 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3DGen: Triplane Latent Diffusion for Textured Mesh Generation
Mar 09, 2023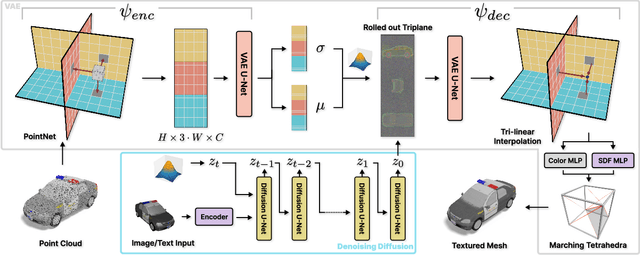
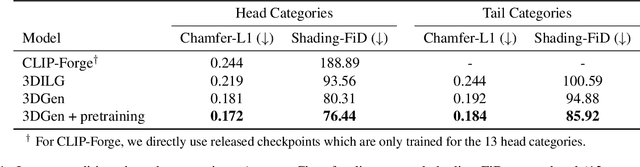

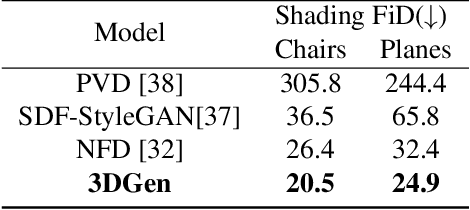
Latent diffusion models for image generation have crossed a quality threshold which enabled them to achieve mass adoption. Recently, a series of works have made advancements towards replicating this success in the 3D domain, introducing techniques such as point cloud VAE, triplane representation, neural implicit surfaces and differentiable rendering based training. We take another step along this direction, combining these developments in a two-step pipeline consisting of 1) a triplane VAE which can learn latent representations of textured meshes and 2) a conditional diffusion model which generates the triplane features. For the first time this architecture allows conditional and unconditional generation of high quality textured or untextured 3D meshes across multiple diverse categories in a few seconds on a single GPU. It outperforms previous work substantially on image-conditioned and unconditional generation on mesh quality as well as texture generation. Furthermore, we demonstrate the scalability of our model to large datasets for increased quality and diversity. We will release our code and trained models.
CLIP-Layout: Style-Consistent Indoor Scene Synthesis with Semantic Furniture Embedding
Mar 07, 2023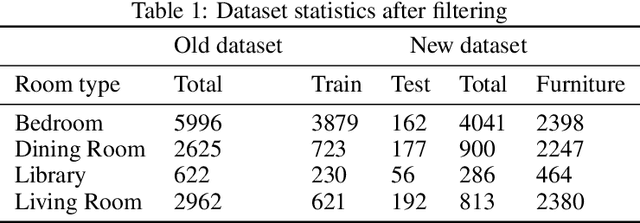



Indoor scene synthesis involves automatically picking and placing furniture appropriately on a floor plan, so that the scene looks realistic and is functionally plausible. Such scenes can serve as a home for immersive 3D experiences, or be used to train embodied agents. Existing methods for this task rely on labeled categories of furniture, e.g. bed, chair or table, to generate contextually relevant combinations of furniture. Whether heuristic or learned, these methods ignore instance-level attributes of objects such as color and style, and as a result may produce visually less coherent scenes. In this paper, we introduce an auto-regressive scene model which can output instance-level predictions, making use of general purpose image embedding based on CLIP. This allows us to learn visual correspondences such as matching color and style, and produce more plausible and aesthetically pleasing scenes. Evaluated on the 3D-FRONT dataset, our model achieves SOTA results in scene generation and improves auto-completion metrics by over 50%. Moreover, our embedding-based approach enables zero-shot text-guided scene generation and editing, which easily generalizes to furniture not seen at training time.
Unsupervised Audio-Visual Lecture Segmentation
Oct 29, 2022
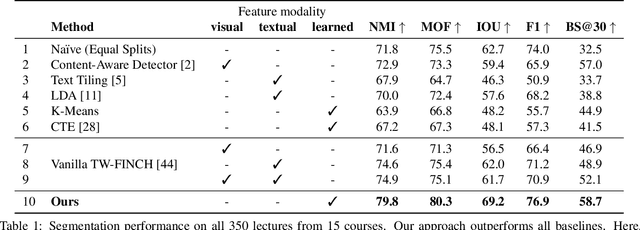
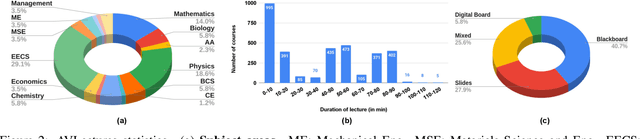

Over the last decade, online lecture videos have become increasingly popular and have experienced a meteoric rise during the pandemic. However, video-language research has primarily focused on instructional videos or movies, and tools to help students navigate the growing online lectures are lacking. Our first contribution is to facilitate research in the educational domain, by introducing AVLectures, a large-scale dataset consisting of 86 courses with over 2,350 lectures covering various STEM subjects. Each course contains video lectures, transcripts, OCR outputs for lecture frames, and optionally lecture notes, slides, assignments, and related educational content that can inspire a variety of tasks. Our second contribution is introducing video lecture segmentation that splits lectures into bite-sized topics that show promise in improving learner engagement. We formulate lecture segmentation as an unsupervised task that leverages visual, textual, and OCR cues from the lecture, while clip representations are fine-tuned on a pretext self-supervised task of matching the narration with the temporally aligned visual content. We use these representations to generate segments using a temporally consistent 1-nearest neighbor algorithm, TW-FINCH. We evaluate our method on 15 courses and compare it against various visual and textual baselines, outperforming all of them. Our comprehensive ablation studies also identify the key factors driving the success of our approach.
Compressing Video Calls using Synthetic Talking Heads
Oct 07, 2022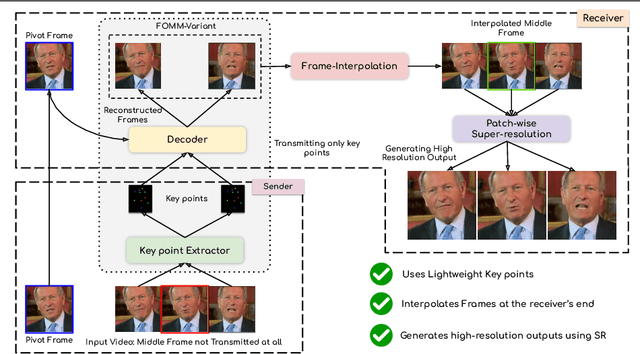
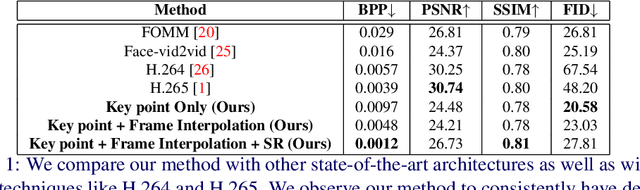
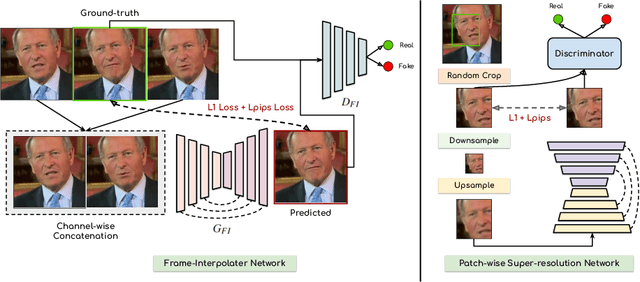
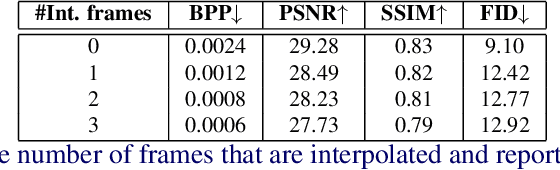
We leverage the modern advancements in talking head generation to propose an end-to-end system for talking head video compression. Our algorithm transmits pivot frames intermittently while the rest of the talking head video is generated by animating them. We use a state-of-the-art face reenactment network to detect key points in the non-pivot frames and transmit them to the receiver. A dense flow is then calculated to warp a pivot frame to reconstruct the non-pivot ones. Transmitting key points instead of full frames leads to significant compression. We propose a novel algorithm to adaptively select the best-suited pivot frames at regular intervals to provide a smooth experience. We also propose a frame-interpolater at the receiver's end to improve the compression levels further. Finally, a face enhancement network improves reconstruction quality, significantly improving several aspects like the sharpness of the generations. We evaluate our method both qualitatively and quantitatively on benchmark datasets and compare it with multiple compression techniques. We release a demo video and additional information at https://cvit.iiit.ac.in/research/projects/cvit-projects/talking-video-compression.
A Study on the Efficiency and Generalization of Light Hybrid Retrievers
Oct 04, 2022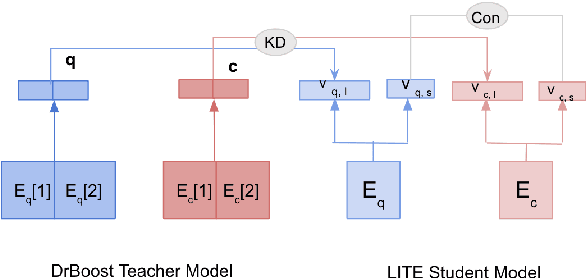
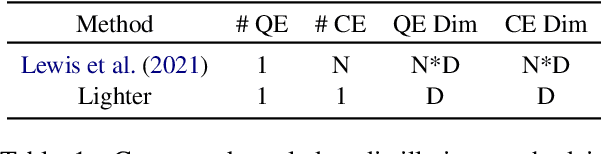
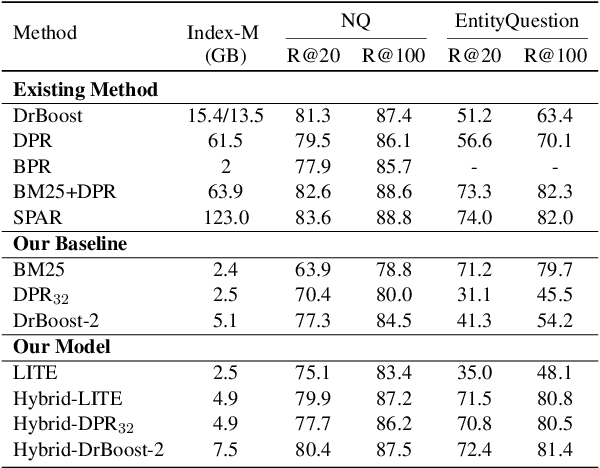
Existing hybrid retrievers which integrate sparse and dense retrievers, are indexing-heavy, limiting their applicability in real-world on-devices settings. We ask the question "Is it possible to reduce the indexing memory of hybrid retrievers without sacrificing performance?" Driven by this question, we leverage an indexing-efficient dense retriever (i.e. DrBoost) to obtain a light hybrid retriever. Moreover, to further reduce the memory, we introduce a lighter dense retriever (LITE) which is jointly trained on contrastive learning and knowledge distillation from DrBoost. Compared to previous heavy hybrid retrievers, our Hybrid-LITE retriever saves 13 memory while maintaining 98.0 performance. In addition, we study the generalization of light hybrid retrievers along two dimensions, out-of-domain (OOD) generalization and robustness against adversarial attacks. We evaluate models on two existing OOD benchmarks and create six adversarial attack sets for robustness evaluation. Experiments show that our light hybrid retrievers achieve better robustness performance than both sparse and dense retrievers. Nevertheless there is a large room to improve the robustness of retrievers, and our datasets can aid future research.
Adapting Pretrained Text-to-Text Models for Long Text Sequences
Sep 21, 2022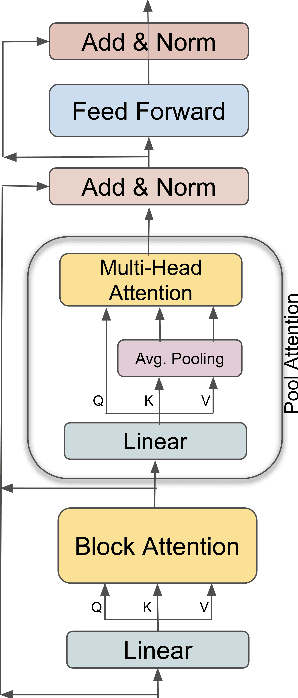
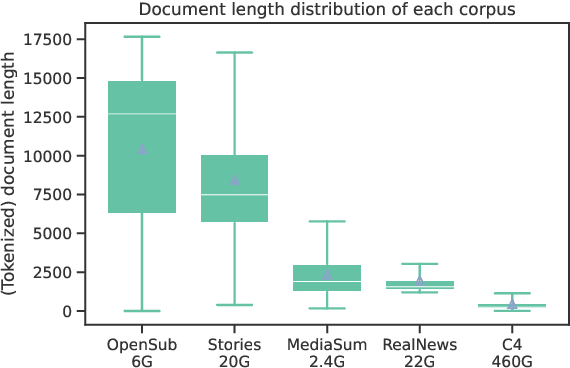
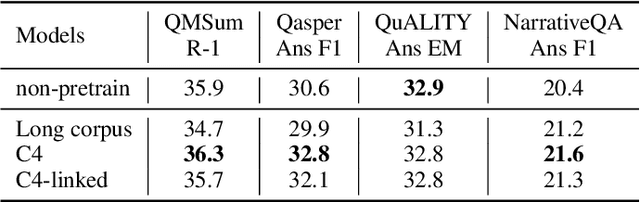
We present an empirical study of adapting an existing pretrained text-to-text model for long-sequence inputs. Through a comprehensive study along three axes of the pretraining pipeline -- model architecture, optimization objective, and pretraining corpus, we propose an effective recipe to build long-context models from existing short-context models. Specifically, we replace the full attention in transformers with pooling-augmented blockwise attention, and pretrain the model with a masked-span prediction task with spans of varying length. In terms of the pretraining corpus, we find that using randomly concatenated short-documents from a large open-domain corpus results in better performance than using existing long document corpora which are typically limited in their domain coverage. With these findings, we build a long-context model that achieves competitive performance on long-text QA tasks and establishes the new state of the art on five long-text summarization datasets, often outperforming previous methods with larger model sizes.
Retrieve-and-Fill for Scenario-based Task-Oriented Semantic Parsing
Feb 02, 2022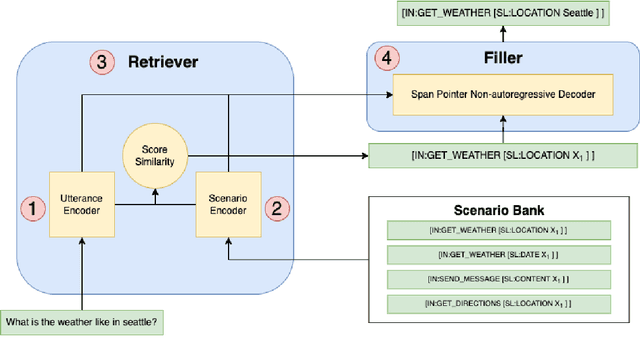
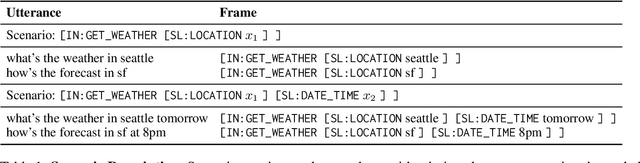


Task-oriented semantic parsing models have achieved strong results in recent years, but unfortunately do not strike an appealing balance between model size, runtime latency, and cross-domain generalizability. We tackle this problem by introducing scenario-based semantic parsing: a variant of the original task which first requires disambiguating an utterance's "scenario" (an intent-slot template with variable leaf spans) before generating its frame, complete with ontology and utterance tokens. This formulation enables us to isolate coarse-grained and fine-grained aspects of the task, each of which we solve with off-the-shelf neural modules, also optimizing for the axes outlined above. Concretely, we create a Retrieve-and-Fill (RAF) architecture comprised of (1) a retrieval module which ranks the best scenario given an utterance and (2) a filling module which imputes spans into the scenario to create the frame. Our model is modular, differentiable, interpretable, and allows us to garner extra supervision from scenarios. RAF achieves strong results in high-resource, low-resource, and multilingual settings, outperforming recent approaches by wide margins despite, using base pre-trained encoders, small sequence lengths, and parallel decoding.
Simple Local Attentions Remain Competitive for Long-Context Tasks
Dec 14, 2021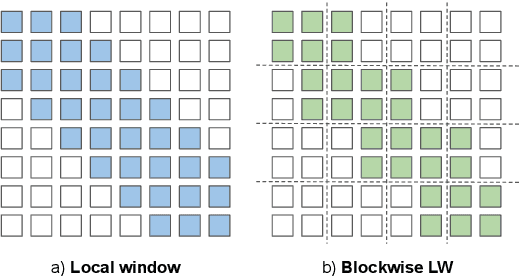
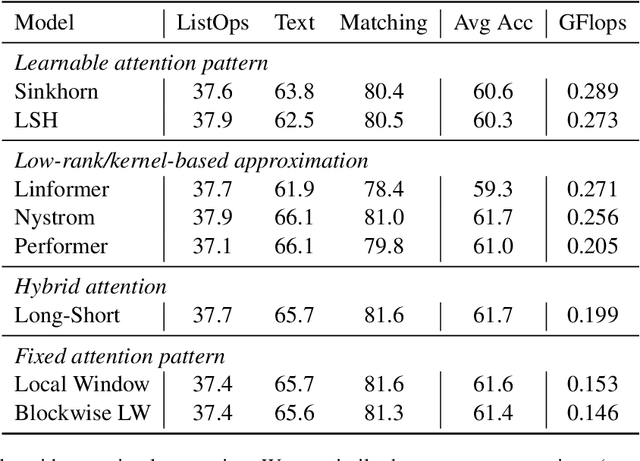
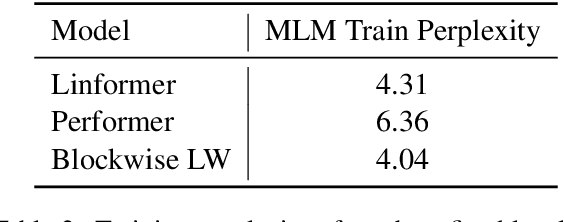
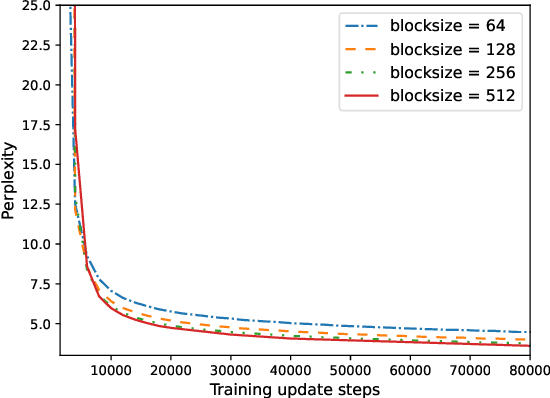
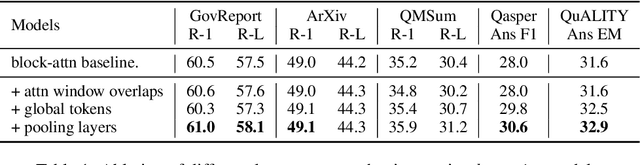
Many NLP tasks require processing long contexts beyond the length limit of pretrained models. In order to scale these models to longer text sequences, many efficient long-range attention variants have been proposed. Despite the abundance of research along this direction, it is still difficult to gauge the relative effectiveness of these models in practical use cases, e.g., if we apply these models following the pretrain-and-finetune paradigm. In this work, we aim to conduct a thorough analysis of these emerging models with large-scale and controlled experiments. For each attention variant, we pretrain large-size models using the same long-doc corpus and then finetune these models for real-world long-context tasks. Our findings reveal pitfalls of an existing widely-used long-range benchmark and show none of the tested efficient attentions can beat a simple local window attention under standard pretraining paradigms. Further analysis on local attention variants suggests that even the commonly used attention-window overlap is not necessary to achieve good downstream results -- using disjoint local attentions, we are able to build a simpler and more efficient long-doc QA model that matches the performance of Longformer~\citep{longformer} with half of its pretraining compute.
Intelligent Video Editing: Incorporating Modern Talking Face Generation Algorithms in a Video Editor
Oct 16, 2021
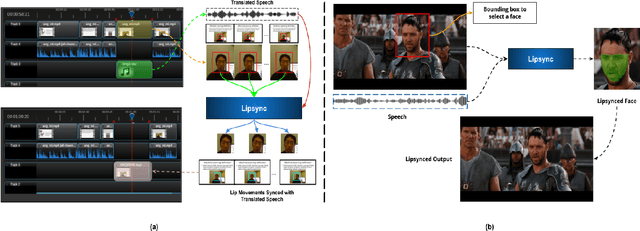

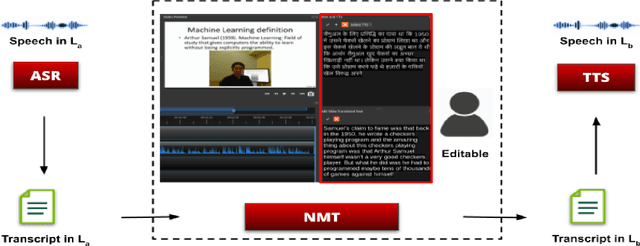
This paper proposes a video editor based on OpenShot with several state-of-the-art facial video editing algorithms as added functionalities. Our editor provides an easy-to-use interface to apply modern lip-syncing algorithms interactively. Apart from lip-syncing, the editor also uses audio and facial re-enactment to generate expressive talking faces. The manual control improves the overall experience of video editing without missing out on the benefits of modern synthetic video generation algorithms. This control enables us to lip-sync complex dubbed movie scenes, interviews, television shows, and other visual content. Furthermore, our editor provides features that automatically translate lectures from spoken content, lip-sync of the professor, and background content like slides. While doing so, we also tackle the critical aspect of synchronizing background content with the translated speech. We qualitatively evaluate the usefulness of the proposed editor by conducting human evaluations. Our evaluations show a clear improvement in the efficiency of using human editors and an improved video generation quality. We attach demo videos with the supplementary material clearly explaining the tool and also showcasing multiple results.
Salient Phrase Aware Dense Retrieval: Can a Dense Retriever Imitate a Sparse One?
Oct 13, 2021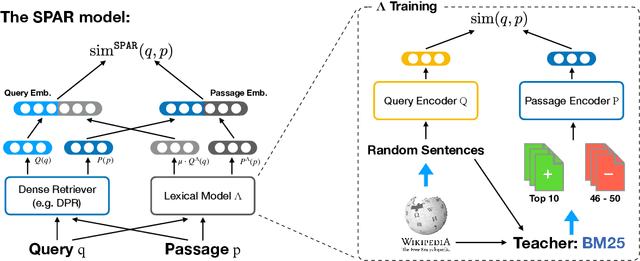
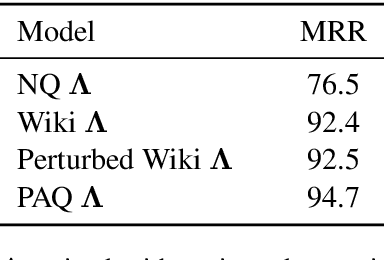
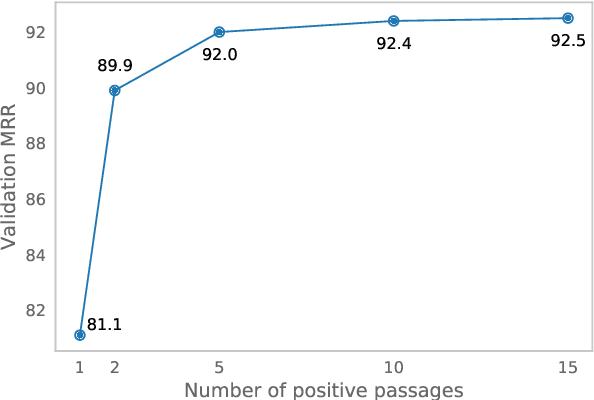
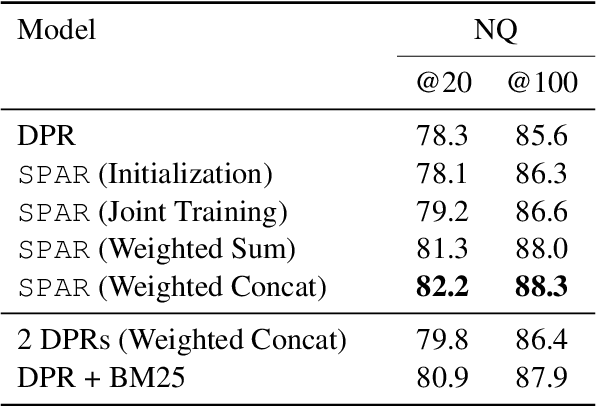
Despite their recent popularity and well known advantages, dense retrievers still lag behind sparse methods such as BM25 in their ability to reliably match salient phrases and rare entities in the query. It has been argued that this is an inherent limitation of dense models. We disprove this claim by introducing the Salient Phrase Aware Retriever (SPAR), a dense retriever with the lexical matching capacity of a sparse model. In particular, we show that a dense retriever {\Lambda} can be trained to imitate a sparse one, and SPAR is built by augmenting a standard dense retriever with {\Lambda}. When evaluated on five open-domain question answering datasets and the MS MARCO passage retrieval task, SPAR sets a new state of the art for dense and sparse retrievers and can match or exceed the performance of more complicated dense-sparse hybrid systems.