 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoundation Metrics: Quantifying Effectiveness of Healthcare Conversations powered by Generative AI
Sep 21, 2023Generative Artificial Intelligence is set to revolutionize healthcare delivery by transforming traditional patient care into a more personalized, efficient, and proactive process. Chatbots, serving as interactive conversational models, will probably drive this patient-centered transformation in healthcare. Through the provision of various services, including diagnosis, personalized lifestyle recommendations, and mental health support, the objective is to substantially augment patient health outcomes, all the while mitigating the workload burden on healthcare providers. The life-critical nature of healthcare applications necessitates establishing a unified and comprehensive set of evaluation metrics for conversational models. Existing evaluation metrics proposed for various generic large language models (LLMs) demonstrate a lack of comprehension regarding medical and health concepts and their significance in promoting patients' well-being. Moreover, these metrics neglect pivotal user-centered aspects, including trust-building, ethics, personalization, empathy, user comprehension, and emotional support. The purpose of this paper is to explore state-of-the-art LLM-based evaluation metrics that are specifically applicable to the assessment of interactive conversational models in healthcare. Subsequently, we present an comprehensive set of evaluation metrics designed to thoroughly assess the performance of healthcare chatbots from an end-user perspective. These metrics encompass an evaluation of language processing abilities, impact on real-world clinical tasks, and effectiveness in user-interactive conversations. Finally, we engage in a discussion concerning the challenges associated with defining and implementing these metrics, with particular emphasis on confounding factors such as the target audience, evaluation methods, and prompt techniques involved in the evaluation process.
Affective Visual Dialog: A Large-Scale Benchmark for Emotional Reasoning Based on Visually Grounded Conversations
Sep 12, 2023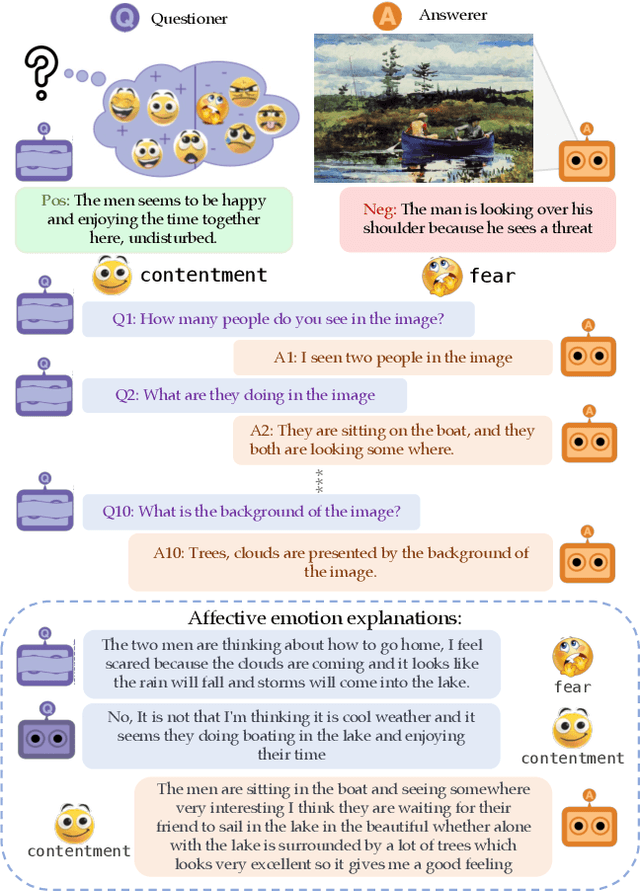
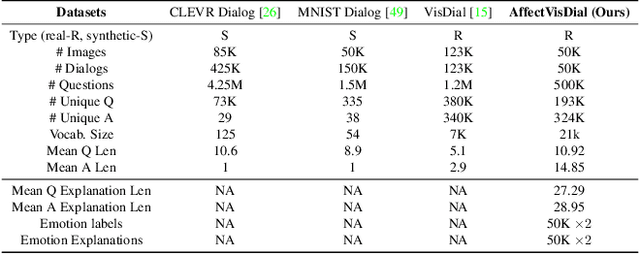

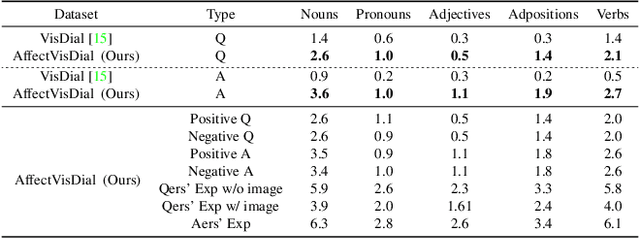
We introduce Affective Visual Dialog, an emotion explanation and reasoning task as a testbed for research on understanding the formation of emotions in visually grounded conversations. The task involves three skills: (1) Dialog-based Question Answering (2) Dialog-based Emotion Prediction and (3) Affective emotion explanation generation based on the dialog. Our key contribution is the collection of a large-scale dataset, dubbed AffectVisDial, consisting of 50K 10-turn visually grounded dialogs as well as concluding emotion attributions and dialog-informed textual emotion explanations, resulting in a total of 27,180 working hours. We explain our design decisions in collecting the dataset and introduce the questioner and answerer tasks that are associated with the participants in the conversation. We train and demonstrate solid Affective Visual Dialog baselines adapted from state-of-the-art models. Remarkably, the responses generated by our models show promising emotional reasoning abilities in response to visually grounded conversations. Our project page is available at https://affective-visual-dialog.github.io.
Non-inferiority of Deep Learning Model to Segment Acute Stroke on Non-contrast CT Compared to Neuroradiologists
Nov 24, 2022Purpose: To develop a deep learning model to segment the acute ischemic infarct on non-contrast Computed Tomography (NCCT). Materials and Methods In this retrospective study, 227 Head NCCT examinations from 200 patients enrolled in the multicenter DEFUSE 3 trial were included. Three experienced neuroradiologists (experts A, B and C) independently segmented the acute infarct on each study. The dataset was randomly split into 5 folds with training and validation cases. A 3D deep Convolutional Neural Network (CNN) architecture was optimized for the data set properties and task needs. The input to the model was the NCCT and the output was a segmentation mask. The model was trained and optimized on expert A. The outcome was assessed by a set of volume, overlap and distance metrics. The predicted segmentations of the best model and expert A were compared to experts B and C. Then we used a paired Wilcoxon signed-rank test in a one-sided test procedure for all metrics to test for non-inferiority in terms of bias and precision. Results: The best performing model reached a Surface Dice at Tolerance (SDT)5mm of 0.68 \pm 0.04. The predictions were non-inferior when compared to independent experts in terms of bias and precision (paired one-sided test procedure for differences in medians and bootstrapped standard deviations with non-inferior boundaries of -0.05, 2ml, and 2mm, p < 0.05, n=200). Conclusion: For the segmentation of acute ischemic stroke on NCCT, our 3D CNN trained with the annotations of one neuroradiologist is non-inferior when compared to two independent neuroradiologists.
Evaluation of Medical Image Segmentation Models for Uncertain, Small or Empty Reference Annotations
Sep 30, 2022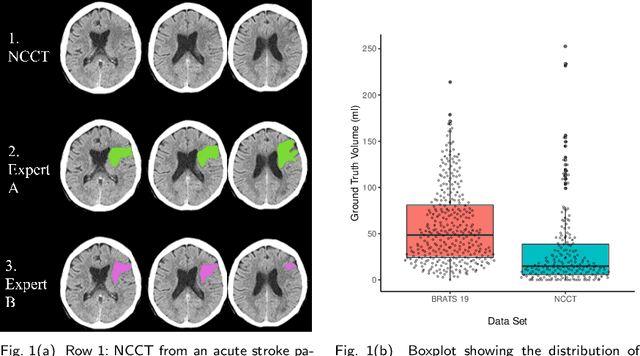

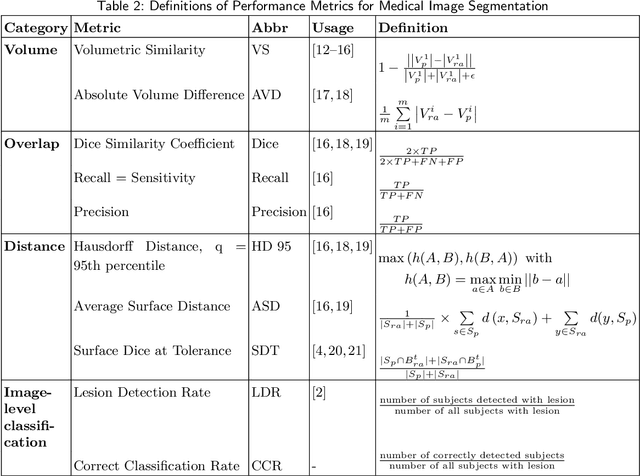
Performance metrics for medical image segmentation models are used to measure agreement between the reference annotation and the prediction. A common set of metrics is used in the development of such models to make results more comparable. However, there is a mismatch between the distributions in public data sets and cases encountered in clinical practice. Many common metrics fail to measure the impact of this mismatch, especially for clinical data sets containing uncertain, small or empty reference annotation. Thus, models may not be validated for clinically meaningful agreement by such metrics. Dimensions of evaluating clinical value include independence from reference annotation volume size, consideration of uncertainty of reference annotations, reward of volumetric and/or location agreement and reward of correct classification of empty reference annotations. Unlike common public data sets, our in-house data set is more representative. It contains uncertain, small or empty reference annotations. We examine publicly available metrics on the predictions of a deep learning framework in order to identify for which settings common metrics provide clinical meaningful results. We compare to a public benchmark data set without uncertain, small or empty reference annotations. https://github.com/SophieOstmeier/UncertainSmallEmpty
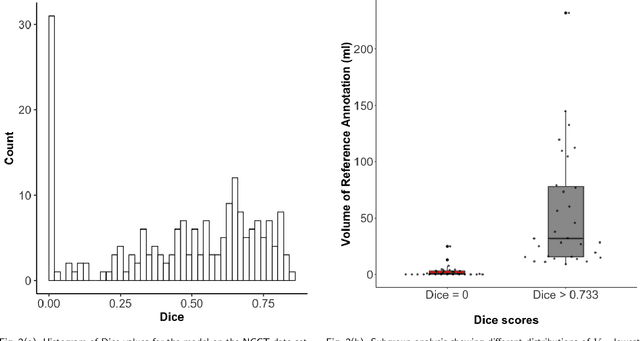
ALBench: A Framework for Evaluating Active Learning in Object Detection
Aug 10, 2022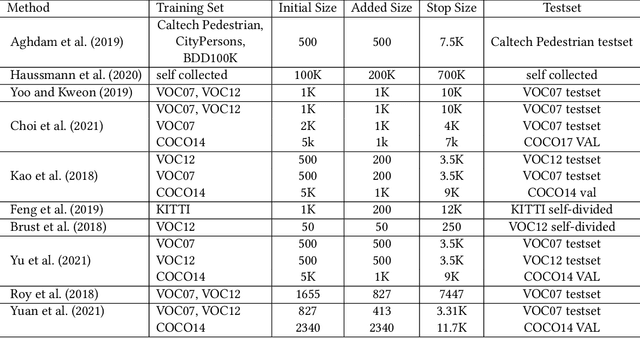
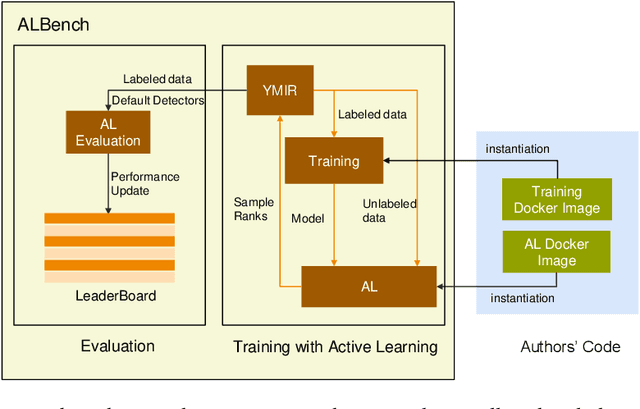
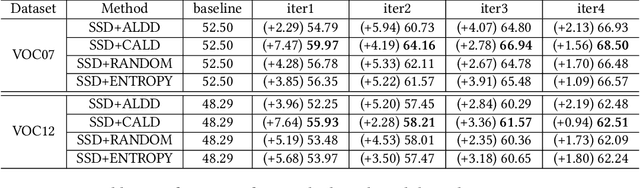
Active learning is an important technology for automated machine learning systems. In contrast to Neural Architecture Search (NAS) which aims at automating neural network architecture design, active learning aims at automating training data selection. It is especially critical for training a long-tailed task, in which positive samples are sparsely distributed. Active learning alleviates the expensive data annotation issue through incrementally training models powered with efficient data selection. Instead of annotating all unlabeled samples, it iteratively selects and annotates the most valuable samples. Active learning has been popular in image classification, but has not been fully explored in object detection. Most of current approaches on object detection are evaluated with different settings, making it difficult to fairly compare their performance. To facilitate the research in this field, this paper contributes an active learning benchmark framework named as ALBench for evaluating active learning in object detection. Developed on an automatic deep model training system, this ALBench framework is easy-to-use, compatible with different active learning algorithms, and ensures the same training and testing protocols. We hope this automated benchmark system help researchers to easily reproduce literature's performance and have objective comparisons with prior arts. The code will be release through Github.
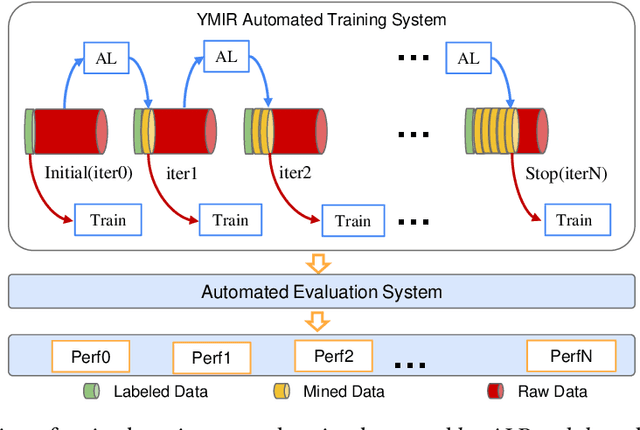
YMIR: A Rapid Data-centric Development Platform for Vision Applications
Nov 27, 2021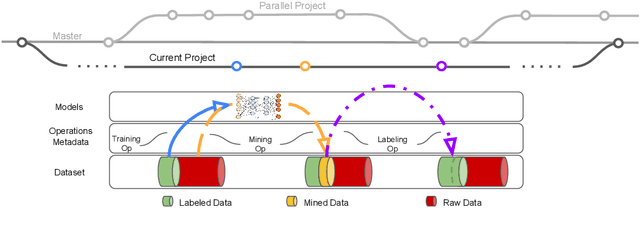
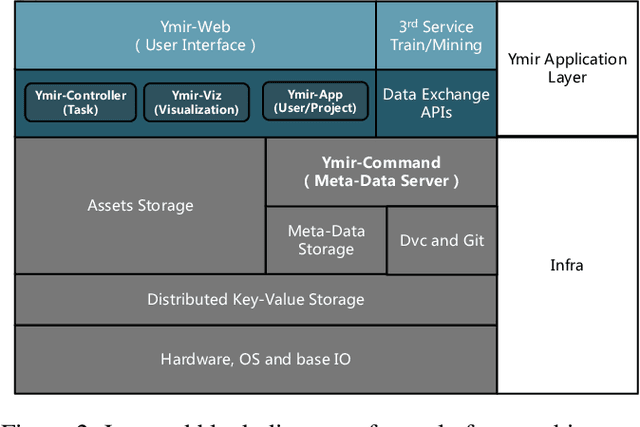
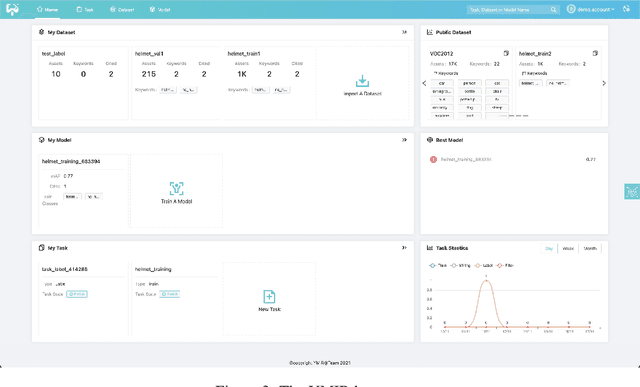
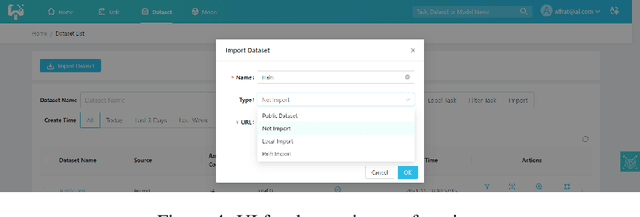
This paper introduces an open source platform to support the rapid development of computer vision applications at scale. The platform puts the efficient data development at the center of the machine learning development process, integrates active learning methods, data and model version control, and uses concepts such as projects to enable fast iterations of multiple task specific datasets in parallel. This platform abstracts the development process into core states and operations, and integrates third party tools via open APIs as implementations of the operations. This open design reduces the development cost and adoption cost for ML teams with existing tools. At the same time, the platform supports recording project development histories, through which successful projects can be shared to further boost model production efficiency on similar tasks. The platform is open source and is already used internally to meet the increasing demand for different real world computer vision applications.
Generative Modeling for Small-Data Object Detection
Oct 16, 2019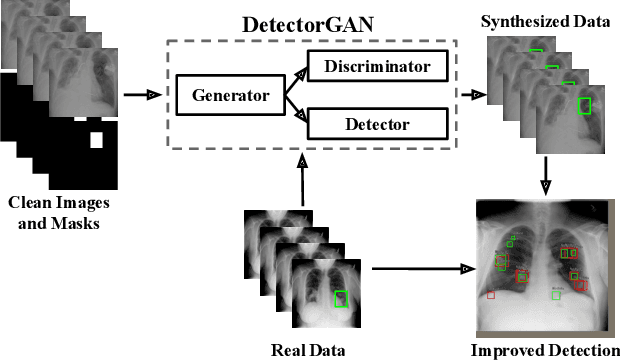

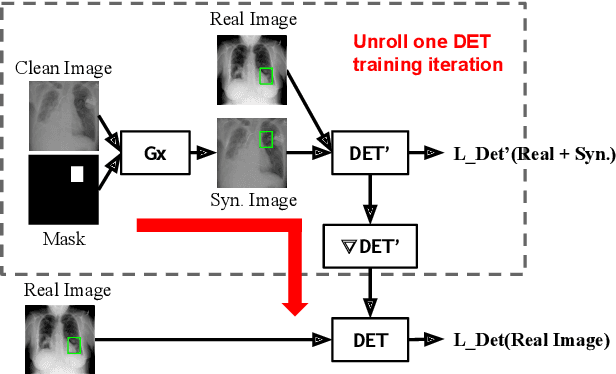

This paper explores object detection in the small data regime, where only a limited number of annotated bounding boxes are available due to data rarity and annotation expense. This is a common challenge today with machine learning being applied to many new tasks where obtaining training data is more challenging, e.g. in medical images with rare diseases that doctors sometimes only see once in their life-time. In this work we explore this problem from a generative modeling perspective by learning to generate new images with associated bounding boxes, and using these for training an object detector. We show that simply training previously proposed generative models does not yield satisfactory performance due to them optimizing for image realism rather than object detection accuracy. To this end we develop a new model with a novel unrolling mechanism that jointly optimizes the generative model and a detector such that the generated images improve the performance of the detector. We show this method outperforms the state of the art on two challenging datasets, disease detection and small data pedestrian detection, improving the average precision on NIH Chest X-ray by a relative 20% and localization accuracy by a relative 50%.
Feature Partitioning for Efficient Multi-Task Architectures
Aug 12, 2019
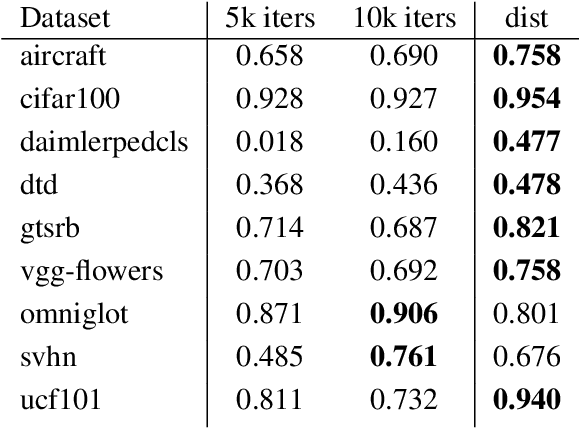
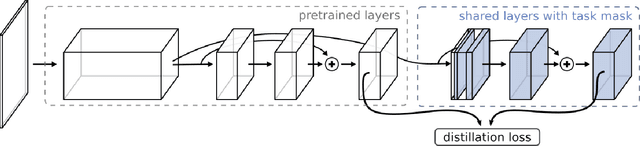

Multi-task learning holds the promise of less data, parameters, and time than training of separate models. We propose a method to automatically search over multi-task architectures while taking resource constraints into consideration. We propose a search space that compactly represents different parameter sharing strategies. This provides more effective coverage and sampling of the space of multi-task architectures. We also present a method for quick evaluation of different architectures by using feature distillation. Together these contributions allow us to quickly optimize for efficient multi-task models. We benchmark on Visual Decathlon, demonstrating that we can automatically search for and identify multi-task architectures that effectively make trade-offs between task resource requirements while achieving a high level of final performance.
Composing Text and Image for Image Retrieval - An Empirical Odyssey
Dec 18, 2018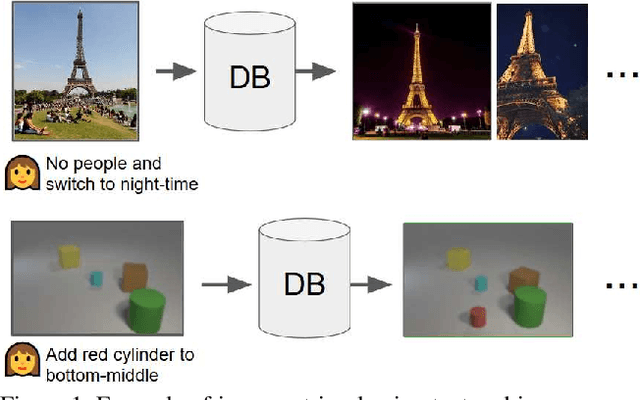
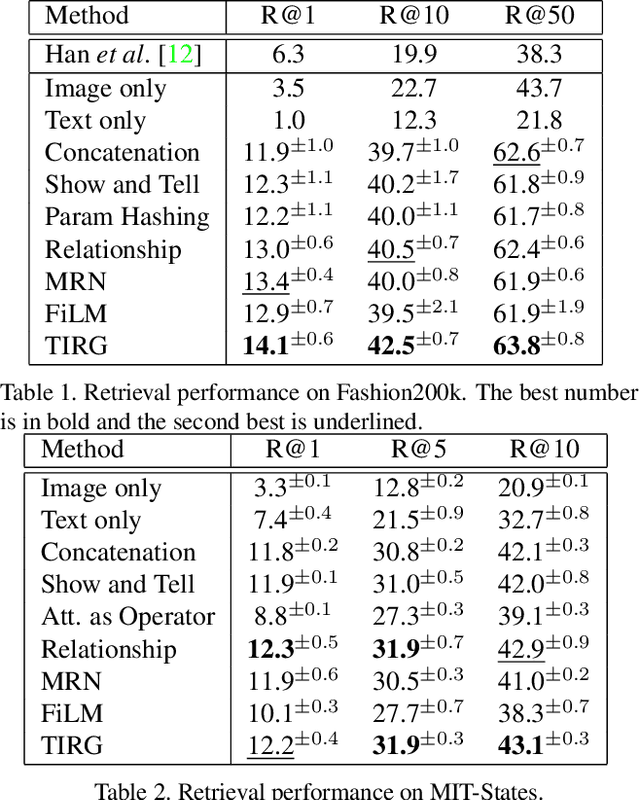
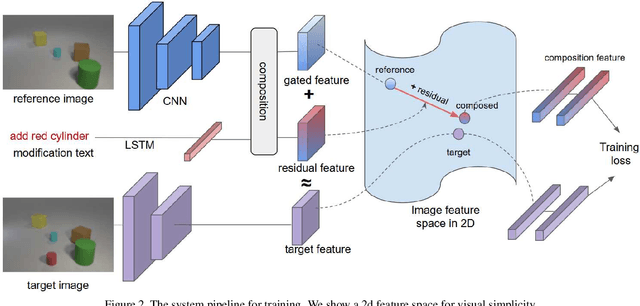

In this paper, we study the task of image retrieval, where the input query is specified in the form of an image plus some text that describes desired modifications to the input image. For example, we may present an image of the Eiffel tower, and ask the system to find images which are visually similar but are modified in small ways, such as being taken at nighttime instead of during the day. To tackle this task, we learn a similarity metric between a target image and a source image plus source text, an embedding and composing function such that target image feature is close to the source image plus text composition feature. We propose a new way to combine image and text using such function that is designed for the retrieval task. We show this outperforms existing approaches on 3 different datasets, namely Fashion-200k, MIT-States and a new synthetic dataset we create based on CLEVR. We also show that our approach can be used to classify input queries, in addition to image retrieval.
Vision-Based Gait Analysis for Senior Care
Dec 01, 2018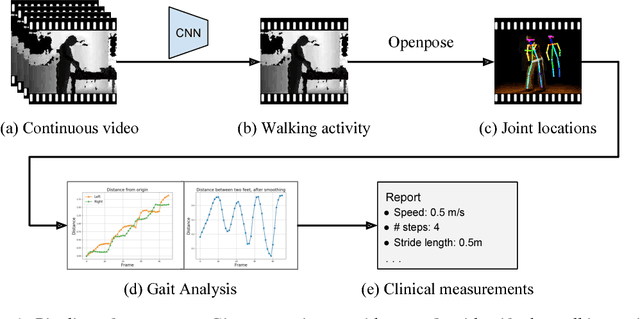

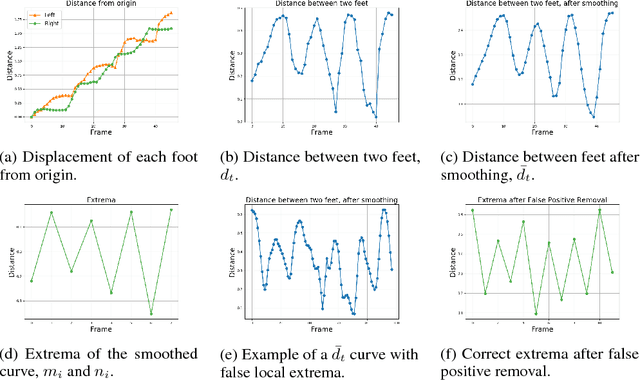
As the senior population rapidly increases, it is challenging yet crucial to provide effective long-term care for seniors who live at home or in senior care facilities. Smart senior homes, which have gained widespread interest in the healthcare community, have been proposed to improve the well-being of seniors living independently. In particular, non-intrusive, cost-effective sensors placed in these senior homes enable gait characterization, which can provide clinically relevant information including mobility level and early neurodegenerative disease risk. In this paper, we present a method to perform gait analysis from a single camera placed within the home. We show that we can accurately calculate various gait parameters, demonstrating the potential for our system to monitor the long-term gait of seniors and thus aid clinicians in understanding a patient's medical profile.