 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNo Culture Left Behind: ArtELingo-28, a Benchmark of WikiArt with Captions in 28 Languages
Nov 06, 2024Research in vision and language has made considerable progress thanks to benchmarks such as COCO. COCO captions focused on unambiguous facts in English; ArtEmis introduced subjective emotions and ArtELingo introduced some multilinguality (Chinese and Arabic). However we believe there should be more multilinguality. Hence, we present ArtELingo-28, a vision-language benchmark that spans $\textbf{28}$ languages and encompasses approximately $\textbf{200,000}$ annotations ($\textbf{140}$ annotations per image). Traditionally, vision research focused on unambiguous class labels, whereas ArtELingo-28 emphasizes diversity of opinions over languages and cultures. The challenge is to build machine learning systems that assign emotional captions to images. Baseline results will be presented for three novel conditions: Zero-Shot, Few-Shot and One-vs-All Zero-Shot. We find that cross-lingual transfer is more successful for culturally-related languages. Data and code are provided at www.artelingo.org.
Affective Visual Dialog: A Large-Scale Benchmark for Emotional Reasoning Based on Visually Grounded Conversations
Sep 12, 2023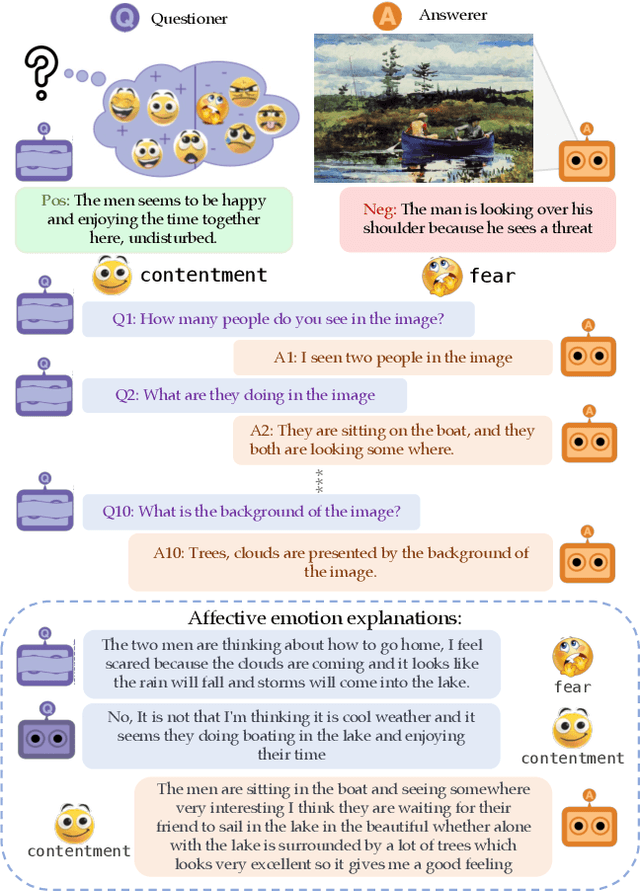
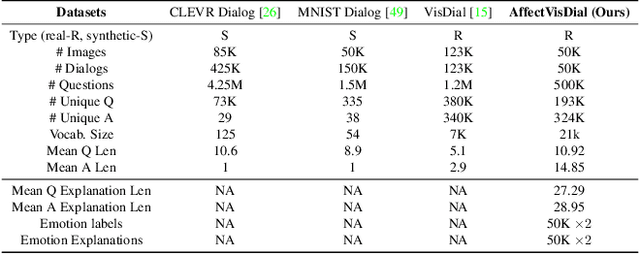

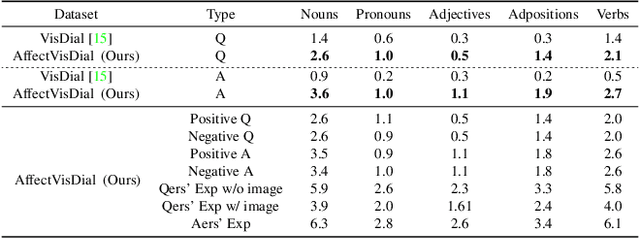
We introduce Affective Visual Dialog, an emotion explanation and reasoning task as a testbed for research on understanding the formation of emotions in visually grounded conversations. The task involves three skills: (1) Dialog-based Question Answering (2) Dialog-based Emotion Prediction and (3) Affective emotion explanation generation based on the dialog. Our key contribution is the collection of a large-scale dataset, dubbed AffectVisDial, consisting of 50K 10-turn visually grounded dialogs as well as concluding emotion attributions and dialog-informed textual emotion explanations, resulting in a total of 27,180 working hours. We explain our design decisions in collecting the dataset and introduce the questioner and answerer tasks that are associated with the participants in the conversation. We train and demonstrate solid Affective Visual Dialog baselines adapted from state-of-the-art models. Remarkably, the responses generated by our models show promising emotional reasoning abilities in response to visually grounded conversations. Our project page is available at https://affective-visual-dialog.github.io.
Video ChatCaptioner: Towards Enriched Spatiotemporal Descriptions
Apr 13, 2023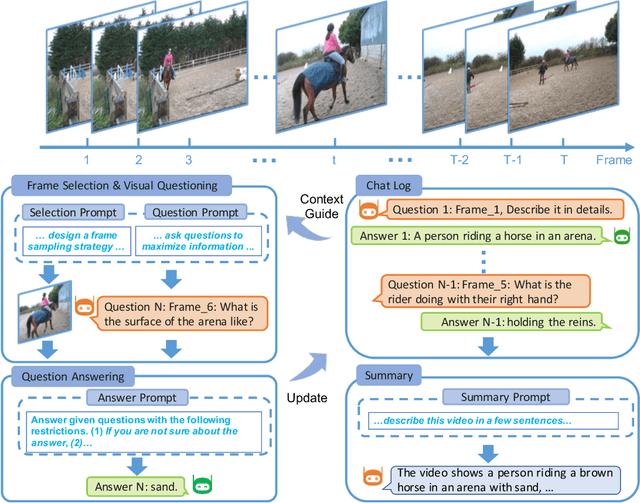



Video captioning aims to convey dynamic scenes from videos using natural language, facilitating the understanding of spatiotemporal information within our environment. Although there have been recent advances, generating detailed and enriched video descriptions continues to be a substantial challenge. In this work, we introduce Video ChatCaptioner, an innovative approach for creating more comprehensive spatiotemporal video descriptions. Our method employs a ChatGPT model as a controller, specifically designed to select frames for posing video content-driven questions. Subsequently, a robust algorithm is utilized to answer these visual queries. This question-answer framework effectively uncovers intricate video details and shows promise as a method for enhancing video content. Following multiple conversational rounds, ChatGPT can summarize enriched video content based on previous conversations. We qualitatively demonstrate that our Video ChatCaptioner can generate captions containing more visual details about the videos. The code is publicly available at https://github.com/Vision-CAIR/ChatCaptioner
ChatGPT Asks, BLIP-2 Answers: Automatic Questioning Towards Enriched Visual Descriptions
Mar 12, 2023



Asking insightful questions is crucial for acquiring knowledge and expanding our understanding of the world. However, the importance of questioning has been largely overlooked in AI research, where models have been primarily developed to answer questions. With the recent advancements of large language models (LLMs) like ChatGPT, we discover their capability to ask high-quality questions when provided with a suitable prompt. This discovery presents a new opportunity to develop an automatic questioning system. In this paper, we introduce ChatCaptioner, a novel automatic-questioning method deployed in image captioning. Here, ChatGPT is prompted to ask a series of informative questions about images to BLIP-2, a strong vision question-answering model. By keeping acquiring new visual information from BLIP-2's answers, ChatCaptioner is able to generate more enriched image descriptions. We conduct human-subject evaluations on common image caption datasets such as COCO, Conceptual Caption, and WikiArt, and compare ChatCaptioner with BLIP-2 as well as ground truth. Our results demonstrate that ChatCaptioner's captions are significantly more informative, receiving three times as many votes from human evaluators for providing the most image information. Besides, ChatCaptioner identifies 53% more objects within the image than BLIP-2 alone measured by WordNet synset matching. Code is available at https://github.com/Vision-CAIR/ChatCaptioner
It is Okay to Not Be Okay: Overcoming Emotional Bias in Affective Image Captioning by Contrastive Data Collection
Apr 15, 2022


Datasets that capture the connection between vision, language, and affection are limited, causing a lack of understanding of the emotional aspect of human intelligence. As a step in this direction, the ArtEmis dataset was recently introduced as a large-scale dataset of emotional reactions to images along with language explanations of these chosen emotions. We observed a significant emotional bias towards instance-rich emotions, making trained neural speakers less accurate in describing under-represented emotions. We show that collecting new data, in the same way, is not effective in mitigating this emotional bias. To remedy this problem, we propose a contrastive data collection approach to balance ArtEmis with a new complementary dataset such that a pair of similar images have contrasting emotions (one positive and one negative). We collected 260,533 instances using the proposed method, we combine them with ArtEmis, creating a second iteration of the dataset. The new combined dataset, dubbed ArtEmis v2.0, has a balanced distribution of emotions with explanations revealing more fine details in the associated painting. Our experiments show that neural speakers trained on the new dataset improve CIDEr and METEOR evaluation metrics by 20% and 7%, respectively, compared to the biased dataset. Finally, we also show that the performance per emotion of neural speakers is improved across all the emotion categories, significantly on under-represented emotions. The collected dataset and code are available at https://artemisdataset-v2.org.
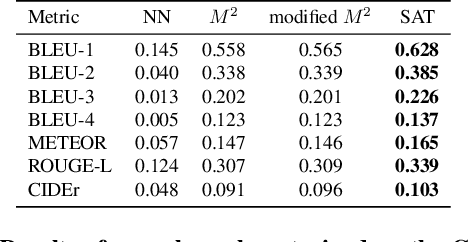
ArtEmis: Affective Language for Visual Art
Jan 19, 2021


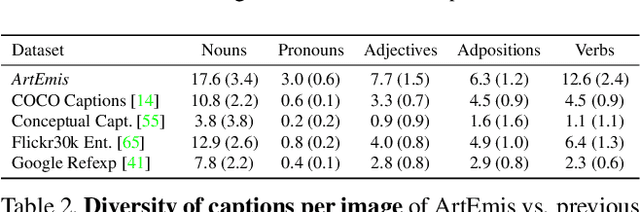
We present a novel large-scale dataset and accompanying machine learning models aimed at providing a detailed understanding of the interplay between visual content, its emotional effect, and explanations for the latter in language. In contrast to most existing annotation datasets in computer vision, we focus on the affective experience triggered by visual artworks and ask the annotators to indicate the dominant emotion they feel for a given image and, crucially, to also provide a grounded verbal explanation for their emotion choice. As we demonstrate below, this leads to a rich set of signals for both the objective content and the affective impact of an image, creating associations with abstract concepts (e.g., "freedom" or "love"), or references that go beyond what is directly visible, including visual similes and metaphors, or subjective references to personal experiences. We focus on visual art (e.g., paintings, artistic photographs) as it is a prime example of imagery created to elicit emotional responses from its viewers. Our dataset, termed ArtEmis, contains 439K emotion attributions and explanations from humans, on 81K artworks from WikiArt. Building on this data, we train and demonstrate a series of captioning systems capable of expressing and explaining emotions from visual stimuli. Remarkably, the captions produced by these systems often succeed in reflecting the semantic and abstract content of the image, going well beyond systems trained on existing datasets. The collected dataset and developed methods are available at https://artemisdataset.org.