 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Your Paper Being Reviewed by an LLM? Investigating AI Text Detectability in Peer Review
Paper and Code
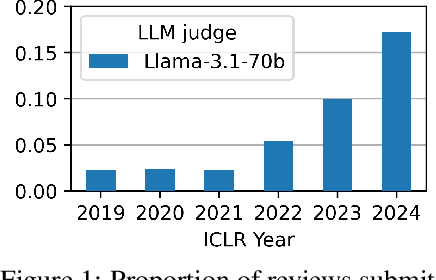
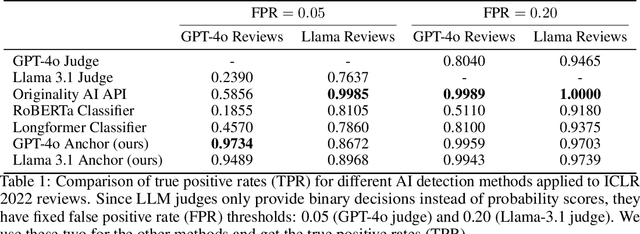
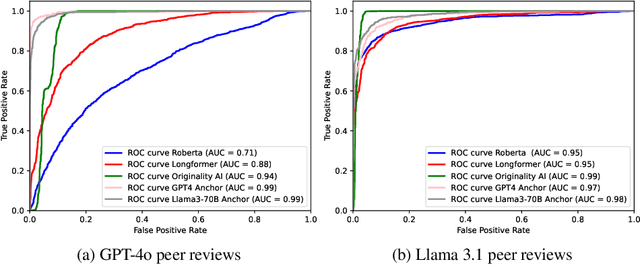
Peer review is a critical process for ensuring the integrity of published scientific research. Confidence in this process is predicated on the assumption that experts in the relevant domain give careful consideration to the merits of manuscripts which are submitted for publication. With the recent rapid advancements in the linguistic capabilities of large language models (LLMs), a new potential risk to the peer review process is that negligent reviewers will rely on LLMs to perform the often time consuming process of reviewing a paper. In this study, we investigate the ability of existing AI text detection algorithms to distinguish between peer reviews written by humans and different state-of-the-art LLMs. Our analysis shows that existing approaches fail to identify many GPT-4o written reviews without also producing a high number of false positive classifications. To address this deficiency, we propose a new detection approach which surpasses existing methods in the identification of GPT-4o written peer reviews at low levels of false positive classifications. Our work reveals the difficulty of accurately identifying AI-generated text at the individual review level, highlighting the urgent need for new tools and methods to detect this type of unethical application of generative AI.