 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Semantic Parsing Framework for End-to-End Time Normalization
Jul 08, 2025Time normalization is the task of converting natural language temporal expressions into machine-readable representations. It underpins many downstream applications in information retrieval, question answering, and clinical decision-making. Traditional systems based on the ISO-TimeML schema limit expressivity and struggle with complex constructs such as compositional, event-relative, and multi-span time expressions. In this work, we introduce a novel formulation of time normalization as a code generation task grounded in the SCATE framework, which defines temporal semantics through symbolic and compositional operators. We implement a fully executable SCATE Python library and demonstrate that large language models (LLMs) can generate executable SCATE code. Leveraging this capability, we develop an automatic data augmentation pipeline using LLMs to synthesize large-scale annotated data with code-level validation. Our experiments show that small, locally deployable models trained on this augmented data can achieve strong performance, outperforming even their LLM parents and enabling practical, accurate, and interpretable time normalization.
LVLM-Compress-Bench: Benchmarking the Broader Impact of Large Vision-Language Model Compression
Mar 06, 2025Despite recent efforts in understanding the compression impact on large language models (LLMs) in terms of their downstream task performance and trustworthiness on relatively simpler uni-modal benchmarks (for example, question answering, common sense reasoning), their detailed study on multi-modal Large Vision-Language Models (LVLMs) is yet to be unveiled. Towards mitigating this gap, we present LVLM-Compress-Bench, a framework to first thoroughly study the broad impact of compression on the generative performance of LVLMs with multi-modal input driven tasks. In specific, we consider two major classes of compression for autoregressive models, namely KV cache and weight compression, for the dynamically growing intermediate cache and static weights, respectively. We use four LVLM variants of the popular LLaVA framework to present our analysis via integrating various state-of-the-art KV and weight compression methods including uniform, outlier-reduced, and group quantization for the KV cache and weights. With this framework we demonstrate on ten different multi-modal datasets with different capabilities including recognition, knowledge, language generation, spatial awareness, visual reasoning, hallucination and visual illusion identification, toxicity, stereotypes and bias. In specific, our framework demonstrates the compression impact on both general and ethically critical metrics leveraging a combination of real world and synthetic datasets to encompass diverse societal intersectional attributes. Extensive experimental evaluations yield diverse and intriguing observations on the behavior of LVLMs at different quantization budget of KV and weights, in both maintaining and losing performance as compared to the baseline model with FP16 data format. Code will be open-sourced at https://github.com/opengear-project/LVLM-compress-bench.
Is Your Paper Being Reviewed by an LLM? A New Benchmark Dataset and Approach for Detecting AI Text in Peer Review
Feb 26, 2025



Peer review is a critical process for ensuring the integrity of published scientific research. Confidence in this process is predicated on the assumption that experts in the relevant domain give careful consideration to the merits of manuscripts which are submitted for publication. With the recent rapid advancements in large language models (LLMs), a new risk to the peer review process is that negligent reviewers will rely on LLMs to perform the often time consuming process of reviewing a paper. However, there is a lack of existing resources for benchmarking the detectability of AI text in the domain of peer review. To address this deficiency, we introduce a comprehensive dataset containing a total of 788,984 AI-written peer reviews paired with corresponding human reviews, covering 8 years of papers submitted to each of two leading AI research conferences (ICLR and NeurIPS). We use this new resource to evaluate the ability of 18 existing AI text detection algorithms to distinguish between peer reviews written by humans and different state-of-the-art LLMs. Motivated by the shortcomings of existing methods, we propose a new detection approach which surpasses existing methods in the identification of AI written peer reviews. Our work reveals the difficulty of identifying AI-generated text at the individual peer review level, highlighting the urgent need for new tools and methods to detect this unethical use of generative AI.
Causal World Representation in the GPT Model
Dec 10, 2024Are generative pre-trained transformer (GPT) models only trained to predict the next token, or do they implicitly learn a world model from which a sequence is generated one token at a time? We examine this question by deriving a causal interpretation of the attention mechanism in GPT, and suggesting a causal world model that arises from this interpretation. Furthermore, we propose that GPT-models, at inference time, can be utilized for zero-shot causal structure learning for in-distribution sequences. Empirical evaluation is conducted in a controlled synthetic environment using the setup and rules of the Othello board game. A GPT, pre-trained on real-world games played with the intention of winning, is tested on synthetic data that only adheres to the game rules. We find that the GPT model tends to generate next moves that adhere to the game rules for sequences for which the attention mechanism encodes a causal structure with high confidence. In general, in cases for which the GPT model generates moves that do not adhere to the game rules, it also fails to capture any causal structure.
Is Your Paper Being Reviewed by an LLM? Investigating AI Text Detectability in Peer Review
Oct 03, 2024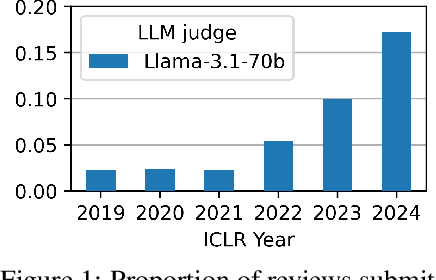
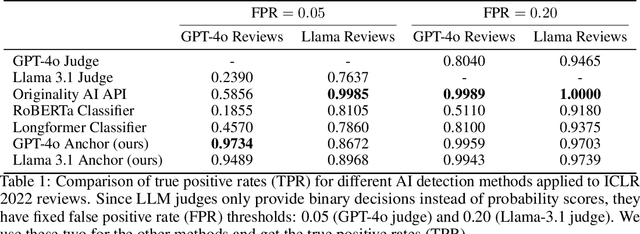
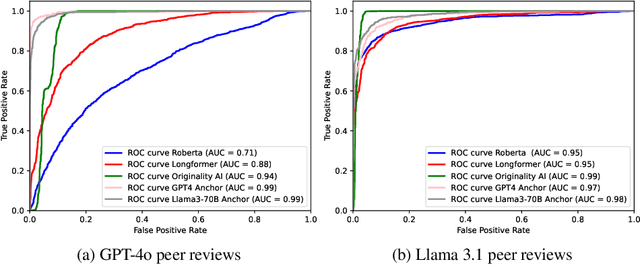
Peer review is a critical process for ensuring the integrity of published scientific research. Confidence in this process is predicated on the assumption that experts in the relevant domain give careful consideration to the merits of manuscripts which are submitted for publication. With the recent rapid advancements in the linguistic capabilities of large language models (LLMs), a new potential risk to the peer review process is that negligent reviewers will rely on LLMs to perform the often time consuming process of reviewing a paper. In this study, we investigate the ability of existing AI text detection algorithms to distinguish between peer reviews written by humans and different state-of-the-art LLMs. Our analysis shows that existing approaches fail to identify many GPT-4o written reviews without also producing a high number of false positive classifications. To address this deficiency, we propose a new detection approach which surpasses existing methods in the identification of GPT-4o written peer reviews at low levels of false positive classifications. Our work reveals the difficulty of accurately identifying AI-generated text at the individual review level, highlighting the urgent need for new tools and methods to detect this type of unethical application of generative AI.
ClimDetect: A Benchmark Dataset for Climate Change Detection and Attribution
Aug 28, 2024
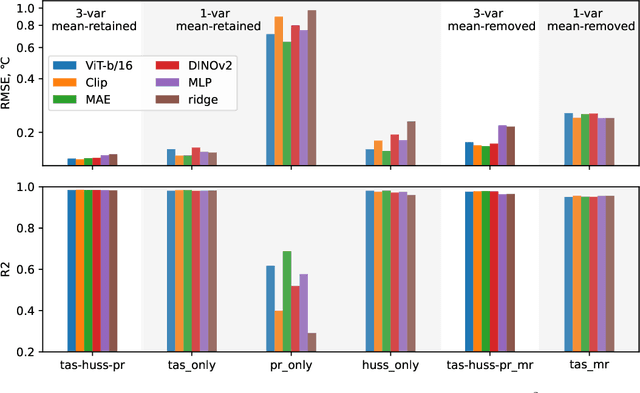
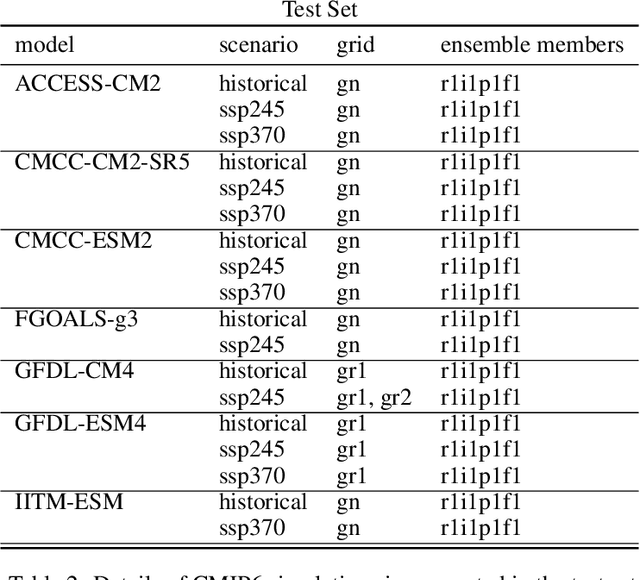
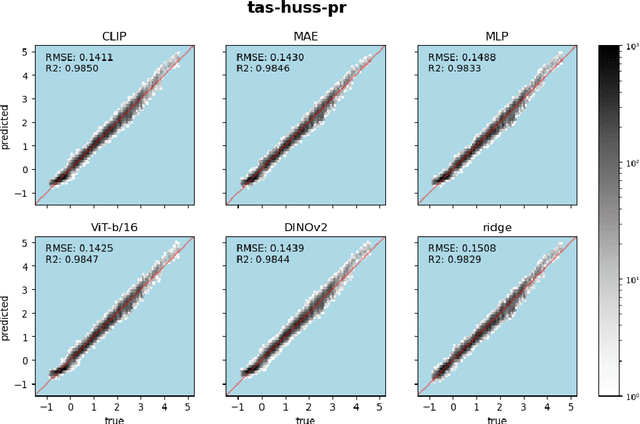
Detecting and attributing temperature increases due to climate change is crucial for understanding global warming and guiding adaptation strategies. The complexity of distinguishing human-induced climate signals from natural variability has challenged traditional detection and attribution (D&A) approaches, which seek to identify specific "fingerprints" in climate response variables. Deep learning offers potential for discerning these complex patterns in expansive spatial datasets. However, lack of standard protocols has hindered consistent comparisons across studies. We introduce ClimDetect, a standardized dataset of over 816k daily climate snapshots, designed to enhance model accuracy in identifying climate change signals. ClimDetect integrates various input and target variables used in past research, ensuring comparability and consistency. We also explore the application of vision transformers (ViT) to climate data, a novel and modernizing approach in this context. Our open-access data and code serve as a benchmark for advancing climate science through improved model evaluations. ClimDetect is publicly accessible via Huggingface dataet respository at: https://huggingface.co/datasets/ClimDetect/ClimDetect.
Why do LLaVA Vision-Language Models Reply to Images in English?
Jul 02, 2024
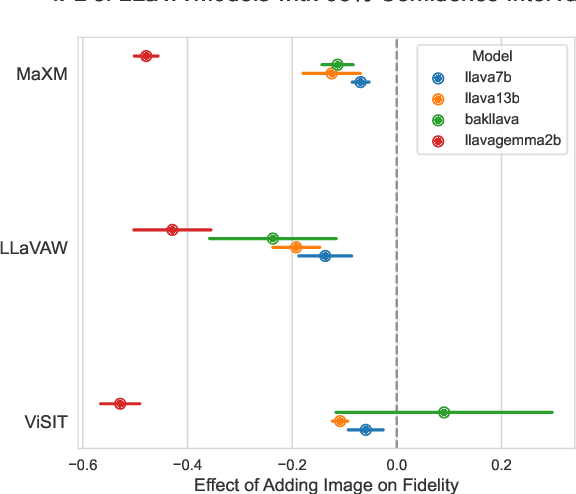
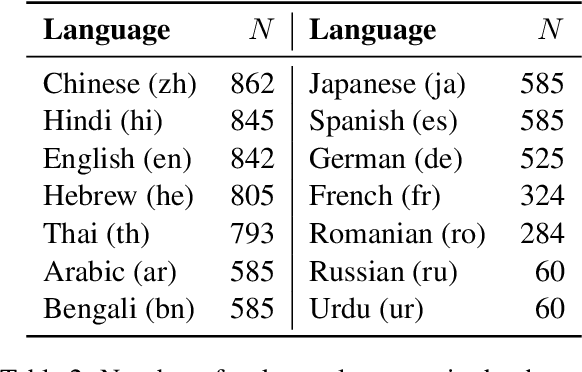
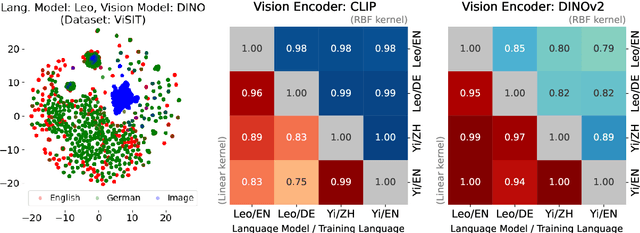
We uncover a surprising multilingual bias occurring in a popular class of multimodal vision-language models (VLMs). Including an image in the query to a LLaVA-style VLM significantly increases the likelihood of the model returning an English response, regardless of the language of the query. This paper investigates the causes of this loss with a two-pronged approach that combines extensive ablation of the design space with a mechanistic analysis of the models' internal representations of image and text inputs. Both approaches indicate that the issue stems in the language modelling component of the LLaVA model. Statistically, we find that switching the language backbone for a bilingual language model has the strongest effect on reducing this error. Mechanistically, we provide compelling evidence that visual inputs are not mapped to a similar space as text ones, and that intervening on intermediary attention layers can reduce this bias. Our findings provide important insights to researchers and engineers seeking to understand the crossover between multimodal and multilingual spaces, and contribute to the goal of developing capable and inclusive VLMs for non-English contexts.
ChaosBench: A Multi-Channel, Physics-Based Benchmark for Subseasonal-to-Seasonal Climate Prediction
Feb 01, 2024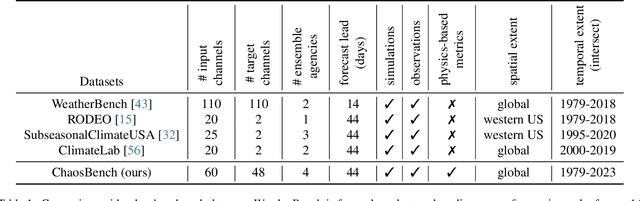
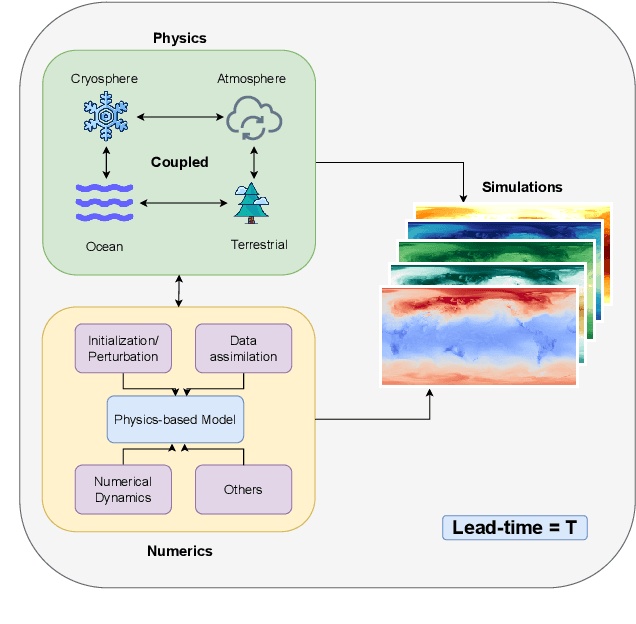

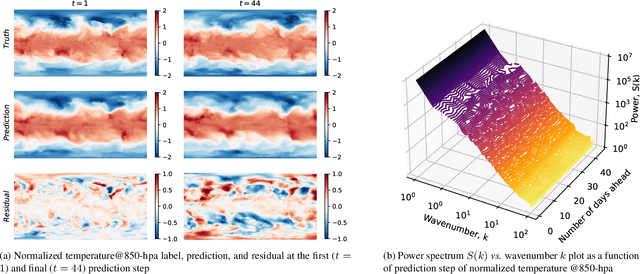
Accurate prediction of climate in the subseasonal-to-seasonal scale is crucial for disaster readiness, reduced economic risk, and improved policy-making amidst climate change. Yet, S2S prediction remains challenging due to the chaotic nature of the system. At present, existing benchmarks for weather and climate applications, tend to (1) have shorter forecasting range of up-to 14 days, (2) do not include a wide range of operational baseline forecasts, and (3) lack physics-based constraints for explainability. Thus, we propose ChaosBench, a large-scale, multi-channel, physics-based benchmark for S2S prediction. ChaosBench has over 460K frames of real-world observations and simulations, each with 60 variable-channels and spanning for up-to 45 years. We also propose several physics-based, in addition to vision-based metrics, that enables for a more physically-consistent model. Furthermore, we include a diverse set of physics-based forecasts from 4 national weather agencies as baselines to our data-driven counterpart. We establish two tasks that vary in complexity: full and sparse dynamics prediction. Our benchmark is one of the first to perform large-scale evaluation on existing models including PanguWeather, FourCastNetV2, GraphCast, and ClimaX, and finds methods originally developed for weather-scale applications fails on S2S task. We release our benchmark code and datasets at https://leap-stc.github.io/ChaosBench.
Systematic Sampling and Validation of Machine Learning-Parameterizations in Climate Models
Sep 28, 2023Progress in hybrid physics-machine learning (ML) climate simulations has been limited by the difficulty of obtaining performant coupled (i.e. online) simulations. While evaluating hundreds of ML parameterizations of subgrid closures (here of convection and radiation) offline is straightforward, online evaluation at the same scale is technically challenging. Our software automation achieves an order-of-magnitude larger sampling of online modeling errors than has previously been examined. Using this, we evaluate the hybrid climate model performance and define strategies to improve it. We show that model online performance improves when incorporating memory, a relative humidity input feature transformation, and additional input variables. We also reveal substantial variation in online error and inconsistencies between offline vs. online error statistics. The implication is that hundreds of candidate ML models should be evaluated online to detect the effects of parameterization design choices. This is considerably more sampling than tends to be reported in the current literature.
ClimSim: An open large-scale dataset for training high-resolution physics emulators in hybrid multi-scale climate simulators
Jun 16, 2023Modern climate projections lack adequate spatial and temporal resolution due to computational constraints. A consequence is inaccurate and imprecise prediction of critical processes such as storms. Hybrid methods that combine physics with machine learning (ML) have introduced a new generation of higher fidelity climate simulators that can sidestep Moore's Law by outsourcing compute-hungry, short, high-resolution simulations to ML emulators. However, this hybrid ML-physics simulation approach requires domain-specific treatment and has been inaccessible to ML experts because of lack of training data and relevant, easy-to-use workflows. We present ClimSim, the largest-ever dataset designed for hybrid ML-physics research. It comprises multi-scale climate simulations, developed by a consortium of climate scientists and ML researchers. It consists of 5.7 billion pairs of multivariate input and output vectors that isolate the influence of locally-nested, high-resolution, high-fidelity physics on a host climate simulator's macro-scale physical state. The dataset is global in coverage, spans multiple years at high sampling frequency, and is designed such that resulting emulators are compatible with downstream coupling into operational climate simulators. We implement a range of deterministic and stochastic regression baselines to highlight the ML challenges and their scoring. The data (https://huggingface.co/datasets/LEAP/ClimSim_high-res) and code (https://leap-stc.github.io/ClimSim) are released openly to support the development of hybrid ML-physics and high-fidelity climate simulations for the benefit of science and society.