 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Reasoning Failures via Synthetic Data Generation
Apr 20, 2025Training models on synthetic data has emerged as an increasingly important strategy for improving the performance of generative AI. This approach is particularly helpful for large multimodal models (LMMs) due to the relative scarcity of high-quality paired image-text data compared to language-only data. While a variety of methods have been proposed for generating large multimodal datasets, they do not tailor the synthetic data to address specific deficiencies in the reasoning abilities of LMMs which will be trained with the generated dataset. In contrast, humans often learn in a more efficient manner by seeking out examples related to the types of reasoning where they have failed previously. Inspired by this observation, we propose a new approach for synthetic data generation which is grounded in the analysis of an existing LMM's reasoning failures. Our methodology leverages frontier models to automatically analyze errors produced by a weaker LMM and propose new examples which can be used to correct the reasoning failure via additional training, which are then further filtered to ensure high quality. We generate a large multimodal instruction tuning dataset containing over 553k examples using our approach and conduct extensive experiments demonstrating its utility for improving the performance of LMMs on multiple downstream tasks. Our results show that models trained on our synthetic data can even exceed the performance of LMMs trained on an equivalent amount of additional real data, demonstrating the high value of generating synthetic data targeted to specific reasoning failure modes in LMMs. We will make our dataset and code publicly available.
Quantifying Interpretability in CLIP Models with Concept Consistency
Mar 14, 2025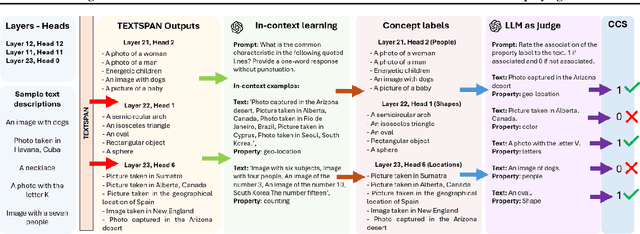
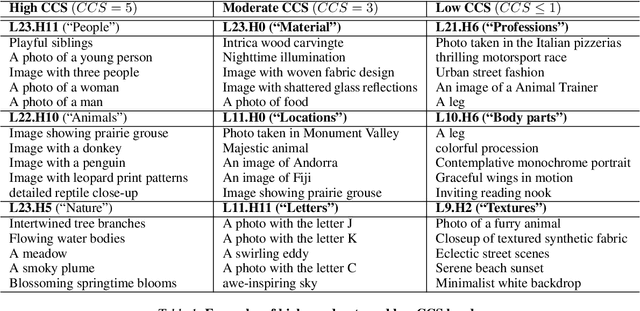
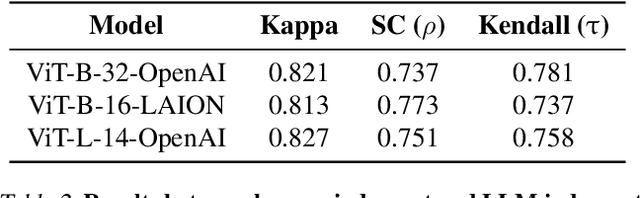
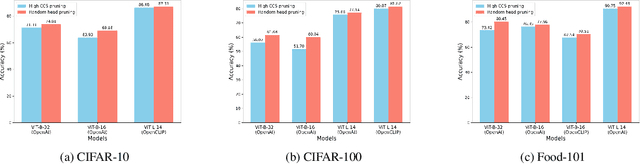
CLIP is one of the most popular foundational models and is heavily used for many vision-language tasks. However, little is known about the inner workings of CLIP. While recent work has proposed decomposition-based interpretability methods for identifying textual descriptions of attention heads in CLIP, the implications of conceptual consistency in these text labels on interpretability and model performance has not been explored. To bridge this gap, we study the conceptual consistency of text descriptions for attention heads in CLIP-like models. We conduct extensive experiments on six different models from OpenAI and OpenCLIP which vary by size, type of pre-training data and patch size. We propose Concept Consistency Score (CCS), a novel interpretability metric that measures how consistently individual attention heads in CLIP models align with specific concepts. To assign concept labels to heads, we use in-context learning with ChatGPT, guided by a few manually-curated examples, and validate these labels using an LLM-as-a-judge approach. Our soft-pruning experiments reveal that high CCS heads are critical for preserving model performance, as pruning them leads to a significantly larger performance drop than pruning random or low CCS heads. Notably, we find that high CCS heads capture essential concepts and play a key role in out-of-domain detection, concept-specific reasoning, and video-language understanding. These results position CCS as a powerful interpretability metric for analyzing CLIP-like models.
Is Your Paper Being Reviewed by an LLM? Investigating AI Text Detectability in Peer Review
Oct 03, 2024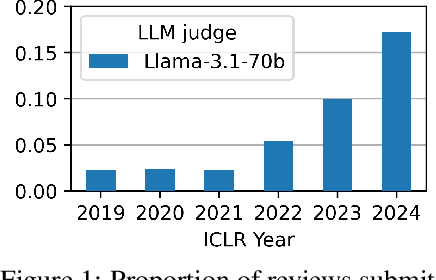
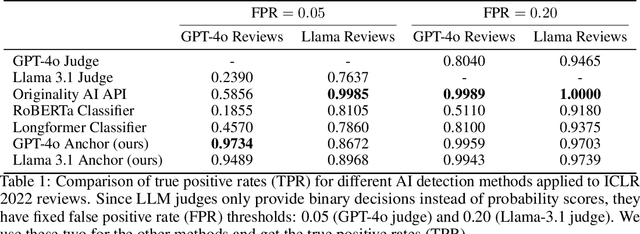
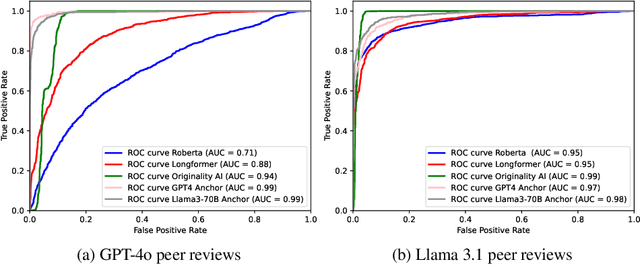
Peer review is a critical process for ensuring the integrity of published scientific research. Confidence in this process is predicated on the assumption that experts in the relevant domain give careful consideration to the merits of manuscripts which are submitted for publication. With the recent rapid advancements in the linguistic capabilities of large language models (LLMs), a new potential risk to the peer review process is that negligent reviewers will rely on LLMs to perform the often time consuming process of reviewing a paper. In this study, we investigate the ability of existing AI text detection algorithms to distinguish between peer reviews written by humans and different state-of-the-art LLMs. Our analysis shows that existing approaches fail to identify many GPT-4o written reviews without also producing a high number of false positive classifications. To address this deficiency, we propose a new detection approach which surpasses existing methods in the identification of GPT-4o written peer reviews at low levels of false positive classifications. Our work reveals the difficulty of accurately identifying AI-generated text at the individual review level, highlighting the urgent need for new tools and methods to detect this type of unethical application of generative AI.
Quantifying and Enabling the Interpretability of CLIP-like Models
Sep 10, 2024CLIP is one of the most popular foundational models and is heavily used for many vision-language tasks. However, little is known about the inner workings of CLIP. To bridge this gap we propose a study to quantify the interpretability in CLIP like models. We conduct this study on six different CLIP models from OpenAI and OpenCLIP which vary by size, type of pre-training data and patch size. Our approach begins with using the TEXTSPAN algorithm and in-context learning to break down individual attention heads into specific properties. We then evaluate how easily these heads can be interpreted using new metrics which measure property consistency within heads and property disentanglement across heads. Our findings reveal that larger CLIP models are generally more interpretable than their smaller counterparts. To further assist users in understanding the inner workings of CLIP models, we introduce CLIP-InterpreT, a tool designed for interpretability analysis. CLIP-InterpreT offers five types of analyses: property-based nearest neighbor search, per-head topic segmentation, contrastive segmentation, per-head nearest neighbors of an image, and per-head nearest neighbors of text.
Probing and Mitigating Intersectional Social Biases in Vision-Language Models with Counterfactual Examples
Nov 30, 2023While vision-language models (VLMs) have achieved remarkable performance improvements recently, there is growing evidence that these models also posses harmful biases with respect to social attributes such as gender and race. Prior studies have primarily focused on probing such bias attributes individually while ignoring biases associated with intersections between social attributes. This could be due to the difficulty of collecting an exhaustive set of image-text pairs for various combinations of social attributes. To address this challenge, we employ text-to-image diffusion models to produce counterfactual examples for probing intserctional social biases at scale. Our approach utilizes Stable Diffusion with cross attention control to produce sets of counterfactual image-text pairs that are highly similar in their depiction of a subject (e.g., a given occupation) while differing only in their depiction of intersectional social attributes (e.g., race & gender). Through our over-generate-then-filter methodology, we produce SocialCounterfactuals, a high-quality dataset containing over 171k image-text pairs for probing intersectional biases related to gender, race, and physical characteristics. We conduct extensive experiments to demonstrate the usefulness of our generated dataset for probing and mitigating intersectional social biases in state-of-the-art VLMs.
Analyzing Zero-Shot Abilities of Vision-Language Models on Video Understanding Tasks
Oct 07, 2023



Foundational multimodal models pre-trained on large scale image-text pairs or video-text pairs or both have shown strong generalization abilities on downstream tasks. However unlike image-text models, pretraining video-text models is always not feasible due to the difficulty in collecting large-scale clean and aligned data, and exponential computational costs involved in the pretraining phase. Therefore, the pertinent question to ask is: Can image-text models be adapted to video tasks and is there any benefit to using these models over pretraining directly on videos? In this work, we focus on this question by proposing a detailed study on the generalization abilities of image-text models when evaluated on video understanding tasks in a zero-shot setting. We investigate 9 foundational image-text models on a diverse set of video tasks that include video action recognition (video AR), video retrieval (video RT), video question answering (video QA), video multiple choice (video MC) and video captioning (video CP). Our experiments show that image-text models exhibit impressive performance on video AR, video RT and video MC. Furthermore, they perform moderately on video captioning and poorly on video QA. These findings shed a light on the benefits of adapting foundational image-text models to an array of video tasks while avoiding the costly pretraining step.
Probing Intersectional Biases in Vision-Language Models with Counterfactual Examples
Oct 04, 2023

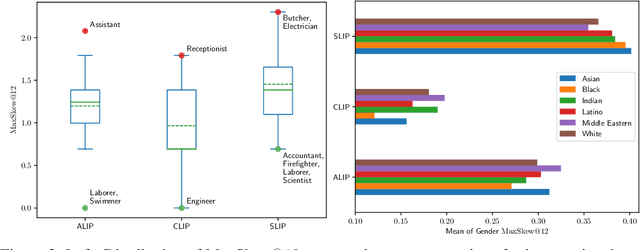

While vision-language models (VLMs) have achieved remarkable performance improvements recently, there is growing evidence that these models also posses harmful biases with respect to social attributes such as gender and race. Prior studies have primarily focused on probing such bias attributes individually while ignoring biases associated with intersections between social attributes. This could be due to the difficulty of collecting an exhaustive set of image-text pairs for various combinations of social attributes from existing datasets. To address this challenge, we employ text-to-image diffusion models to produce counterfactual examples for probing intserctional social biases at scale. Our approach utilizes Stable Diffusion with cross attention control to produce sets of counterfactual image-text pairs that are highly similar in their depiction of a subject (e.g., a given occupation) while differing only in their depiction of intersectional social attributes (e.g., race & gender). We conduct extensive experiments using our generated dataset which reveal the intersectional social biases present in state-of-the-art VLMs.
Affective Visual Dialog: A Large-Scale Benchmark for Emotional Reasoning Based on Visually Grounded Conversations
Sep 12, 2023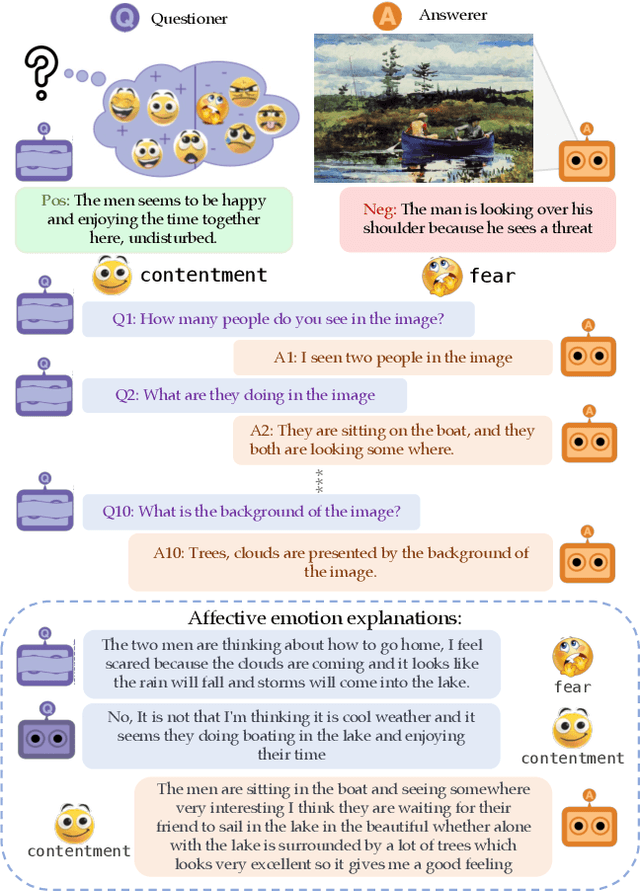
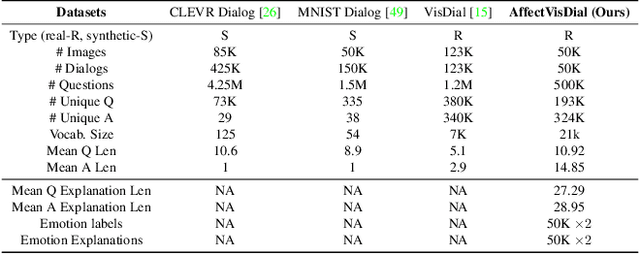

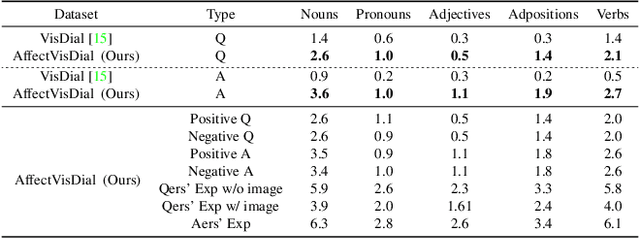
We introduce Affective Visual Dialog, an emotion explanation and reasoning task as a testbed for research on understanding the formation of emotions in visually grounded conversations. The task involves three skills: (1) Dialog-based Question Answering (2) Dialog-based Emotion Prediction and (3) Affective emotion explanation generation based on the dialog. Our key contribution is the collection of a large-scale dataset, dubbed AffectVisDial, consisting of 50K 10-turn visually grounded dialogs as well as concluding emotion attributions and dialog-informed textual emotion explanations, resulting in a total of 27,180 working hours. We explain our design decisions in collecting the dataset and introduce the questioner and answerer tasks that are associated with the participants in the conversation. We train and demonstrate solid Affective Visual Dialog baselines adapted from state-of-the-art models. Remarkably, the responses generated by our models show promising emotional reasoning abilities in response to visually grounded conversations. Our project page is available at https://affective-visual-dialog.github.io.
ICSVR: Investigating Compositional and Semantic Understanding in Video Retrieval Models
Jun 28, 2023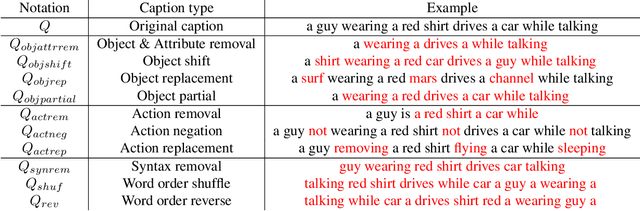
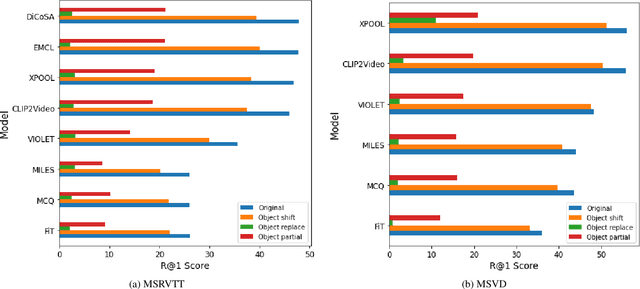
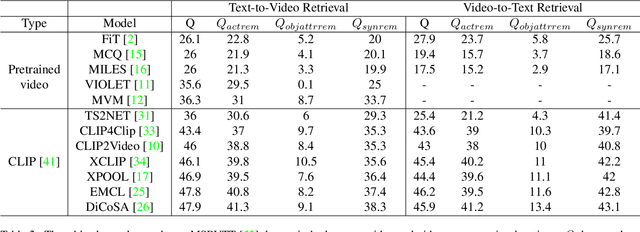
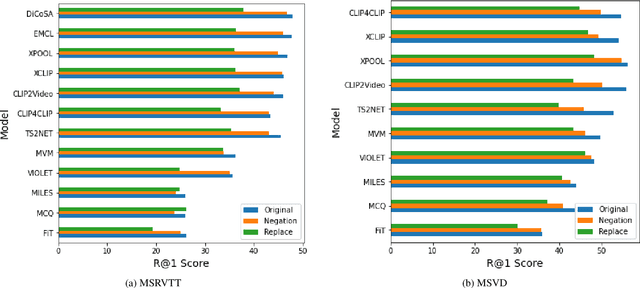
Video retrieval (VR) involves retrieving the ground truth video from the video database given a text caption or vice-versa. The two important components of compositionality: objects \& attributes and actions are joined using correct semantics to form a proper text query. These components (objects \& attributes, actions and semantics) each play an important role to help distinguish among videos and retrieve the correct ground truth video. However, it is unclear what is the effect of these components on the video retrieval performance. We therefore, conduct a systematic study to evaluate the compositional and semantic understanding of video retrieval models on standard benchmarks such as MSRVTT, MSVD and DIDEMO. The study is performed on two categories of video retrieval models: (i) which are pre-trained on video-text pairs and fine-tuned on downstream video retrieval datasets (Eg. Frozen-in-Time, Violet, MCQ etc.) (ii) which adapt pre-trained image-text representations like CLIP for video retrieval (Eg. CLIP4Clip, XCLIP, CLIP2Video etc.). Our experiments reveal that actions and semantics play a minor role compared to objects \& attributes in video understanding. Moreover, video retrieval models that use pre-trained image-text representations (CLIP) have better semantic and compositional understanding as compared to models pre-trained on video-text data.
A Unified Framework for Slot based Response Generation in a Multimodal Dialogue System
May 27, 2023



Natural Language Understanding (NLU) and Natural Language Generation (NLG) are the two critical components of every conversational system that handles the task of understanding the user by capturing the necessary information in the form of slots and generating an appropriate response in accordance with the extracted information. Recently, dialogue systems integrated with complementary information such as images, audio, or video have gained immense popularity. In this work, we propose an end-to-end framework with the capability to extract necessary slot values from the utterance and generate a coherent response, thereby assisting the user to achieve their desired goals in a multimodal dialogue system having both textual and visual information. The task of extracting the necessary information is dependent not only on the text but also on the visual cues present in the dialogue. Similarly, for the generation, the previous dialog context comprising multimodal information is significant for providing coherent and informative responses. We employ a multimodal hierarchical encoder using pre-trained DialoGPT and also exploit the knowledge base (Kb) to provide a stronger context for both the tasks. Finally, we design a slot attention mechanism to focus on the necessary information in a given utterance. Lastly, a decoder generates the corresponding response for the given dialogue context and the extracted slot values. Experimental results on the Multimodal Dialogue Dataset (MMD) show that the proposed framework outperforms the baselines approaches in both the tasks. The code is available at https://github.com/avinashsai/slot-gpt.