 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing Hierarchical Structure in Vision Models with Sparse Autoencoders
May 21, 2025The ImageNet hierarchy provides a structured taxonomy of object categories, offering a valuable lens through which to analyze the representations learned by deep vision models. In this work, we conduct a comprehensive analysis of how vision models encode the ImageNet hierarchy, leveraging Sparse Autoencoders (SAEs) to probe their internal representations. SAEs have been widely used as an explanation tool for large language models (LLMs), where they enable the discovery of semantically meaningful features. Here, we extend their use to vision models to investigate whether learned representations align with the ontological structure defined by the ImageNet taxonomy. Our results show that SAEs uncover hierarchical relationships in model activations, revealing an implicit encoding of taxonomic structure. We analyze the consistency of these representations across different layers of the popular vision foundation model DINOv2 and provide insights into how deep vision models internalize hierarchical category information by increasing information in the class token through each layer. Our study establishes a framework for systematic hierarchical analysis of vision model representations and highlights the potential of SAEs as a tool for probing semantic structure in deep networks.
Learning from Reasoning Failures via Synthetic Data Generation
Apr 20, 2025Training models on synthetic data has emerged as an increasingly important strategy for improving the performance of generative AI. This approach is particularly helpful for large multimodal models (LMMs) due to the relative scarcity of high-quality paired image-text data compared to language-only data. While a variety of methods have been proposed for generating large multimodal datasets, they do not tailor the synthetic data to address specific deficiencies in the reasoning abilities of LMMs which will be trained with the generated dataset. In contrast, humans often learn in a more efficient manner by seeking out examples related to the types of reasoning where they have failed previously. Inspired by this observation, we propose a new approach for synthetic data generation which is grounded in the analysis of an existing LMM's reasoning failures. Our methodology leverages frontier models to automatically analyze errors produced by a weaker LMM and propose new examples which can be used to correct the reasoning failure via additional training, which are then further filtered to ensure high quality. We generate a large multimodal instruction tuning dataset containing over 553k examples using our approach and conduct extensive experiments demonstrating its utility for improving the performance of LMMs on multiple downstream tasks. Our results show that models trained on our synthetic data can even exceed the performance of LMMs trained on an equivalent amount of additional real data, demonstrating the high value of generating synthetic data targeted to specific reasoning failure modes in LMMs. We will make our dataset and code publicly available.
Quantifying Interpretability in CLIP Models with Concept Consistency
Mar 14, 2025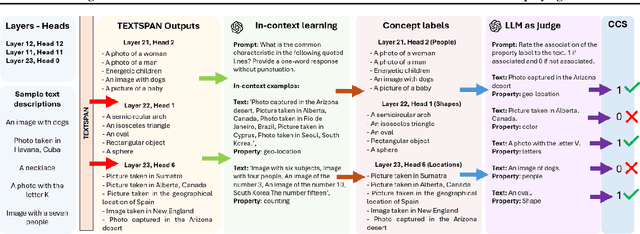
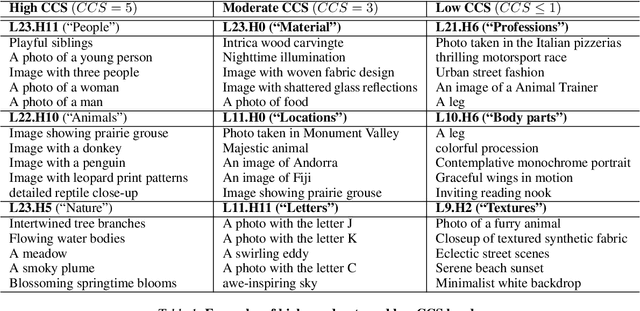
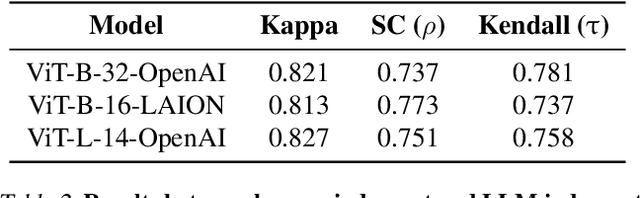
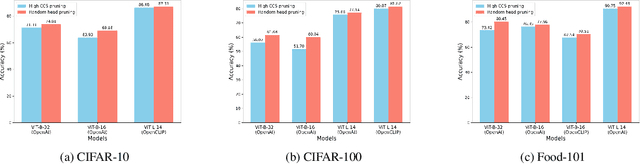
CLIP is one of the most popular foundational models and is heavily used for many vision-language tasks. However, little is known about the inner workings of CLIP. While recent work has proposed decomposition-based interpretability methods for identifying textual descriptions of attention heads in CLIP, the implications of conceptual consistency in these text labels on interpretability and model performance has not been explored. To bridge this gap, we study the conceptual consistency of text descriptions for attention heads in CLIP-like models. We conduct extensive experiments on six different models from OpenAI and OpenCLIP which vary by size, type of pre-training data and patch size. We propose Concept Consistency Score (CCS), a novel interpretability metric that measures how consistently individual attention heads in CLIP models align with specific concepts. To assign concept labels to heads, we use in-context learning with ChatGPT, guided by a few manually-curated examples, and validate these labels using an LLM-as-a-judge approach. Our soft-pruning experiments reveal that high CCS heads are critical for preserving model performance, as pruning them leads to a significantly larger performance drop than pruning random or low CCS heads. Notably, we find that high CCS heads capture essential concepts and play a key role in out-of-domain detection, concept-specific reasoning, and video-language understanding. These results position CCS as a powerful interpretability metric for analyzing CLIP-like models.
LVLM-Compress-Bench: Benchmarking the Broader Impact of Large Vision-Language Model Compression
Mar 06, 2025Despite recent efforts in understanding the compression impact on large language models (LLMs) in terms of their downstream task performance and trustworthiness on relatively simpler uni-modal benchmarks (for example, question answering, common sense reasoning), their detailed study on multi-modal Large Vision-Language Models (LVLMs) is yet to be unveiled. Towards mitigating this gap, we present LVLM-Compress-Bench, a framework to first thoroughly study the broad impact of compression on the generative performance of LVLMs with multi-modal input driven tasks. In specific, we consider two major classes of compression for autoregressive models, namely KV cache and weight compression, for the dynamically growing intermediate cache and static weights, respectively. We use four LVLM variants of the popular LLaVA framework to present our analysis via integrating various state-of-the-art KV and weight compression methods including uniform, outlier-reduced, and group quantization for the KV cache and weights. With this framework we demonstrate on ten different multi-modal datasets with different capabilities including recognition, knowledge, language generation, spatial awareness, visual reasoning, hallucination and visual illusion identification, toxicity, stereotypes and bias. In specific, our framework demonstrates the compression impact on both general and ethically critical metrics leveraging a combination of real world and synthetic datasets to encompass diverse societal intersectional attributes. Extensive experimental evaluations yield diverse and intriguing observations on the behavior of LVLMs at different quantization budget of KV and weights, in both maintaining and losing performance as compared to the baseline model with FP16 data format. Code will be open-sourced at https://github.com/opengear-project/LVLM-compress-bench.
Is Your Paper Being Reviewed by an LLM? A New Benchmark Dataset and Approach for Detecting AI Text in Peer Review
Feb 26, 2025



Peer review is a critical process for ensuring the integrity of published scientific research. Confidence in this process is predicated on the assumption that experts in the relevant domain give careful consideration to the merits of manuscripts which are submitted for publication. With the recent rapid advancements in large language models (LLMs), a new risk to the peer review process is that negligent reviewers will rely on LLMs to perform the often time consuming process of reviewing a paper. However, there is a lack of existing resources for benchmarking the detectability of AI text in the domain of peer review. To address this deficiency, we introduce a comprehensive dataset containing a total of 788,984 AI-written peer reviews paired with corresponding human reviews, covering 8 years of papers submitted to each of two leading AI research conferences (ICLR and NeurIPS). We use this new resource to evaluate the ability of 18 existing AI text detection algorithms to distinguish between peer reviews written by humans and different state-of-the-art LLMs. Motivated by the shortcomings of existing methods, we propose a new detection approach which surpasses existing methods in the identification of AI written peer reviews. Our work reveals the difficulty of identifying AI-generated text at the individual peer review level, highlighting the urgent need for new tools and methods to detect this unethical use of generative AI.
FiVL: A Framework for Improved Vision-Language Alignment
Dec 19, 2024



Large Vision Language Models (LVLMs) have achieved significant progress in integrating visual and textual inputs for multimodal reasoning. However, a recurring challenge is ensuring these models utilize visual information as effectively as linguistic content when both modalities are necessary to formulate an accurate answer. We hypothesize that hallucinations arise due to the lack of effective visual grounding in current LVLMs. This issue extends to vision-language benchmarks, where it is difficult to make the image indispensable for accurate answer generation, particularly in vision question-answering tasks. In this work, we introduce FiVL, a novel method for constructing datasets designed to train LVLMs for enhanced visual grounding and to evaluate their effectiveness in achieving it. These datasets can be utilized for both training and assessing an LVLM's ability to use image content as substantive evidence rather than relying solely on linguistic priors, providing insights into the model's reliance on visual information. To demonstrate the utility of our dataset, we introduce an innovative training task that outperforms baselines alongside a validation method and application for explainability. The code is available at https://github.com/IntelLabs/fivl.
Causal World Representation in the GPT Model
Dec 10, 2024Are generative pre-trained transformer (GPT) models only trained to predict the next token, or do they implicitly learn a world model from which a sequence is generated one token at a time? We examine this question by deriving a causal interpretation of the attention mechanism in GPT, and suggesting a causal world model that arises from this interpretation. Furthermore, we propose that GPT-models, at inference time, can be utilized for zero-shot causal structure learning for in-distribution sequences. Empirical evaluation is conducted in a controlled synthetic environment using the setup and rules of the Othello board game. A GPT, pre-trained on real-world games played with the intention of winning, is tested on synthetic data that only adheres to the game rules. We find that the GPT model tends to generate next moves that adhere to the game rules for sequences for which the attention mechanism encodes a causal structure with high confidence. In general, in cases for which the GPT model generates moves that do not adhere to the game rules, it also fails to capture any causal structure.
Steering Large Language Models to Evaluate and Amplify Creativity
Dec 08, 2024Although capable of generating creative text, Large Language Models (LLMs) are poor judges of what constitutes "creativity". In this work, we show that we can leverage this knowledge of how to write creatively in order to better judge what is creative. We take a mechanistic approach that extracts differences in the internal states of an LLM when prompted to respond "boringly" or "creatively" to provide a robust measure of creativity that corresponds strongly with human judgment. We also show these internal state differences can be applied to enhance the creativity of generated text at inference time.
Training-Free Mitigation of Language Reasoning Degradation After Multimodal Instruction Tuning
Dec 04, 2024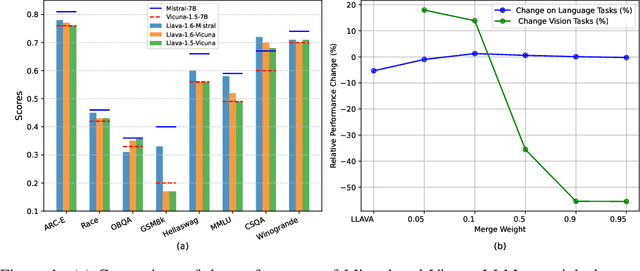

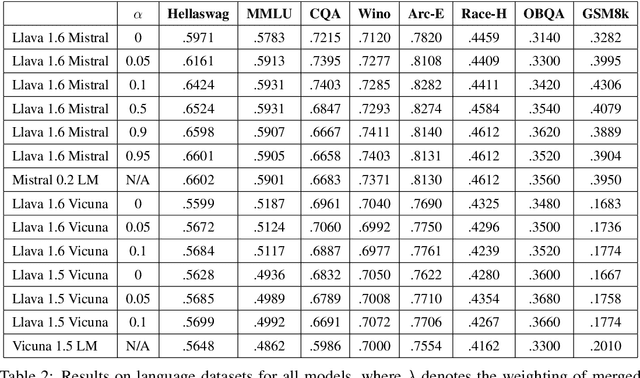
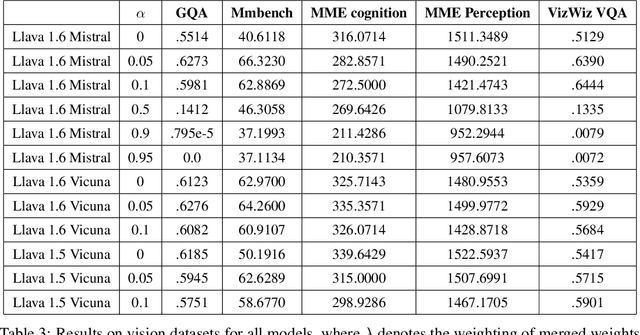
Multimodal models typically combine a powerful large language model (LLM) with a vision encoder and are then trained on multimodal data via instruction tuning. While this process adapts LLMs to multimodal settings, it remains unclear whether this adaptation compromises their original language reasoning capabilities. In this work, we explore the effects of multimodal instruction tuning on language reasoning performance. We focus on LLaVA, a leading multimodal framework that integrates LLMs such as Vicuna or Mistral with the CLIP vision encoder. We compare the performance of the original LLMs with their multimodal-adapted counterparts across eight language reasoning tasks. Our experiments yield several key insights. First, the impact of multimodal learning varies between Vicuna and Mistral: we observe a degradation in language reasoning for Mistral but improvements for Vicuna across most tasks. Second, while multimodal instruction learning consistently degrades performance on mathematical reasoning tasks (e.g., GSM8K), it enhances performance on commonsense reasoning tasks (e.g., CommonsenseQA). Finally, we demonstrate that a training-free model merging technique can effectively mitigate the language reasoning degradation observed in multimodal-adapted Mistral and even improve performance on visual tasks.
FastRM: An efficient and automatic explainability framework for multimodal generative models
Dec 02, 2024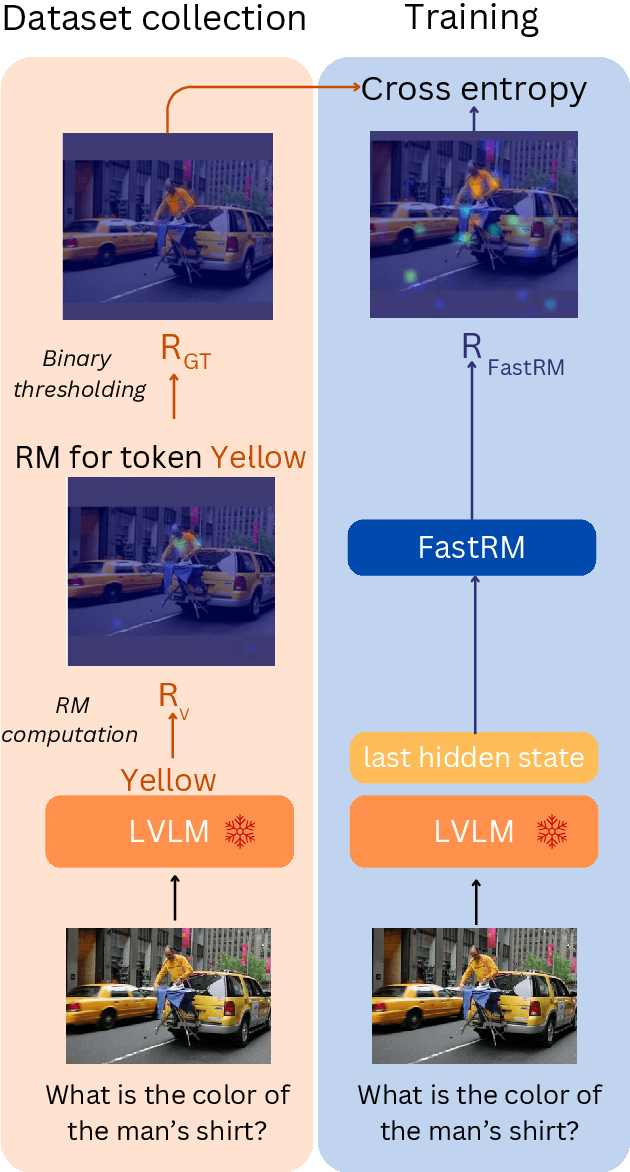
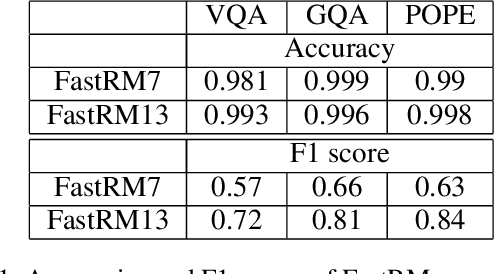
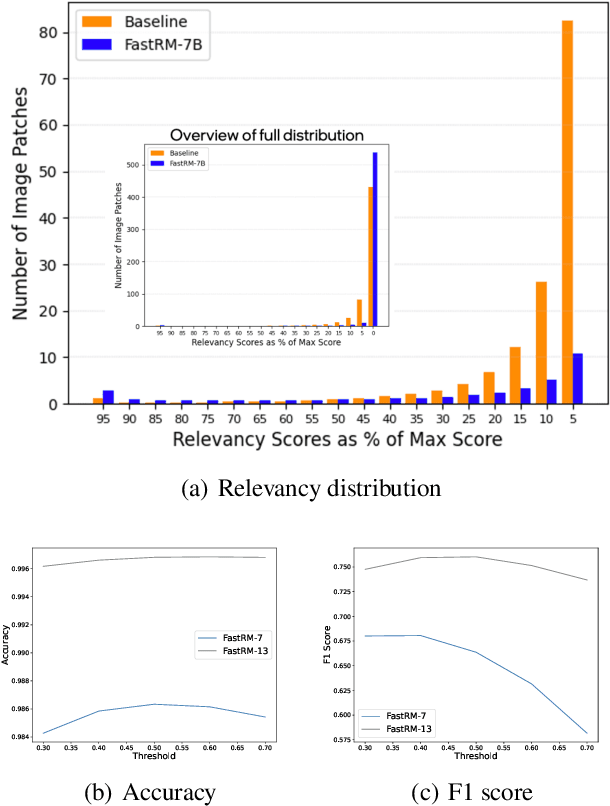
While Large Vision Language Models (LVLMs) have become masterly capable in reasoning over human prompts and visual inputs, they are still prone to producing responses that contain misinformation. Identifying incorrect responses that are not grounded in evidence has become a crucial task in building trustworthy AI. Explainability methods such as gradient-based relevancy maps on LVLM outputs can provide an insight on the decision process of models, however these methods are often computationally expensive and not suited for on-the-fly validation of outputs. In this work, we propose FastRM, an effective way for predicting the explainable Relevancy Maps of LVLM models. Experimental results show that employing FastRM leads to a 99.8% reduction in compute time for relevancy map generation and an 44.4% reduction in memory footprint for the evaluated LVLM, making explainable AI more efficient and practical, thereby facilitating its deployment in real-world applications.