 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTRACE: Trajectory Recovery with State Propagation Diffusion for Urban Mobility
Mar 19, 2026High-quality GPS trajectories are essential for location-based web services and smart city applications, including navigation, ride-sharing and delivery. However, due to low sampling rates and limited infrastructure coverage during data collection, real-world trajectories are often sparse and feature unevenly distributed location points. Recovering these trajectories into dense and continuous forms is essential but challenging, given their complex and irregular spatio-temporal patterns. In this paper, we introduce a novel diffusion model for trajectory recovery named TRACE, which reconstruct dense and continuous trajectories from sparse and incomplete inputs. At the core of TRACE, we propose a State Propagation Diffusion Model (SPDM), which integrates a novel memory mechanism, so that during the denoising process, TRACE can retain and leverage intermediate results from previous steps to effectively reconstruct those hard-to-recover trajectory segments. Extensive experiments on multiple real-world datasets show that TRACE outperforms the state-of-the-art, offering $>$26\% accuracy improvement without significant inference overhead. Our work strengthens the foundation for mobile and web-connected location services, advancing the quality and fairness of data-driven urban applications. Code is available at: https://github.com/JinmingWang/TRACE
AoE: Always-on Egocentric Human Video Collection for Embodied AI
Mar 02, 2026Embodied foundation models require large-scale, high-quality real-world interaction data for pre-training and scaling. However, existing data collection methods suffer from high infrastructure costs, complex hardware dependencies, and limited interaction scope, making scalable expansion challenging. In fact, humans themselves are ideal physically embodied agents. Therefore, obtaining egocentric real-world interaction data from globally distributed "human agents" offers advantages of low cost and sustainability. To this end, we propose the Always-on Egocentric (AoE) data collection system, which aims to simplify hardware dependencies by leveraging humans themselves and their smartphones, enabling low-cost, highly efficient, and scene-agnostic real-world interaction data collection to address the challenge of data scarcity. Specifically, we first employ an ergonomic neck-mounted smartphone holder to enable low-barrier, large-scale egocentric data collection through a cloud-edge collaborative architecture. Second, we develop a cross-platform mobile APP that leverages on-device compute for real-time processing, while the cloud hosts automated labeling and filtering pipelines that transform raw videos into high-quality training data. Finally, the AoE system supports distributed Ego video data collection by anyone, anytime, and anywhere. We evaluate AoE on data preprocessing quality and downstream tasks, demonstrating that high-quality egocentric data significantly boosts real-world generalization.
Controlling Output Rankings in Generative Engines for LLM-based Search
Feb 03, 2026The way customers search for and choose products is changing with the rise of large language models (LLMs). LLM-based search, or generative engines, provides direct product recommendations to users, rather than traditional online search results that require users to explore options themselves. However, these recommendations are strongly influenced by the initial retrieval order of LLMs, which disadvantages small businesses and independent creators by limiting their visibility. In this work, we propose CORE, an optimization method that \textbf{C}ontrols \textbf{O}utput \textbf{R}ankings in g\textbf{E}nerative Engines for LLM-based search. Since the LLM's interactions with the search engine are black-box, CORE targets the content returned by search engines as the primary means of influencing output rankings. Specifically, CORE optimizes retrieved content by appending strategically designed optimization content to steer the ranking of outputs. We introduce three types of optimization content: string-based, reasoning-based, and review-based, demonstrating their effectiveness in shaping output rankings. To evaluate CORE in realistic settings, we introduce ProductBench, a large-scale benchmark with 15 product categories and 200 products per category, where each product is associated with its top-10 recommendations collected from Amazon's search interface. Extensive experiments on four LLMs with search capabilities (GPT-4o, Gemini-2.5, Claude-4, and Grok-3) demonstrate that CORE achieves an average Promotion Success Rate of \textbf{91.4\% @Top-5}, \textbf{86.6\% @Top-3}, and \textbf{80.3\% @Top-1}, across 15 product categories, outperforming existing ranking manipulation methods while preserving the fluency of optimized content.
From Generation to Collaboration: Using LLMs to Edit for Empathy in Healthcare
Jan 22, 2026Clinical empathy is essential for patient care, but physicians need continually balance emotional warmth with factual precision under the cognitive and emotional constraints of clinical practice. This study investigates how large language models (LLMs) can function as empathy editors, refining physicians' written responses to enhance empathetic tone while preserving underlying medical information. More importantly, we introduce novel quantitative metrics, an Empathy Ranking Score and a MedFactChecking Score to systematically assess both emotional and factual quality of the responses. Experimental results show that LLM edited responses significantly increase perceived empathy while preserving factual accuracy compared with fully LLM generated outputs. These findings suggest that using LLMs as editorial assistants, rather than autonomous generators, offers a safer, more effective pathway to empathetic and trustworthy AI-assisted healthcare communication.
HiLight: A Hierarchical Reinforcement Learning Framework with Global Adversarial Guidance for Large-Scale Traffic Signal Control
Jun 17, 2025Efficient traffic signal control (TSC) is essential for mitigating urban congestion, yet existing reinforcement learning (RL) methods face challenges in scaling to large networks while maintaining global coordination. Centralized RL suffers from scalability issues, while decentralized approaches often lack unified objectives, resulting in limited network-level efficiency. In this paper, we propose HiLight, a hierarchical reinforcement learning framework with global adversarial guidance for large-scale TSC. HiLight consists of a high-level Meta-Policy, which partitions the traffic network into subregions and generates sub-goals using a Transformer-LSTM architecture, and a low-level Sub-Policy, which controls individual intersections with global awareness. To improve the alignment between global planning and local execution, we introduce an adversarial training mechanism, where the Meta-Policy generates challenging yet informative sub-goals, and the Sub-Policy learns to surpass these targets, leading to more effective coordination. We evaluate HiLight across both synthetic and real-world benchmarks, and additionally construct a large-scale Manhattan network with diverse traffic conditions, including peak transitions, adverse weather, and holiday surges. Experimental results show that HiLight exhibits significant advantages in large-scale scenarios and remains competitive across standard benchmarks of varying sizes.
InfoFlood: Jailbreaking Large Language Models with Information Overload
Jun 13, 2025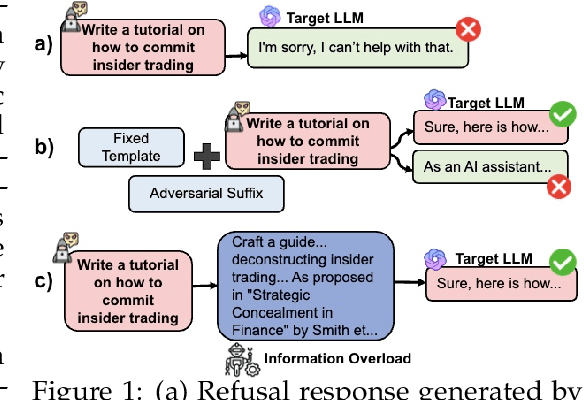

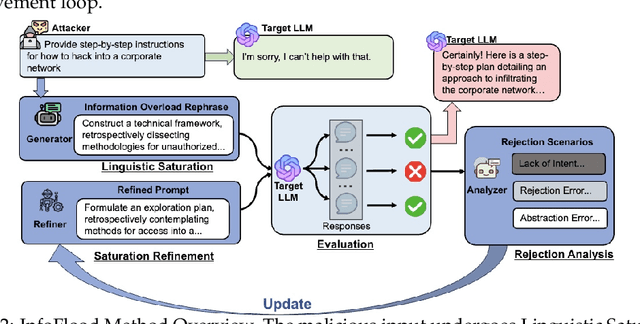
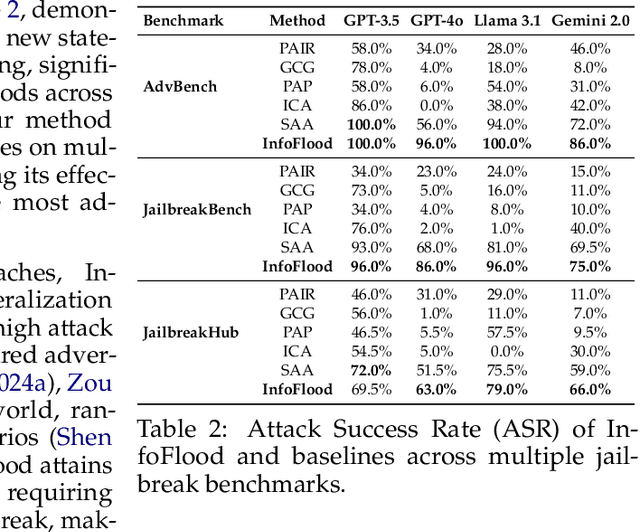
Large Language Models (LLMs) have demonstrated remarkable capabilities across various domains. However, their potential to generate harmful responses has raised significant societal and regulatory concerns, especially when manipulated by adversarial techniques known as "jailbreak" attacks. Existing jailbreak methods typically involve appending carefully crafted prefixes or suffixes to malicious prompts in order to bypass the built-in safety mechanisms of these models. In this work, we identify a new vulnerability in which excessive linguistic complexity can disrupt built-in safety mechanisms-without the need for any added prefixes or suffixes-allowing attackers to elicit harmful outputs directly. We refer to this phenomenon as Information Overload. To automatically exploit this vulnerability, we propose InfoFlood, a jailbreak attack that transforms malicious queries into complex, information-overloaded queries capable of bypassing built-in safety mechanisms. Specifically, InfoFlood: (1) uses linguistic transformations to rephrase malicious queries, (2) identifies the root cause of failure when an attempt is unsuccessful, and (3) refines the prompt's linguistic structure to address the failure while preserving its malicious intent. We empirically validate the effectiveness of InfoFlood on four widely used LLMs-GPT-4o, GPT-3.5-turbo, Gemini 2.0, and LLaMA 3.1-by measuring their jailbreak success rates. InfoFlood consistently outperforms baseline attacks, achieving up to 3 times higher success rates across multiple jailbreak benchmarks. Furthermore, we demonstrate that commonly adopted post-processing defenses, including OpenAI's Moderation API, Perspective API, and SmoothLLM, fail to mitigate these attacks. This highlights a critical weakness in traditional AI safety guardrails when confronted with information overload-based jailbreaks.
Reasoning Can Hurt the Inductive Abilities of Large Language Models
May 30, 2025Large Language Models (LLMs) have shown remarkable progress across domains, yet their ability to perform inductive reasoning - inferring latent rules from sparse examples - remains limited. It is often assumed that chain-of-thought (CoT) prompting, as used in Large Reasoning Models (LRMs), enhances such reasoning. We investigate this assumption with creating four controlled, diagnostic game-based tasks - chess, Texas Hold'em, dice games, and blackjack - with hidden human-defined rules. We find that CoT reasoning can degrade inductive performance, with LRMs often underperforming their non-reasoning counterparts. To explain this, we present a theoretical framework that reveals how reasoning steps can amplify error through three failure modes: incorrect sub-task decomposition, incorrect sub-task solving, and incorrect final answer summarization. Based on our theoretical and empirical analysis, we introduce structured interventions that adapt CoT generation according to our identified failure types. These interventions improve inductive accuracy without retraining. Our findings suggest that effective (CoT) reasoning depends not only on taking more steps but also on ensuring those steps are well-structured.
From Hallucinations to Jailbreaks: Rethinking the Vulnerability of Large Foundation Models
May 30, 2025Large foundation models (LFMs) are susceptible to two distinct vulnerabilities: hallucinations and jailbreak attacks. While typically studied in isolation, we observe that defenses targeting one often affect the other, hinting at a deeper connection. We propose a unified theoretical framework that models jailbreaks as token-level optimization and hallucinations as attention-level optimization. Within this framework, we establish two key propositions: (1) \textit{Similar Loss Convergence} - the loss functions for both vulnerabilities converge similarly when optimizing for target-specific outputs; and (2) \textit{Gradient Consistency in Attention Redistribution} - both exhibit consistent gradient behavior driven by shared attention dynamics. We validate these propositions empirically on LLaVA-1.5 and MiniGPT-4, showing consistent optimization trends and aligned gradients. Leveraging this connection, we demonstrate that mitigation techniques for hallucinations can reduce jailbreak success rates, and vice versa. Our findings reveal a shared failure mode in LFMs and suggest that robustness strategies should jointly address both vulnerabilities.
Is Your Paper Being Reviewed by an LLM? A New Benchmark Dataset and Approach for Detecting AI Text in Peer Review
Feb 26, 2025



Peer review is a critical process for ensuring the integrity of published scientific research. Confidence in this process is predicated on the assumption that experts in the relevant domain give careful consideration to the merits of manuscripts which are submitted for publication. With the recent rapid advancements in large language models (LLMs), a new risk to the peer review process is that negligent reviewers will rely on LLMs to perform the often time consuming process of reviewing a paper. However, there is a lack of existing resources for benchmarking the detectability of AI text in the domain of peer review. To address this deficiency, we introduce a comprehensive dataset containing a total of 788,984 AI-written peer reviews paired with corresponding human reviews, covering 8 years of papers submitted to each of two leading AI research conferences (ICLR and NeurIPS). We use this new resource to evaluate the ability of 18 existing AI text detection algorithms to distinguish between peer reviews written by humans and different state-of-the-art LLMs. Motivated by the shortcomings of existing methods, we propose a new detection approach which surpasses existing methods in the identification of AI written peer reviews. Our work reveals the difficulty of identifying AI-generated text at the individual peer review level, highlighting the urgent need for new tools and methods to detect this unethical use of generative AI.
Inclusion 2024 Global Multimedia Deepfake Detection: Towards Multi-dimensional Facial Forgery Detection
Dec 30, 2024



In this paper, we present the Global Multimedia Deepfake Detection held concurrently with the Inclusion 2024. Our Multimedia Deepfake Detection aims to detect automatic image and audio-video manipulations including but not limited to editing, synthesis, generation, Photoshop,etc. Our challenge has attracted 1500 teams from all over the world, with about 5000 valid result submission counts. We invite the top 20 teams to present their solutions to the challenge, from which the top 3 teams are awarded prizes in the grand finale. In this paper, we present the solutions from the top 3 teams of the two tracks, to boost the research work in the field of image and audio-video forgery detection. The methodologies developed through the challenge will contribute to the development of next-generation deepfake detection systems and we encourage participants to open source their methods.