. To make these differences explicit, we introduce a 4$\times$4 landscape crossing four levels of meaning-making (descriptive, categorical, interpretive, theoretical) with four levels of modeling (static structure, stages/timelines, causal pathways, feedback dynamics). Applying the landscape to prior LLM-based automation highlights a strong skew toward low-level meaning and low-commitment representations, with few reliable attempts at interpretive/theoretical inference or dynamical modeling. Based on the revealed gap, we outline an agenda for applying and building LLM-systems that make their interpretive and modeling commitments explicit, selectable, and governable.
Emulating Human-like Adaptive Vision for Efficient and Flexible Machine Visual Perception
Sep 18, 2025Human vision is highly adaptive, efficiently sampling intricate environments by sequentially fixating on task-relevant regions. In contrast, prevailing machine vision models passively process entire scenes at once, resulting in excessive resource demands scaling with spatial-temporal input resolution and model size, yielding critical limitations impeding both future advancements and real-world application. Here we introduce AdaptiveNN, a general framework aiming to drive a paradigm shift from 'passive' to 'active, adaptive' vision models. AdaptiveNN formulates visual perception as a coarse-to-fine sequential decision-making process, progressively identifying and attending to regions pertinent to the task, incrementally combining information across fixations, and actively concluding observation when sufficient. We establish a theory integrating representation learning with self-rewarding reinforcement learning, enabling end-to-end training of the non-differentiable AdaptiveNN without additional supervision on fixation locations. We assess AdaptiveNN on 17 benchmarks spanning 9 tasks, including large-scale visual recognition, fine-grained discrimination, visual search, processing images from real driving and medical scenarios, language-driven embodied AI, and side-by-side comparisons with humans. AdaptiveNN achieves up to 28x inference cost reduction without sacrificing accuracy, flexibly adapts to varying task demands and resource budgets without retraining, and provides enhanced interpretability via its fixation patterns, demonstrating a promising avenue toward efficient, flexible, and interpretable computer vision. Furthermore, AdaptiveNN exhibits closely human-like perceptual behaviors in many cases, revealing its potential as a valuable tool for investigating visual cognition. Code is available at https://github.com/LeapLabTHU/AdaptiveNN.
PIG-Nav: Key Insights for Pretrained Image Goal Navigation Models
Jul 23, 2025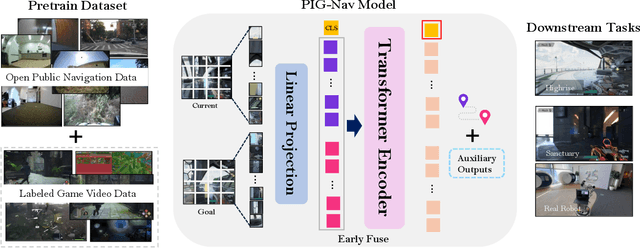
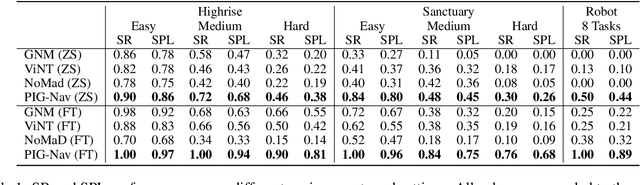
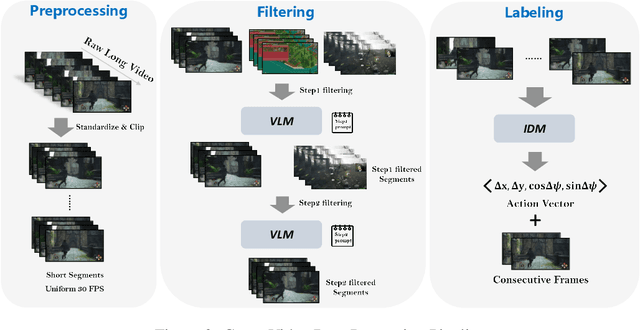
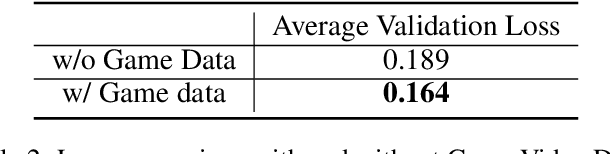
Recent studies have explored pretrained (foundation) models for vision-based robotic navigation, aiming to achieve generalizable navigation and positive transfer across diverse environments while enhancing zero-shot performance in unseen settings. In this work, we introduce PIG-Nav (Pretrained Image-Goal Navigation), a new approach that further investigates pretraining strategies for vision-based navigation models and contributes in two key areas. Model-wise, we identify two critical design choices that consistently improve the performance of pretrained navigation models: (1) integrating an early-fusion network structure to combine visual observations and goal images via appropriately pretrained Vision Transformer (ViT) image encoder, and (2) introducing suitable auxiliary tasks to enhance global navigation representation learning, thus further improving navigation performance. Dataset-wise, we propose a novel data preprocessing pipeline for efficiently labeling large-scale game video datasets for navigation model training. We demonstrate that augmenting existing open navigation datasets with diverse gameplay videos improves model performance. Our model achieves an average improvement of 22.6% in zero-shot settings and a 37.5% improvement in fine-tuning settings over existing visual navigation foundation models in two complex simulated environments and one real-world environment. These results advance the state-of-the-art in pretrained image-goal navigation models. Notably, our model maintains competitive performance while requiring significantly less fine-tuning data, highlighting its potential for real-world deployment with minimal labeled supervision.
LLM Agents for Psychology: A Study on Gamified Assessments
Feb 19, 2024Psychological measurement is essential for mental health, self-understanding, and personal development. Traditional methods, such as self-report scales and psychologist interviews, often face challenges with engagement and accessibility. While game-based and LLM-based tools have been explored to improve user interest and automate assessment, they struggle to balance engagement with generalizability. In this work, we propose PsychoGAT (Psychological Game AgenTs) to achieve a generic gamification of psychological assessment. The main insight is that powerful LLMs can function both as adept psychologists and innovative game designers. By incorporating LLM agents into designated roles and carefully managing their interactions, PsychoGAT can transform any standardized scales into personalized and engaging interactive fiction games. To validate the proposed method, we conduct psychometric evaluations to assess its effectiveness and employ human evaluators to examine the generated content across various psychological constructs, including depression, cognitive distortions, and personality traits. Results demonstrate that PsychoGAT serves as an effective assessment tool, achieving statistically significant excellence in psychometric metrics such as reliability, convergent validity, and discriminant validity. Moreover, human evaluations confirm PsychoGAT's enhancements in content coherence, interactivity, interest, immersion, and satisfaction.
Train Once, Get a Family: State-Adaptive Balances for Offline-to-Online Reinforcement Learning
Oct 30, 2023Offline-to-online reinforcement learning (RL) is a training paradigm that combines pre-training on a pre-collected dataset with fine-tuning in an online environment. However, the incorporation of online fine-tuning can intensify the well-known distributional shift problem. Existing solutions tackle this problem by imposing a policy constraint on the policy improvement objective in both offline and online learning. They typically advocate a single balance between policy improvement and constraints across diverse data collections. This one-size-fits-all manner may not optimally leverage each collected sample due to the significant variation in data quality across different states. To this end, we introduce Family Offline-to-Online RL (FamO2O), a simple yet effective framework that empowers existing algorithms to determine state-adaptive improvement-constraint balances. FamO2O utilizes a universal model to train a family of policies with different improvement/constraint intensities, and a balance model to select a suitable policy for each state. Theoretically, we prove that state-adaptive balances are necessary for achieving a higher policy performance upper bound. Empirically, extensive experiments show that FamO2O offers a statistically significant improvement over various existing methods, achieving state-of-the-art performance on the D4RL benchmark. Codes are available at https://github.com/LeapLabTHU/FamO2O.
Avalon's Game of Thoughts: Battle Against Deception through Recursive Contemplation
Oct 06, 2023



Recent breakthroughs in large language models (LLMs) have brought remarkable success in the field of LLM-as-Agent. Nevertheless, a prevalent assumption is that the information processed by LLMs is consistently honest, neglecting the pervasive deceptive or misleading information in human society and AI-generated content. This oversight makes LLMs susceptible to malicious manipulations, potentially resulting in detrimental outcomes. This study utilizes the intricate Avalon game as a testbed to explore LLMs' potential in deceptive environments. Avalon, full of misinformation and requiring sophisticated logic, manifests as a "Game-of-Thoughts". Inspired by the efficacy of humans' recursive thinking and perspective-taking in the Avalon game, we introduce a novel framework, Recursive Contemplation (ReCon), to enhance LLMs' ability to identify and counteract deceptive information. ReCon combines formulation and refinement contemplation processes; formulation contemplation produces initial thoughts and speech, while refinement contemplation further polishes them. Additionally, we incorporate first-order and second-order perspective transitions into these processes respectively. Specifically, the first-order allows an LLM agent to infer others' mental states, and the second-order involves understanding how others perceive the agent's mental state. After integrating ReCon with different LLMs, extensive experiment results from the Avalon game indicate its efficacy in aiding LLMs to discern and maneuver around deceptive information without extra fine-tuning and data. Finally, we offer a possible explanation for the efficacy of ReCon and explore the current limitations of LLMs in terms of safety, reasoning, speaking style, and format, potentially furnishing insights for subsequent research.
Leveraging Reward Consistency for Interpretable Feature Discovery in Reinforcement Learning
Sep 04, 2023The black-box nature of deep reinforcement learning (RL) hinders them from real-world applications. Therefore, interpreting and explaining RL agents have been active research topics in recent years. Existing methods for post-hoc explanations usually adopt the action matching principle to enable an easy understanding of vision-based RL agents. In this paper, it is argued that the commonly used action matching principle is more like an explanation of deep neural networks (DNNs) than the interpretation of RL agents. It may lead to irrelevant or misplaced feature attribution when different DNNs' outputs lead to the same rewards or different rewards result from the same outputs. Therefore, we propose to consider rewards, the essential objective of RL agents, as the essential objective of interpreting RL agents as well. To ensure reward consistency during interpretable feature discovery, a novel framework (RL interpreting RL, denoted as RL-in-RL) is proposed to solve the gradient disconnection from actions to rewards. We verify and evaluate our method on the Atari 2600 games as well as Duckietown, a challenging self-driving car simulator environment. The results show that our method manages to keep reward (or return) consistency and achieves high-quality feature attribution. Further, a series of analytical experiments validate our assumption of the action matching principle's limitations.
Hundreds Guide Millions: Adaptive Offline Reinforcement Learning with Expert Guidance
Sep 04, 2023



Offline reinforcement learning (RL) optimizes the policy on a previously collected dataset without any interactions with the environment, yet usually suffers from the distributional shift problem. To mitigate this issue, a typical solution is to impose a policy constraint on a policy improvement objective. However, existing methods generally adopt a ``one-size-fits-all'' practice, i.e., keeping only a single improvement-constraint balance for all the samples in a mini-batch or even the entire offline dataset. In this work, we argue that different samples should be treated with different policy constraint intensities. Based on this idea, a novel plug-in approach named Guided Offline RL (GORL) is proposed. GORL employs a guiding network, along with only a few expert demonstrations, to adaptively determine the relative importance of the policy improvement and policy constraint for every sample. We theoretically prove that the guidance provided by our method is rational and near-optimal. Extensive experiments on various environments suggest that GORL can be easily installed on most offline RL algorithms with statistically significant performance improvements.
Boosting Offline Reinforcement Learning with Action Preference Query
Jun 06, 2023Training practical agents usually involve offline and online reinforcement learning (RL) to balance the policy's performance and interaction costs. In particular, online fine-tuning has become a commonly used method to correct the erroneous estimates of out-of-distribution data learned in the offline training phase. However, even limited online interactions can be inaccessible or catastrophic for high-stake scenarios like healthcare and autonomous driving. In this work, we introduce an interaction-free training scheme dubbed Offline-with-Action-Preferences (OAP). The main insight is that, compared to online fine-tuning, querying the preferences between pre-collected and learned actions can be equally or even more helpful to the erroneous estimate problem. By adaptively encouraging or suppressing policy constraint according to action preferences, OAP could distinguish overestimation from beneficial policy improvement and thus attains a more accurate evaluation of unseen data. Theoretically, we prove a lower bound of the behavior policy's performance improvement brought by OAP. Moreover, comprehensive experiments on the D4RL benchmark and state-of-the-art algorithms demonstrate that OAP yields higher (29% on average) scores, especially on challenging AntMaze tasks (98% higher).
Efficient Knowledge Distillation from Model Checkpoints
Oct 12, 2022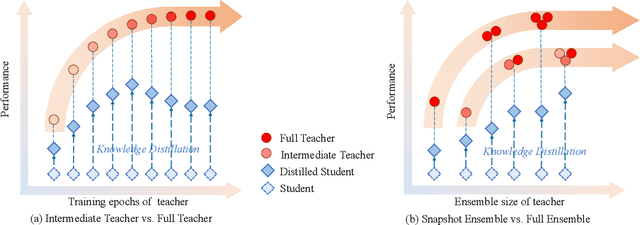
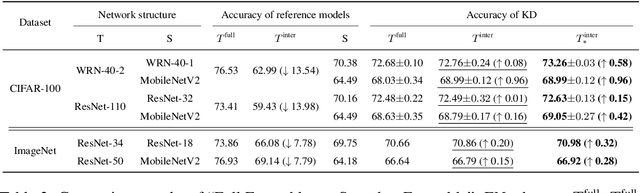
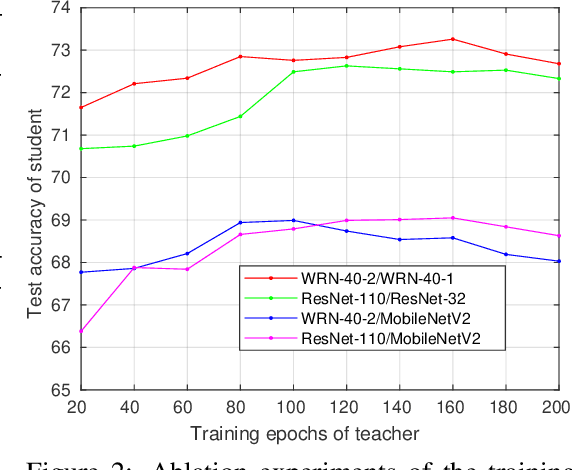
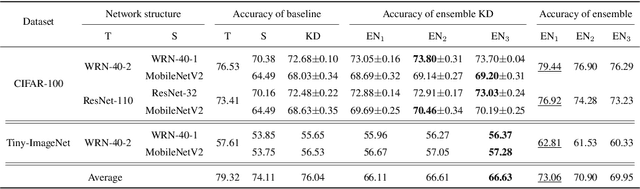
Knowledge distillation is an effective approach to learn compact models (students) with the supervision of large and strong models (teachers). As empirically there exists a strong correlation between the performance of teacher and student models, it is commonly believed that a high performing teacher is preferred. Consequently, practitioners tend to use a well trained network or an ensemble of them as the teacher. In this paper, we make an intriguing observation that an intermediate model, i.e., a checkpoint in the middle of the training procedure, often serves as a better teacher compared to the fully converged model, although the former has much lower accuracy. More surprisingly, a weak snapshot ensemble of several intermediate models from a same training trajectory can outperform a strong ensemble of independently trained and fully converged models, when they are used as teachers. We show that this phenomenon can be partially explained by the information bottleneck principle: the feature representations of intermediate models can have higher mutual information regarding the input, and thus contain more "dark knowledge" for effective distillation. We further propose an optimal intermediate teacher selection algorithm based on maximizing the total task-related mutual information. Experiments verify its effectiveness and applicability.