 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVL-Trojan: Multimodal Instruction Backdoor Attacks against Autoregressive Visual Language Models
Paper and Code
Feb 21, 2024

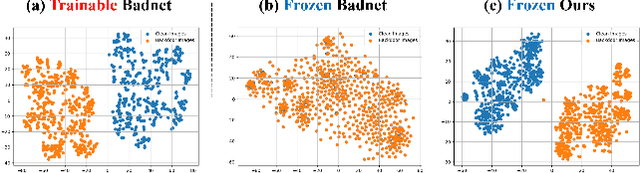
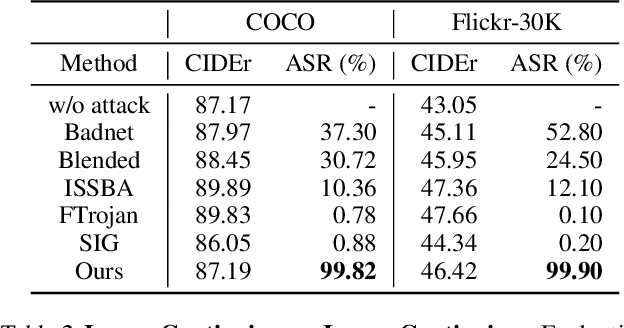
Autoregressive Visual Language Models (VLMs) showcase impressive few-shot learning capabilities in a multimodal context. Recently, multimodal instruction tuning has been proposed to further enhance instruction-following abilities. However, we uncover the potential threat posed by backdoor attacks on autoregressive VLMs during instruction tuning. Adversaries can implant a backdoor by injecting poisoned samples with triggers embedded in instructions or images, enabling malicious manipulation of the victim model's predictions with predefined triggers. Nevertheless, the frozen visual encoder in autoregressive VLMs imposes constraints on the learning of conventional image triggers. Additionally, adversaries may encounter restrictions in accessing the parameters and architectures of the victim model. To address these challenges, we propose a multimodal instruction backdoor attack, namely VL-Trojan. Our approach facilitates image trigger learning through an isolating and clustering strategy and enhance black-box-attack efficacy via an iterative character-level text trigger generation method. Our attack successfully induces target outputs during inference, significantly surpassing baselines (+62.52\%) in ASR. Moreover, it demonstrates robustness across various model scales and few-shot in-context reasoning scenarios.