 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVR-RAG: Open-vocabulary Species Recognition with RAG-Assisted Large Multi-Modal Models
May 08, 2025Open-vocabulary recognition remains a challenging problem in computer vision, as it requires identifying objects from an unbounded set of categories. This is particularly relevant in nature, where new species are discovered every year. In this work, we focus on open-vocabulary bird species recognition, where the goal is to classify species based on their descriptions without being constrained to a predefined set of taxonomic categories. Traditional benchmarks like CUB-200-2011 and Birdsnap have been evaluated in a closed-vocabulary paradigm, limiting their applicability to real-world scenarios where novel species continually emerge. We show that the performance of current systems when evaluated under settings closely aligned with open-vocabulary drops by a huge margin. To address this gap, we propose a scalable framework integrating structured textual knowledge from Wikipedia articles of 11,202 bird species distilled via GPT-4o into concise, discriminative summaries. We propose Visual Re-ranking Retrieval-Augmented Generation(VR-RAG), a novel, retrieval-augmented generation framework that uses visual similarities to rerank the top m candidates retrieved by a set of multimodal vision language encoders. This allows for the recognition of unseen taxa. Extensive experiments across five established classification benchmarks show that our approach is highly effective. By integrating VR-RAG, we improve the average performance of state-of-the-art Large Multi-Modal Model QWEN2.5-VL by 15.4% across five benchmarks. Our approach outperforms conventional VLM-based approaches, which struggle with unseen species. By bridging the gap between encyclopedic knowledge and visual recognition, our work advances open-vocabulary recognition, offering a flexible, scalable solution for biodiversity monitoring and ecological research.
How Well Can Vision Language Models See Image Details?
Aug 07, 2024



Large Language Model-based Vision-Language Models (LLM-based VLMs) have demonstrated impressive results in various vision-language understanding tasks. However, how well these VLMs can see image detail beyond the semantic level remains unclear. In our study, we introduce a pixel value prediction task (PVP) to explore "How Well Can Vision Language Models See Image Details?" and to assist VLMs in perceiving more details. Typically, these models comprise a frozen CLIP visual encoder, a large language model, and a connecting module. After fine-tuning VLMs on the PVP task, we find: 1) existing VLMs struggle to predict precise pixel values by only fine-tuning the connection module and LLM; and 2) prediction precision is significantly improved when the vision encoder is also adapted. Additionally, our research reveals that incorporating pixel value prediction as one of the VLM pre-training tasks and vision encoder adaptation markedly boosts VLM performance on downstream image-language understanding tasks requiring detailed image perception, such as referring image segmentation (with an average +10.19 cIoU improvement) and video game decision making (with average score improvements of +80.34 and +70.54 on two games, respectively).
AI Art Neural Constellation: Revealing the Collective and Contrastive State of AI-Generated and Human Art
Feb 04, 2024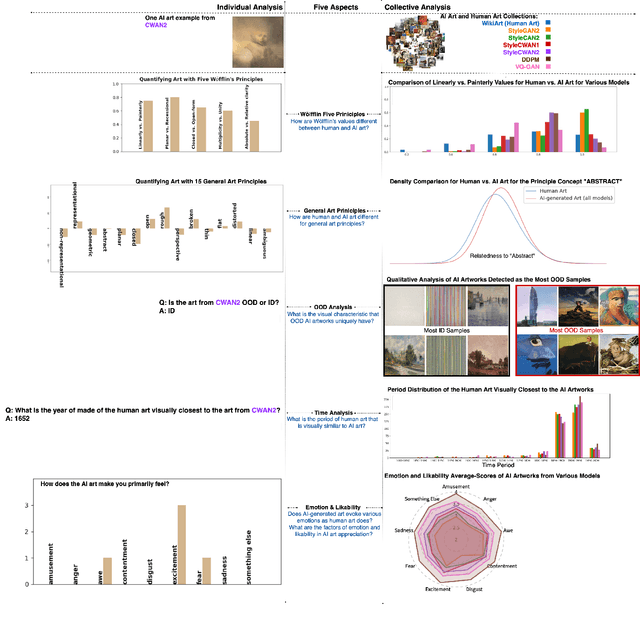
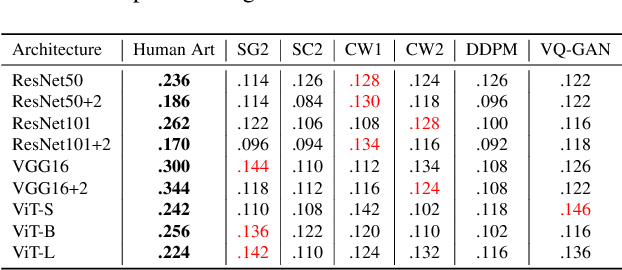
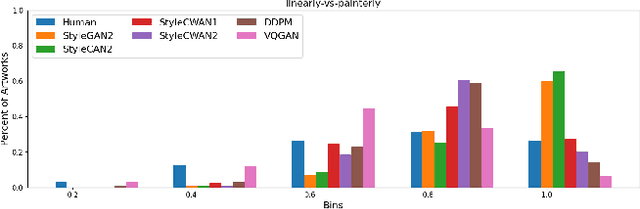
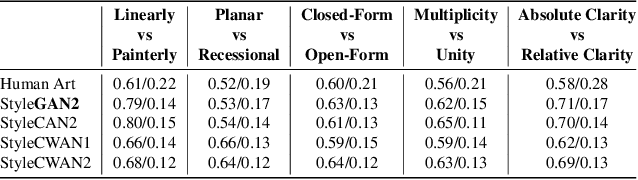
Discovering the creative potentials of a random signal to various artistic expressions in aesthetic and conceptual richness is a ground for the recent success of generative machine learning as a way of art creation. To understand the new artistic medium better, we conduct a comprehensive analysis to position AI-generated art within the context of human art heritage. Our comparative analysis is based on an extensive dataset, dubbed ``ArtConstellation,'' consisting of annotations about art principles, likability, and emotions for 6,000 WikiArt and 3,200 AI-generated artworks. After training various state-of-the-art generative models, art samples are produced and compared with WikiArt data on the last hidden layer of a deep-CNN trained for style classification. We actively examined the various art principles to interpret the neural representations and used them to drive the comparative knowledge about human and AI-generated art. A key finding in the semantic analysis is that AI-generated artworks are visually related to the principle concepts for modern period art made in 1800-2000. In addition, through Out-Of-Distribution (OOD) and In-Distribution (ID) detection in CLIP space, we find that AI-generated artworks are ID to human art when they depict landscapes and geometric abstract figures, while detected as OOD when the machine art consists of deformed and twisted figures. We observe that machine-generated art is uniquely characterized by incomplete and reduced figuration. Lastly, we conducted a human survey about emotional experience. Color composition and familiar subjects are the key factors of likability and emotions in art appreciation. We propose our whole methodologies and collected dataset as our analytical framework to contrast human and AI-generated art, which we refer to as ``ArtNeuralConstellation''. Code is available at: https://github.com/faixan-khan/ArtNeuralConstellation
HRS-Bench: Holistic, Reliable and Scalable Benchmark for Text-to-Image Models
Apr 11, 2023



In recent years, Text-to-Image (T2I) models have been extensively studied, especially with the emergence of diffusion models that achieve state-of-the-art results on T2I synthesis tasks. However, existing benchmarks heavily rely on subjective human evaluation, limiting their ability to holistically assess the model's capabilities. Furthermore, there is a significant gap between efforts in developing new T2I architectures and those in evaluation. To address this, we introduce HRS-Bench, a concrete evaluation benchmark for T2I models that is Holistic, Reliable, and Scalable. Unlike existing bench-marks that focus on limited aspects, HRS-Bench measures 13 skills that can be categorized into five major categories: accuracy, robustness, generalization, fairness, and bias. In addition, HRS-Bench covers 50 scenarios, including fashion, animals, transportation, food, and clothes. We evaluate nine recent large-scale T2I models using metrics that cover a wide range of skills. A human evaluation aligned with 95% of our evaluations on average was conducted to probe the effectiveness of HRS-Bench. Our experiments demonstrate that existing models often struggle to generate images with the desired count of objects, visual text, or grounded emotions. We hope that our benchmark help ease future text-to-image generation research. The code and data are available at https://eslambakr.github.io/hrsbench.github.io
It is Okay to Not Be Okay: Overcoming Emotional Bias in Affective Image Captioning by Contrastive Data Collection
Apr 15, 2022

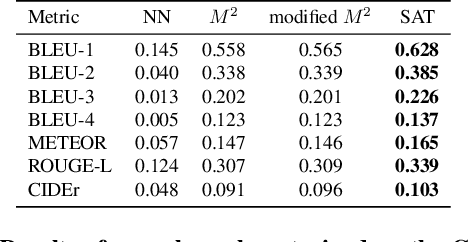

Datasets that capture the connection between vision, language, and affection are limited, causing a lack of understanding of the emotional aspect of human intelligence. As a step in this direction, the ArtEmis dataset was recently introduced as a large-scale dataset of emotional reactions to images along with language explanations of these chosen emotions. We observed a significant emotional bias towards instance-rich emotions, making trained neural speakers less accurate in describing under-represented emotions. We show that collecting new data, in the same way, is not effective in mitigating this emotional bias. To remedy this problem, we propose a contrastive data collection approach to balance ArtEmis with a new complementary dataset such that a pair of similar images have contrasting emotions (one positive and one negative). We collected 260,533 instances using the proposed method, we combine them with ArtEmis, creating a second iteration of the dataset. The new combined dataset, dubbed ArtEmis v2.0, has a balanced distribution of emotions with explanations revealing more fine details in the associated painting. Our experiments show that neural speakers trained on the new dataset improve CIDEr and METEOR evaluation metrics by 20% and 7%, respectively, compared to the biased dataset. Finally, we also show that the performance per emotion of neural speakers is improved across all the emotion categories, significantly on under-represented emotions. The collected dataset and code are available at https://artemisdataset-v2.org.
Intelligent Video Editing: Incorporating Modern Talking Face Generation Algorithms in a Video Editor
Oct 16, 2021
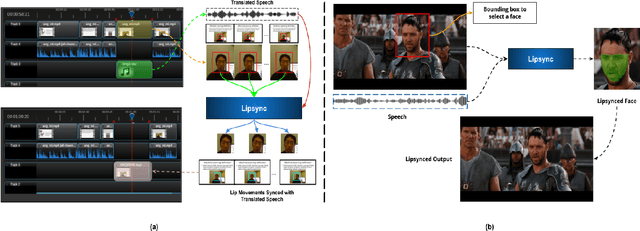

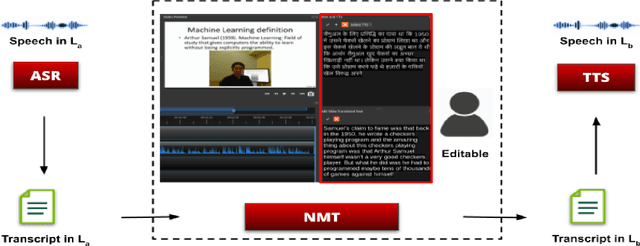
This paper proposes a video editor based on OpenShot with several state-of-the-art facial video editing algorithms as added functionalities. Our editor provides an easy-to-use interface to apply modern lip-syncing algorithms interactively. Apart from lip-syncing, the editor also uses audio and facial re-enactment to generate expressive talking faces. The manual control improves the overall experience of video editing without missing out on the benefits of modern synthetic video generation algorithms. This control enables us to lip-sync complex dubbed movie scenes, interviews, television shows, and other visual content. Furthermore, our editor provides features that automatically translate lectures from spoken content, lip-sync of the professor, and background content like slides. While doing so, we also tackle the critical aspect of synchronizing background content with the translated speech. We qualitatively evaluate the usefulness of the proposed editor by conducting human evaluations. Our evaluations show a clear improvement in the efficiency of using human editors and an improved video generation quality. We attach demo videos with the supplementary material clearly explaining the tool and also showcasing multiple results.
Generating Dataset For Large-scale 3D Facial Emotion Recognition
Sep 16, 2021
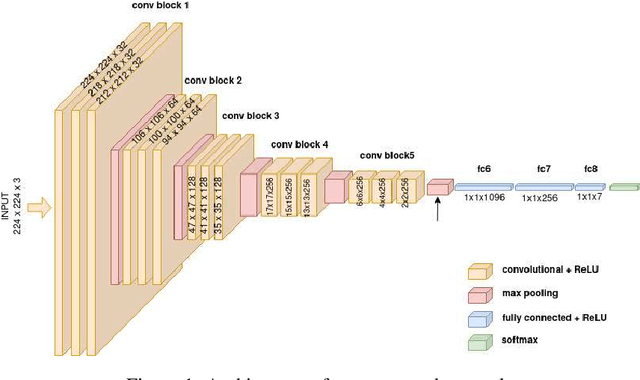

The tremendous development in deep learning has led facial expression recognition (FER) to receive much attention in the past few years. Although 3D FER has an inherent edge over its 2D counterpart, work on 2D images has dominated the field. The main reason for the slow development of 3D FER is the unavailability of large training and large test datasets. Recognition accuracies have already saturated on existing 3D emotion recognition datasets due to their small gallery sizes. Unlike 2D photographs, 3D facial scans are not easy to collect, causing a bottleneck in the development of deep 3D FER networks and datasets. In this work, we propose a method for generating a large dataset of 3D faces with labeled emotions. We also develop a deep convolutional neural network(CNN) for 3D FER trained on 624,000 3D facial scans. The test data comprises 208,000 3D facial scans.