 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying Interpretability in CLIP Models with Concept Consistency
Paper and Code
Mar 14, 2025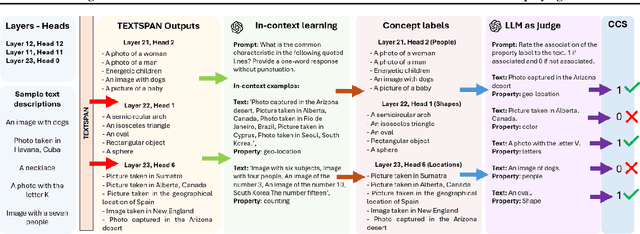
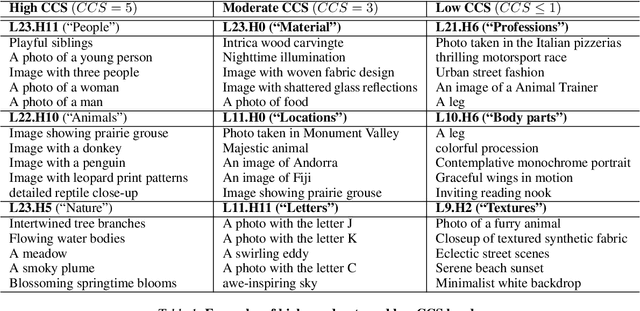
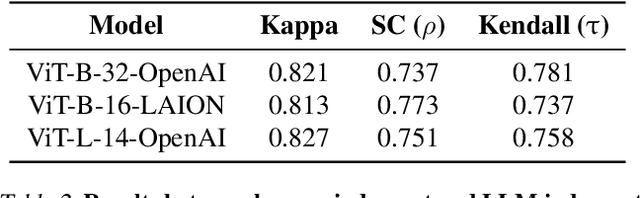
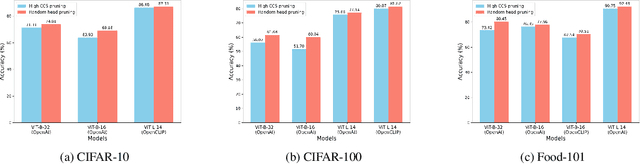
CLIP is one of the most popular foundational models and is heavily used for many vision-language tasks. However, little is known about the inner workings of CLIP. While recent work has proposed decomposition-based interpretability methods for identifying textual descriptions of attention heads in CLIP, the implications of conceptual consistency in these text labels on interpretability and model performance has not been explored. To bridge this gap, we study the conceptual consistency of text descriptions for attention heads in CLIP-like models. We conduct extensive experiments on six different models from OpenAI and OpenCLIP which vary by size, type of pre-training data and patch size. We propose Concept Consistency Score (CCS), a novel interpretability metric that measures how consistently individual attention heads in CLIP models align with specific concepts. To assign concept labels to heads, we use in-context learning with ChatGPT, guided by a few manually-curated examples, and validate these labels using an LLM-as-a-judge approach. Our soft-pruning experiments reveal that high CCS heads are critical for preserving model performance, as pruning them leads to a significantly larger performance drop than pruning random or low CCS heads. Notably, we find that high CCS heads capture essential concepts and play a key role in out-of-domain detection, concept-specific reasoning, and video-language understanding. These results position CCS as a powerful interpretability metric for analyzing CLIP-like models.