 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinear-Time Global Visual Modeling without Explicit Attention
May 06, 2026Existing research largely attributes the global sequence modeling capability of Transformers to the explicit computation of attention weights, a process that inherently incurs quadratic computational complexity. In this work, we offer a novel perspective: we demonstrate that attention can be mathematically reframed as a Multi-Layer Perceptron (MLP) equipped with dynamically predicted parameters. Through this lens, we explain attention's global modeling power not as explicit token-wise aggregation, but as an implicit process where dynamically generated parameters act as a compressed representation of the global context. Inspired by this insight, we investigate a fundamental question: can we achieve Transformer-level sequence global modeling entirely through dynamic parameterization while maintaining linear complexity, effectively replacing explicit attention? To explore this, we design various dynamic parameter prediction strategies and integrate them into standard network layers. Extensive empirical studies on vision models demonstrate that dynamic parameterization can indeed serve as a highly effective, linear-complexity alternative to explicit attention, opening new pathways for efficient sequence modeling. Code is available at https://github.com/LeapLabTHU/WeightFormer.
Linearizing Vision Transformer with Test-Time Training
May 04, 2026While linear-complexity attention mechanisms offer a promising alternative to Softmax attention for overcoming the quadratic bottleneck, training such models from scratch remains prohibitively expensive. Inheriting weights from pretrained Transformers provides an appealing shortcut, yet the fundamental representational gap between Softmax and linear attention prevents effective weight transfer. In this work, we address this conversion challenge from two perspectives: architectural alignment and representational alignment. We identify Test-Time Training (TTT) as a linear-complexity architecture whose two-layer dynamic formulation is structurally aligned with Softmax attention, enabling direct inheritance of pretrained attention weights. To further align representational properties, including key shift-invariance and locality, we introduce key instance normalization and a lightweight locality enhancement module. We validate our approach by linearizing Stable Diffusion 3.5 and introduce SD3.5-T$^5$ (Transformer To Test Time Training). With only 1 hour of fine-tuning on 4$\times$H20 GPUs, SD3.5-T$^5$ achieves comparable text-to-image quality to the fine-tuned Softmax model, while accelerating inference by 1.32$\times$ and 1.47$\times$ at 1K and 2K resolutions.
SiameseNorm: Breaking the Barrier to Reconciling Pre/Post-Norm
Feb 08, 2026Modern Transformers predominantly adopt the Pre-Norm paradigm for its optimization stability, foregoing the superior potential of the unstable Post-Norm architecture. Prior attempts to combine their strengths typically lead to a stability-performance trade-off. We attribute this phenomenon to a structural incompatibility within a single-stream design: Any application of the Post-Norm operation inevitably obstructs the clean identity gradient preserved by Pre-Norm. To fundamentally reconcile these paradigms, we propose SiameseNorm, a two-stream architecture that couples Pre-Norm-like and Post-Norm-like streams with shared parameters. This design decouples the optimization dynamics of the two streams, retaining the distinct characteristics of both Pre-Norm and Post-Norm by enabling all residual blocks to receive combined gradients inherited from both paradigms, where one stream secures stability while the other enhances expressivity. Extensive pre-training experiments on 1.3B-parameter models demonstrate that SiameseNorm exhibits exceptional optimization robustness and consistently outperforms strong baselines. Code is available at https://github.com/Qwen-Applications/SiameseNorm.
LINA: Linear Autoregressive Image Generative Models with Continuous Tokens
Jan 30, 2026Autoregressive models with continuous tokens form a promising paradigm for visual generation, especially for text-to-image (T2I) synthesis, but they suffer from high computational cost. We study how to design compute-efficient linear attention within this framework. Specifically, we conduct a systematic empirical analysis of scaling behavior with respect to parameter counts under different design choices, focusing on (1) normalization paradigms in linear attention (division-based vs. subtraction-based) and (2) depthwise convolution for locality augmentation. Our results show that although subtraction-based normalization is effective for image classification, division-based normalization scales better for linear generative transformers. In addition, incorporating convolution for locality modeling plays a crucial role in autoregressive generation, consistent with findings in diffusion models. We further extend gating mechanisms, commonly used in causal linear attention, to the bidirectional setting and propose a KV gate. By introducing data-independent learnable parameters to the key and value states, the KV gate assigns token-wise memory weights, enabling flexible memory management similar to forget gates in language models. Based on these findings, we present LINA, a simple and compute-efficient T2I model built entirely on linear attention, capable of generating high-fidelity 1024x1024 images from user instructions. LINA achieves competitive performance on both class-conditional and T2I benchmarks, obtaining 2.18 FID on ImageNet (about 1.4B parameters) and 0.74 on GenEval (about 1.5B parameters). A single linear attention module reduces FLOPs by about 61 percent compared to softmax attention. Code and models are available at: https://github.com/techmonsterwang/LINA.
Vision Transformers are Circulant Attention Learners
Dec 25, 2025The self-attention mechanism has been a key factor in the advancement of vision Transformers. However, its quadratic complexity imposes a heavy computational burden in high-resolution scenarios, restricting the practical application. Previous methods attempt to mitigate this issue by introducing handcrafted patterns such as locality or sparsity, which inevitably compromise model capacity. In this paper, we present a novel attention paradigm termed \textbf{Circulant Attention} by exploiting the inherent efficient pattern of self-attention. Specifically, we first identify that the self-attention matrix in vision Transformers often approximates the Block Circulant matrix with Circulant Blocks (BCCB), a kind of structured matrix whose multiplication with other matrices can be performed in $\mathcal{O}(N\log N)$ time. Leveraging this interesting pattern, we explicitly model the attention map as its nearest BCCB matrix and propose an efficient computation algorithm for fast calculation. The resulting approach closely mirrors vanilla self-attention, differing only in its use of BCCB matrices. Since our design is inspired by the inherent efficient paradigm, it not only delivers $\mathcal{O}(N\log N)$ computation complexity, but also largely maintains the capacity of standard self-attention. Extensive experiments on diverse visual tasks demonstrate the effectiveness of our approach, establishing circulant attention as a promising alternative to self-attention for vision Transformer architectures. Code is available at https://github.com/LeapLabTHU/Circulant-Attention.
Step by Step Network
Nov 18, 2025Scaling up network depth is a fundamental pursuit in neural architecture design, as theory suggests that deeper models offer exponentially greater capability. Benefiting from the residual connections, modern neural networks can scale up to more than one hundred layers and enjoy wide success. However, as networks continue to deepen, current architectures often struggle to realize their theoretical capacity improvements, calling for more advanced designs to further unleash the potential of deeper networks. In this paper, we identify two key barriers that obstruct residual models from scaling deeper: shortcut degradation and limited width. Shortcut degradation hinders deep-layer learning, while the inherent depth-width trade-off imposes limited width. To mitigate these issues, we propose a generalized residual architecture dubbed Step by Step Network (StepsNet) to bridge the gap between theoretical potential and practical performance of deep models. Specifically, we separate features along the channel dimension and let the model learn progressively via stacking blocks with increasing width. The resulting method mitigates the two identified problems and serves as a versatile macro design applicable to various models. Extensive experiments show that our method consistently outperforms residual models across diverse tasks, including image classification, object detection, semantic segmentation, and language modeling. These results position StepsNet as a superior generalization of the widely adopted residual architecture.
Bridging the Divide: Reconsidering Softmax and Linear Attention
Dec 09, 2024



Widely adopted in modern Vision Transformer designs, Softmax attention can effectively capture long-range visual information; however, it incurs excessive computational cost when dealing with high-resolution inputs. In contrast, linear attention naturally enjoys linear complexity and has great potential to scale up to higher-resolution images. Nonetheless, the unsatisfactory performance of linear attention greatly limits its practical application in various scenarios. In this paper, we take a step forward to close the gap between the linear and Softmax attention with novel theoretical analyses, which demystify the core factors behind the performance deviations. Specifically, we present two key perspectives to understand and alleviate the limitations of linear attention: the injective property and the local modeling ability. Firstly, we prove that linear attention is not injective, which is prone to assign identical attention weights to different query vectors, thus adding to severe semantic confusion since different queries correspond to the same outputs. Secondly, we confirm that effective local modeling is essential for the success of Softmax attention, in which linear attention falls short. The aforementioned two fundamental differences significantly contribute to the disparities between these two attention paradigms, which is demonstrated by our substantial empirical validation in the paper. In addition, more experiment results indicate that linear attention, as long as endowed with these two properties, can outperform Softmax attention across various tasks while maintaining lower computation complexity. Code is available at https://github.com/LeapLabTHU/InLine.
Efficient Diffusion Transformer with Step-wise Dynamic Attention Mediators
Aug 11, 2024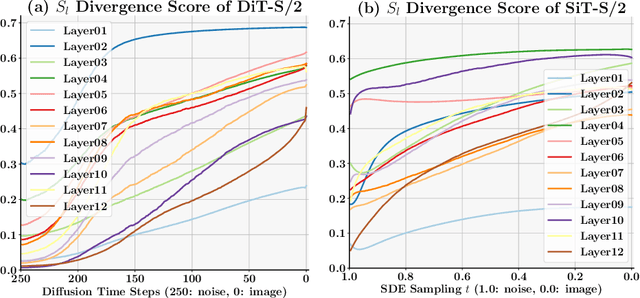
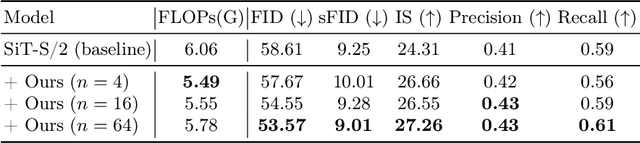
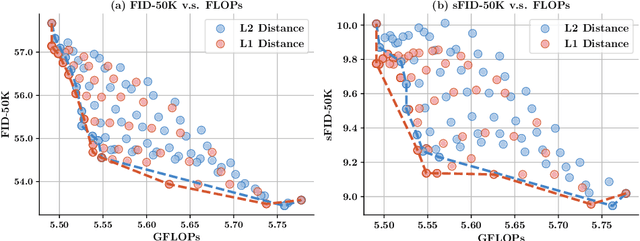
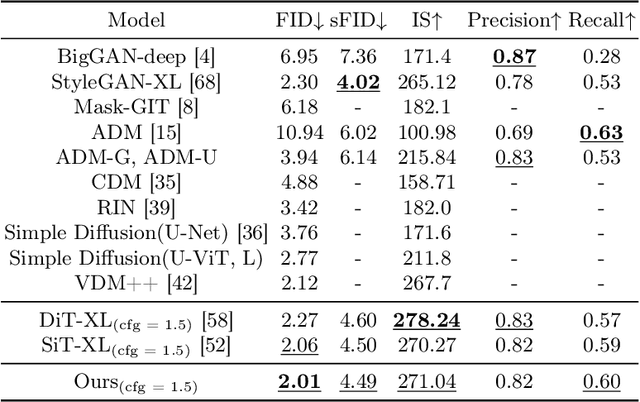
This paper identifies significant redundancy in the query-key interactions within self-attention mechanisms of diffusion transformer models, particularly during the early stages of denoising diffusion steps. In response to this observation, we present a novel diffusion transformer framework incorporating an additional set of mediator tokens to engage with queries and keys separately. By modulating the number of mediator tokens during the denoising generation phases, our model initiates the denoising process with a precise, non-ambiguous stage and gradually transitions to a phase enriched with detail. Concurrently, integrating mediator tokens simplifies the attention module's complexity to a linear scale, enhancing the efficiency of global attention processes. Additionally, we propose a time-step dynamic mediator token adjustment mechanism that further decreases the required computational FLOPs for generation, simultaneously facilitating the generation of high-quality images within the constraints of varied inference budgets. Extensive experiments demonstrate that the proposed method can improve the generated image quality while also reducing the inference cost of diffusion transformers. When integrated with the recent work SiT, our method achieves a state-of-the-art FID score of 2.01. The source code is available at https://github.com/LeapLabTHU/Attention-Mediators.
Demystify Mamba in Vision: A Linear Attention Perspective
May 26, 2024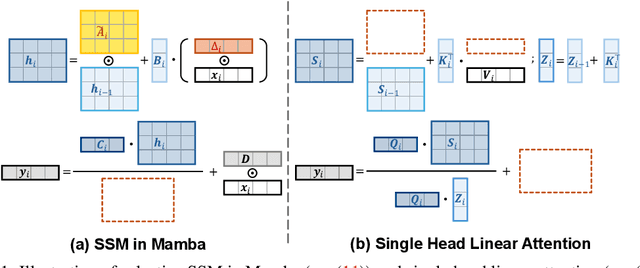
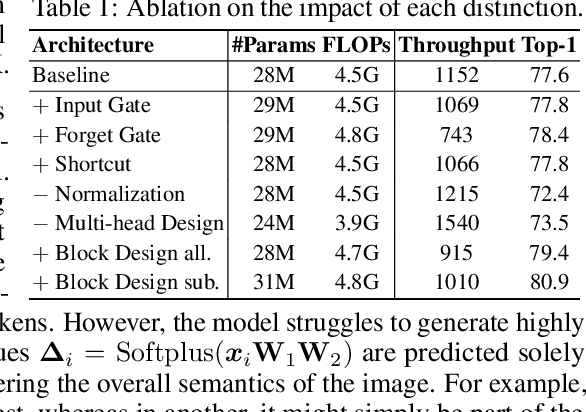
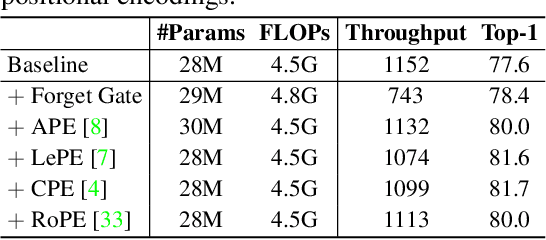
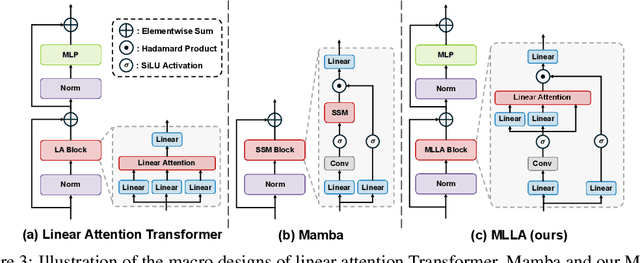
Mamba is an effective state space model with linear computation complexity. It has recently shown impressive efficiency in dealing with high-resolution inputs across various vision tasks. In this paper, we reveal that the powerful Mamba model shares surprising similarities with linear attention Transformer, which typically underperform conventional Transformer in practice. By exploring the similarities and disparities between the effective Mamba and subpar linear attention Transformer, we provide comprehensive analyses to demystify the key factors behind Mamba's success. Specifically, we reformulate the selective state space model and linear attention within a unified formulation, rephrasing Mamba as a variant of linear attention Transformer with six major distinctions: input gate, forget gate, shortcut, no attention normalization, single-head, and modified block design. For each design, we meticulously analyze its pros and cons, and empirically evaluate its impact on model performance in vision tasks. Interestingly, the results highlight the forget gate and block design as the core contributors to Mamba's success, while the other four designs are less crucial. Based on these findings, we propose a Mamba-Like Linear Attention (MLLA) model by incorporating the merits of these two key designs into linear attention. The resulting model outperforms various vision Mamba models in both image classification and high-resolution dense prediction tasks, while enjoying parallelizable computation and fast inference speed. Code is available at https://github.com/LeapLabTHU/MLLA.
VL-Trojan: Multimodal Instruction Backdoor Attacks against Autoregressive Visual Language Models
Feb 21, 2024

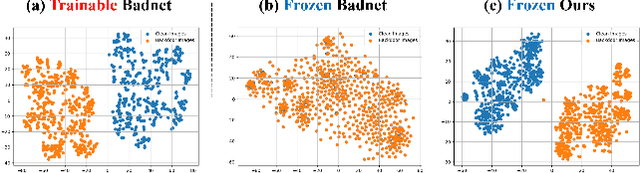
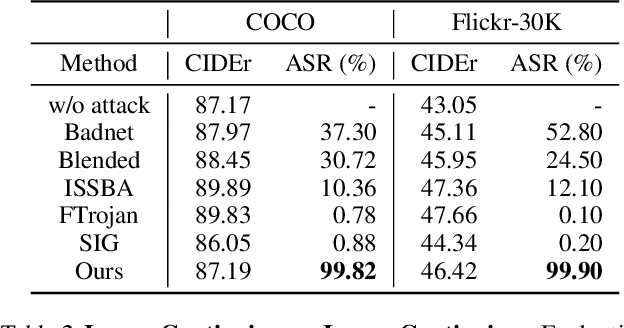
Autoregressive Visual Language Models (VLMs) showcase impressive few-shot learning capabilities in a multimodal context. Recently, multimodal instruction tuning has been proposed to further enhance instruction-following abilities. However, we uncover the potential threat posed by backdoor attacks on autoregressive VLMs during instruction tuning. Adversaries can implant a backdoor by injecting poisoned samples with triggers embedded in instructions or images, enabling malicious manipulation of the victim model's predictions with predefined triggers. Nevertheless, the frozen visual encoder in autoregressive VLMs imposes constraints on the learning of conventional image triggers. Additionally, adversaries may encounter restrictions in accessing the parameters and architectures of the victim model. To address these challenges, we propose a multimodal instruction backdoor attack, namely VL-Trojan. Our approach facilitates image trigger learning through an isolating and clustering strategy and enhance black-box-attack efficacy via an iterative character-level text trigger generation method. Our attack successfully induces target outputs during inference, significantly surpassing baselines (+62.52\%) in ASR. Moreover, it demonstrates robustness across various model scales and few-shot in-context reasoning scenarios.