 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Step Distillation for Text-to-Image Generation: A Practical Guide
Dec 15, 2025Diffusion distillation has dramatically accelerated class-conditional image synthesis, but its applicability to open-ended text-to-image (T2I) generation is still unclear. We present the first systematic study that adapts and compares state-of-the-art distillation techniques on a strong T2I teacher model, FLUX.1-lite. By casting existing methods into a unified framework, we identify the key obstacles that arise when moving from discrete class labels to free-form language prompts. Beyond a thorough methodological analysis, we offer practical guidelines on input scaling, network architecture, and hyperparameters, accompanied by an open-source implementation and pretrained student models. Our findings establish a solid foundation for deploying fast, high-fidelity, and resource-efficient diffusion generators in real-world T2I applications. Code is available on github.com/alibaba-damo-academy/T2I-Distill.
Emulating Human-like Adaptive Vision for Efficient and Flexible Machine Visual Perception
Sep 18, 2025Human vision is highly adaptive, efficiently sampling intricate environments by sequentially fixating on task-relevant regions. In contrast, prevailing machine vision models passively process entire scenes at once, resulting in excessive resource demands scaling with spatial-temporal input resolution and model size, yielding critical limitations impeding both future advancements and real-world application. Here we introduce AdaptiveNN, a general framework aiming to drive a paradigm shift from 'passive' to 'active, adaptive' vision models. AdaptiveNN formulates visual perception as a coarse-to-fine sequential decision-making process, progressively identifying and attending to regions pertinent to the task, incrementally combining information across fixations, and actively concluding observation when sufficient. We establish a theory integrating representation learning with self-rewarding reinforcement learning, enabling end-to-end training of the non-differentiable AdaptiveNN without additional supervision on fixation locations. We assess AdaptiveNN on 17 benchmarks spanning 9 tasks, including large-scale visual recognition, fine-grained discrimination, visual search, processing images from real driving and medical scenarios, language-driven embodied AI, and side-by-side comparisons with humans. AdaptiveNN achieves up to 28x inference cost reduction without sacrificing accuracy, flexibly adapts to varying task demands and resource budgets without retraining, and provides enhanced interpretability via its fixation patterns, demonstrating a promising avenue toward efficient, flexible, and interpretable computer vision. Furthermore, AdaptiveNN exhibits closely human-like perceptual behaviors in many cases, revealing its potential as a valuable tool for investigating visual cognition. Code is available at https://github.com/LeapLabTHU/AdaptiveNN.
Uncertainty-Masked Bernoulli Diffusion for Camouflaged Object Detection Refinement
Jun 12, 2025

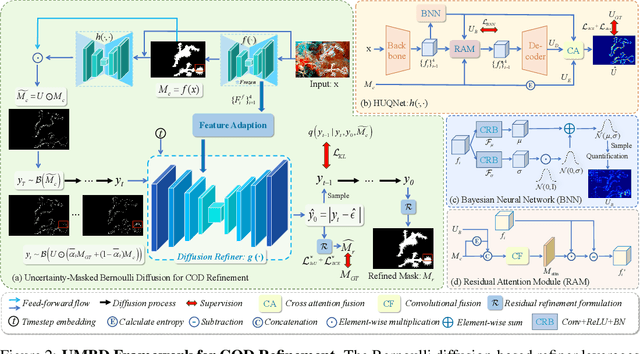

Camouflaged Object Detection (COD) presents inherent challenges due to the subtle visual differences between targets and their backgrounds. While existing methods have made notable progress, there remains significant potential for post-processing refinement that has yet to be fully explored. To address this limitation, we propose the Uncertainty-Masked Bernoulli Diffusion (UMBD) model, the first generative refinement framework specifically designed for COD. UMBD introduces an uncertainty-guided masking mechanism that selectively applies Bernoulli diffusion to residual regions with poor segmentation quality, enabling targeted refinement while preserving correctly segmented areas. To support this process, we design the Hybrid Uncertainty Quantification Network (HUQNet), which employs a multi-branch architecture and fuses uncertainty from multiple sources to improve estimation accuracy. This enables adaptive guidance during the generative sampling process. The proposed UMBD framework can be seamlessly integrated with a wide range of existing Encoder-Decoder-based COD models, combining their discriminative capabilities with the generative advantages of diffusion-based refinement. Extensive experiments across multiple COD benchmarks demonstrate consistent performance improvements, achieving average gains of 5.5% in MAE and 3.2% in weighted F-measure with only modest computational overhead. Code will be released.
ART: Anonymous Region Transformer for Variable Multi-Layer Transparent Image Generation
Feb 25, 2025Multi-layer image generation is a fundamental task that enables users to isolate, select, and edit specific image layers, thereby revolutionizing interactions with generative models. In this paper, we introduce the Anonymous Region Transformer (ART), which facilitates the direct generation of variable multi-layer transparent images based on a global text prompt and an anonymous region layout. Inspired by Schema theory suggests that knowledge is organized in frameworks (schemas) that enable people to interpret and learn from new information by linking it to prior knowledge.}, this anonymous region layout allows the generative model to autonomously determine which set of visual tokens should align with which text tokens, which is in contrast to the previously dominant semantic layout for the image generation task. In addition, the layer-wise region crop mechanism, which only selects the visual tokens belonging to each anonymous region, significantly reduces attention computation costs and enables the efficient generation of images with numerous distinct layers (e.g., 50+). When compared to the full attention approach, our method is over 12 times faster and exhibits fewer layer conflicts. Furthermore, we propose a high-quality multi-layer transparent image autoencoder that supports the direct encoding and decoding of the transparency of variable multi-layer images in a joint manner. By enabling precise control and scalable layer generation, ART establishes a new paradigm for interactive content creation.
Beyond Single Frames: Can LMMs Comprehend Temporal and Contextual Narratives in Image Sequences?
Feb 19, 2025Large Multimodal Models (LMMs) have achieved remarkable success across various visual-language tasks. However, existing benchmarks predominantly focus on single-image understanding, leaving the analysis of image sequences largely unexplored. To address this limitation, we introduce StripCipher, a comprehensive benchmark designed to evaluate capabilities of LMMs to comprehend and reason over sequential images. StripCipher comprises a human-annotated dataset and three challenging subtasks: visual narrative comprehension, contextual frame prediction, and temporal narrative reordering. Our evaluation of $16$ state-of-the-art LMMs, including GPT-4o and Qwen2.5VL, reveals a significant performance gap compared to human capabilities, particularly in tasks that require reordering shuffled sequential images. For instance, GPT-4o achieves only 23.93% accuracy in the reordering subtask, which is 56.07% lower than human performance. Further quantitative analysis discuss several factors, such as input format of images, affecting the performance of LLMs in sequential understanding, underscoring the fundamental challenges that remain in the development of LMMs.
ArtCrafter: Text-Image Aligning Style Transfer via Embedding Reframing
Jan 03, 2025



Recent years have witnessed significant advancements in text-guided style transfer, primarily attributed to innovations in diffusion models. These models excel in conditional guidance, utilizing text or images to direct the sampling process. However, despite their capabilities, direct conditional guidance approaches often face challenges in balancing the expressiveness of textual semantics with the diversity of output results while capturing stylistic features. To address these challenges, we introduce ArtCrafter, a novel framework for text-to-image style transfer. Specifically, we introduce an attention-based style extraction module, meticulously engineered to capture the subtle stylistic elements within an image. This module features a multi-layer architecture that leverages the capabilities of perceiver attention mechanisms to integrate fine-grained information. Additionally, we present a novel text-image aligning augmentation component that adeptly balances control over both modalities, enabling the model to efficiently map image and text embeddings into a shared feature space. We achieve this through attention operations that enable smooth information flow between modalities. Lastly, we incorporate an explicit modulation that seamlessly blends multimodal enhanced embeddings with original embeddings through an embedding reframing design, empowering the model to generate diverse outputs. Extensive experiments demonstrate that ArtCrafter yields impressive results in visual stylization, exhibiting exceptional levels of stylistic intensity, controllability, and diversity.
Bridging the Divide: Reconsidering Softmax and Linear Attention
Dec 09, 2024



Widely adopted in modern Vision Transformer designs, Softmax attention can effectively capture long-range visual information; however, it incurs excessive computational cost when dealing with high-resolution inputs. In contrast, linear attention naturally enjoys linear complexity and has great potential to scale up to higher-resolution images. Nonetheless, the unsatisfactory performance of linear attention greatly limits its practical application in various scenarios. In this paper, we take a step forward to close the gap between the linear and Softmax attention with novel theoretical analyses, which demystify the core factors behind the performance deviations. Specifically, we present two key perspectives to understand and alleviate the limitations of linear attention: the injective property and the local modeling ability. Firstly, we prove that linear attention is not injective, which is prone to assign identical attention weights to different query vectors, thus adding to severe semantic confusion since different queries correspond to the same outputs. Secondly, we confirm that effective local modeling is essential for the success of Softmax attention, in which linear attention falls short. The aforementioned two fundamental differences significantly contribute to the disparities between these two attention paradigms, which is demonstrated by our substantial empirical validation in the paper. In addition, more experiment results indicate that linear attention, as long as endowed with these two properties, can outperform Softmax attention across various tasks while maintaining lower computation complexity. Code is available at https://github.com/LeapLabTHU/InLine.
Advancing Generalization in PINNs through Latent-Space Representations
Nov 28, 2024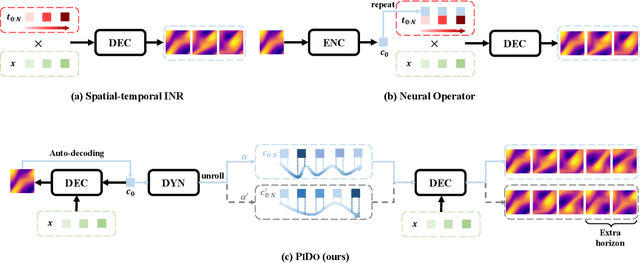
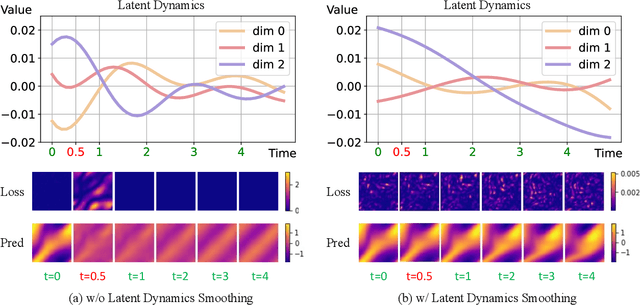
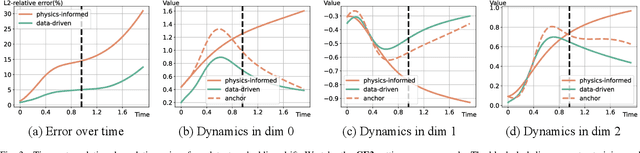
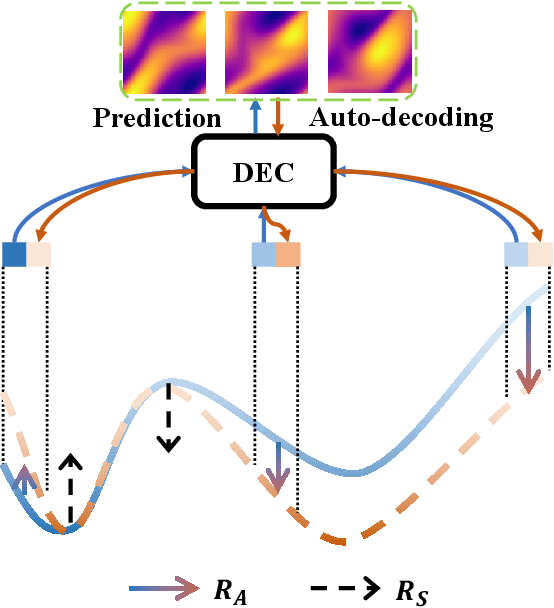
Physics-informed neural networks (PINNs) have made significant strides in modeling dynamical systems governed by partial differential equations (PDEs). However, their generalization capabilities across varying scenarios remain limited. To overcome this limitation, we propose PIDO, a novel physics-informed neural PDE solver designed to generalize effectively across diverse PDE configurations, including varying initial conditions, PDE coefficients, and training time horizons. PIDO exploits the shared underlying structure of dynamical systems with different properties by projecting PDE solutions into a latent space using auto-decoding. It then learns the dynamics of these latent representations, conditioned on the PDE coefficients. Despite its promise, integrating latent dynamics models within a physics-informed framework poses challenges due to the optimization difficulties associated with physics-informed losses. To address these challenges, we introduce a novel approach that diagnoses and mitigates these issues within the latent space. This strategy employs straightforward yet effective regularization techniques, enhancing both the temporal extrapolation performance and the training stability of PIDO. We validate PIDO on a range of benchmarks, including 1D combined equations and 2D Navier-Stokes equations. Additionally, we demonstrate the transferability of its learned representations to downstream applications such as long-term integration and inverse problems.
Exploring contextual modeling with linear complexity for point cloud segmentation
Oct 28, 2024



Point cloud segmentation is an important topic in 3D understanding that has traditionally has been tackled using either the CNN or Transformer. Recently, Mamba has emerged as a promising alternative, offering efficient long-range contextual modeling capabilities without the quadratic complexity associated with Transformer's attention mechanisms. However, despite Mamba's potential, early efforts have all failed to achieve better performance than the best CNN-based and Transformer-based methods. In this work, we address this challenge by identifying the key components of an effective and efficient point cloud segmentation architecture. Specifically, we show that: 1) Spatial locality and robust contextual understanding are critical for strong performance, and 2) Mamba features linear computational complexity, offering superior data and inference efficiency compared to Transformers, while still being capable of delivering strong contextual understanding. Additionally, we further enhance the standard Mamba specifically for point cloud segmentation by identifying its two key shortcomings. First, the enforced causality in the original Mamba is unsuitable for processing point clouds that have no such dependencies. Second, its unidirectional scanning strategy imposes a directional bias, hampering its ability to capture the full context of unordered point clouds in a single pass. To address these issues, we carefully remove the causal convolutions and introduce a novel Strided Bidirectional SSM to enhance the model's capability to capture spatial relationships. Our efforts culminate in the development of a novel architecture named MEEPO, which effectively integrates the strengths of CNN and Mamba. MEEPO surpasses the previous state-of-the-art method, PTv3, by up to +0.8 mIoU on multiple key benchmark datasets, while being 42.1% faster and 5.53x more memory efficient.
Efficient Diffusion Transformer with Step-wise Dynamic Attention Mediators
Aug 11, 2024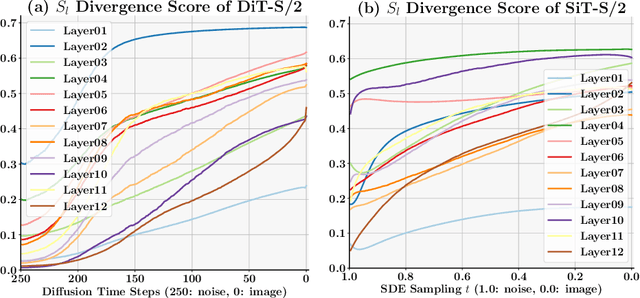
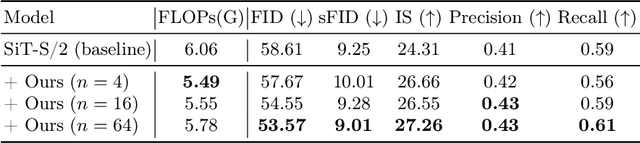
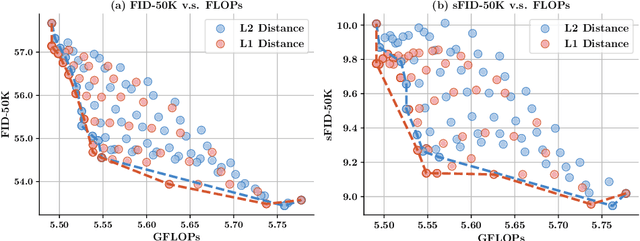
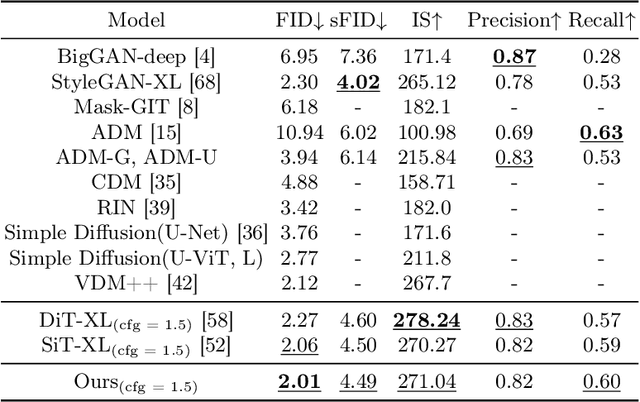
This paper identifies significant redundancy in the query-key interactions within self-attention mechanisms of diffusion transformer models, particularly during the early stages of denoising diffusion steps. In response to this observation, we present a novel diffusion transformer framework incorporating an additional set of mediator tokens to engage with queries and keys separately. By modulating the number of mediator tokens during the denoising generation phases, our model initiates the denoising process with a precise, non-ambiguous stage and gradually transitions to a phase enriched with detail. Concurrently, integrating mediator tokens simplifies the attention module's complexity to a linear scale, enhancing the efficiency of global attention processes. Additionally, we propose a time-step dynamic mediator token adjustment mechanism that further decreases the required computational FLOPs for generation, simultaneously facilitating the generation of high-quality images within the constraints of varied inference budgets. Extensive experiments demonstrate that the proposed method can improve the generated image quality while also reducing the inference cost of diffusion transformers. When integrated with the recent work SiT, our method achieves a state-of-the-art FID score of 2.01. The source code is available at https://github.com/LeapLabTHU/Attention-Mediators.