 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompt2LVideos: Exploring Prompts for Understanding Long-Form Multimodal Videos
Mar 11, 2025Learning multimodal video understanding typically relies on datasets comprising video clips paired with manually annotated captions. However, this becomes even more challenging when dealing with long-form videos, lasting from minutes to hours, in educational and news domains due to the need for more annotators with subject expertise. Hence, there arises a need for automated solutions. Recent advancements in Large Language Models (LLMs) promise to capture concise and informative content that allows the comprehension of entire videos by leveraging Automatic Speech Recognition (ASR) and Optical Character Recognition (OCR) technologies. ASR provides textual content from audio, while OCR extracts textual content from specific frames. This paper introduces a dataset comprising long-form lectures and news videos. We present baseline approaches to understand their limitations on this dataset and advocate for exploring prompt engineering techniques to comprehend long-form multimodal video datasets comprehensively.
IndicSTR12: A Dataset for Indic Scene Text Recognition
Mar 12, 2024The importance of Scene Text Recognition (STR) in today's increasingly digital world cannot be overstated. Given the significance of STR, data intensive deep learning approaches that auto-learn feature mappings have primarily driven the development of STR solutions. Several benchmark datasets and substantial work on deep learning models are available for Latin languages to meet this need. On more complex, syntactically and semantically, Indian languages spoken and read by 1.3 billion people, there is less work and datasets available. This paper aims to address the Indian space's lack of a comprehensive dataset by proposing the largest and most comprehensive real dataset - IndicSTR12 - and benchmarking STR performance on 12 major Indian languages. A few works have addressed the same issue, but to the best of our knowledge, they focused on a small number of Indian languages. The size and complexity of the proposed dataset are comparable to those of existing Latin contemporaries, while its multilingualism will catalyse the development of robust text detection and recognition models. It was created specifically for a group of related languages with different scripts. The dataset contains over 27000 word-images gathered from various natural scenes, with over 1000 word-images for each language. Unlike previous datasets, the images cover a broader range of realistic conditions, including blur, illumination changes, occlusion, non-iconic texts, low resolution, perspective text etc. Along with the new dataset, we provide a high-performing baseline on three models - PARSeq, CRNN, and STARNet.
Compressing Video Calls using Synthetic Talking Heads
Oct 07, 2022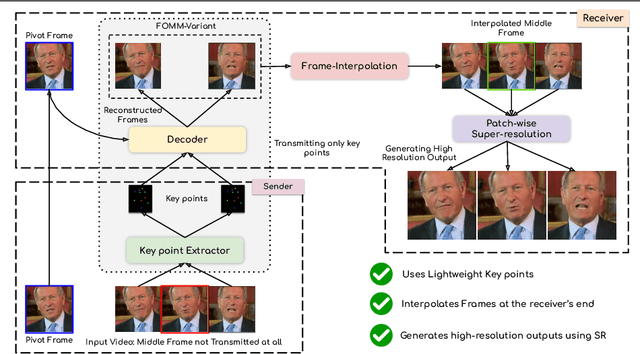
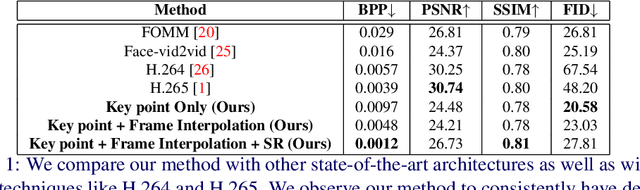
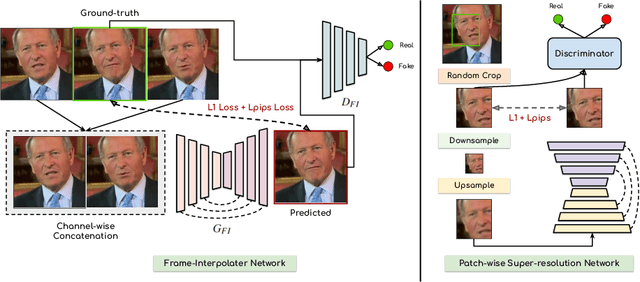
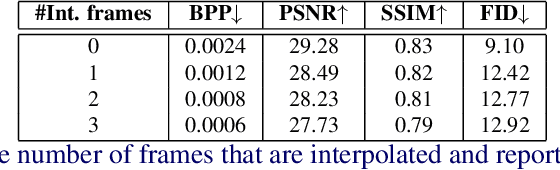
We leverage the modern advancements in talking head generation to propose an end-to-end system for talking head video compression. Our algorithm transmits pivot frames intermittently while the rest of the talking head video is generated by animating them. We use a state-of-the-art face reenactment network to detect key points in the non-pivot frames and transmit them to the receiver. A dense flow is then calculated to warp a pivot frame to reconstruct the non-pivot ones. Transmitting key points instead of full frames leads to significant compression. We propose a novel algorithm to adaptively select the best-suited pivot frames at regular intervals to provide a smooth experience. We also propose a frame-interpolater at the receiver's end to improve the compression levels further. Finally, a face enhancement network improves reconstruction quality, significantly improving several aspects like the sharpness of the generations. We evaluate our method both qualitatively and quantitatively on benchmark datasets and compare it with multiple compression techniques. We release a demo video and additional information at https://cvit.iiit.ac.in/research/projects/cvit-projects/talking-video-compression.
Audio-Visual Face Reenactment
Oct 06, 2022
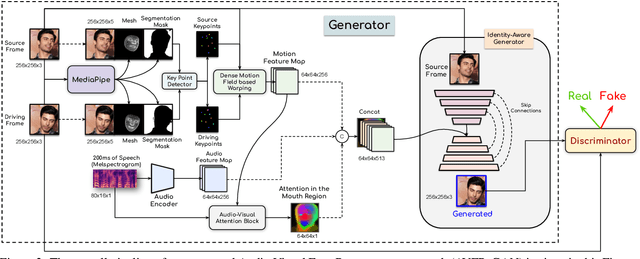


This work proposes a novel method to generate realistic talking head videos using audio and visual streams. We animate a source image by transferring head motion from a driving video using a dense motion field generated using learnable keypoints. We improve the quality of lip sync using audio as an additional input, helping the network to attend to the mouth region. We use additional priors using face segmentation and face mesh to improve the structure of the reconstructed faces. Finally, we improve the visual quality of the generations by incorporating a carefully designed identity-aware generator module. The identity-aware generator takes the source image and the warped motion features as input to generate a high-quality output with fine-grained details. Our method produces state-of-the-art results and generalizes well to unseen faces, languages, and voices. We comprehensively evaluate our approach using multiple metrics and outperforming the current techniques both qualitative and quantitatively. Our work opens up several applications, including enabling low bandwidth video calls. We release a demo video and additional information at http://cvit.iiit.ac.in/research/projects/cvit-projects/avfr.
Visual Understanding of Complex Table Structures from Document Images
Nov 13, 2021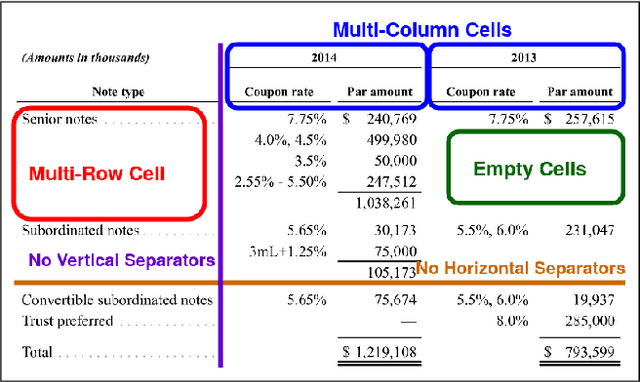
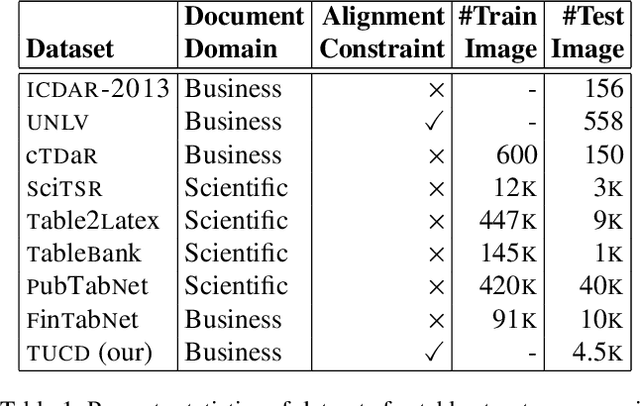
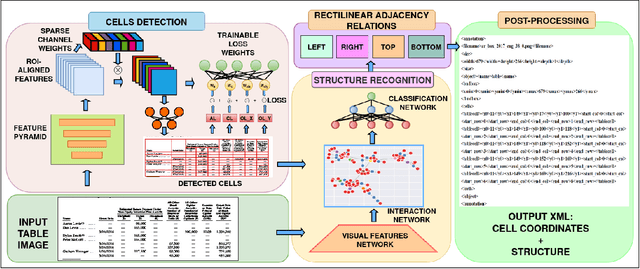
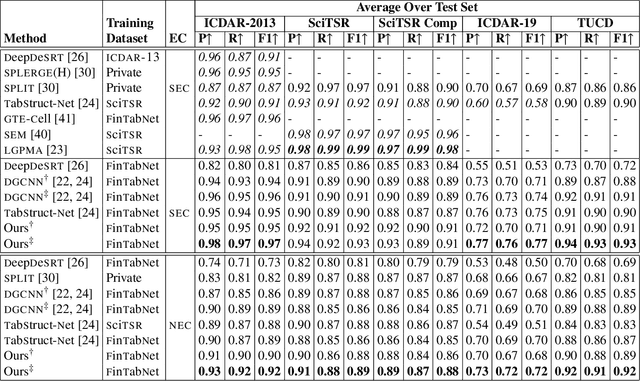
Table structure recognition is necessary for a comprehensive understanding of documents. Tables in unstructured business documents are tough to parse due to the high diversity of layouts, varying alignments of contents, and the presence of empty cells. The problem is particularly difficult because of challenges in identifying individual cells using visual or linguistic contexts or both. Accurate detection of table cells (including empty cells) simplifies structure extraction and hence, it becomes the prime focus of our work. We propose a novel object-detection-based deep model that captures the inherent alignments of cells within tables and is fine-tuned for fast optimization. Despite accurate detection of cells, recognizing structures for dense tables may still be challenging because of difficulties in capturing long-range row/column dependencies in presence of multi-row/column spanning cells. Therefore, we also aim to improve structure recognition by deducing a novel rectilinear graph-based formulation. From a semantics perspective, we highlight the significance of empty cells in a table. To take these cells into account, we suggest an enhancement to a popular evaluation criterion. Finally, we introduce a modestly sized evaluation dataset with an annotation style inspired by human cognition to encourage new approaches to the problem. Our framework improves the previous state-of-the-art performance by a 2.7% average F1-score on benchmark datasets.
Personalized One-Shot Lipreading for an ALS Patient
Nov 02, 2021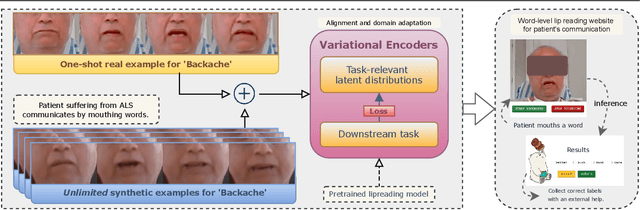

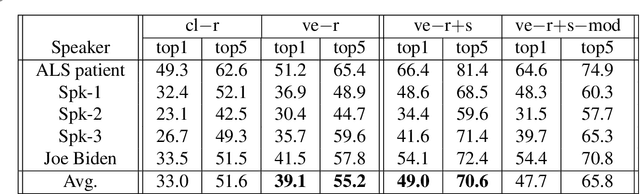
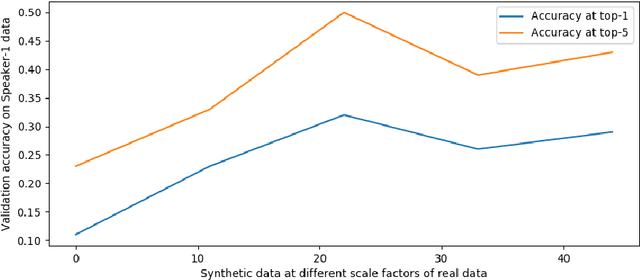
Lipreading or visually recognizing speech from the mouth movements of a speaker is a challenging and mentally taxing task. Unfortunately, multiple medical conditions force people to depend on this skill in their day-to-day lives for essential communication. Patients suffering from Amyotrophic Lateral Sclerosis (ALS) often lose muscle control, consequently their ability to generate speech and communicate via lip movements. Existing large datasets do not focus on medical patients or curate personalized vocabulary relevant to an individual. Collecting a large-scale dataset of a patient, needed to train mod-ern data-hungry deep learning models is, however, extremely challenging. In this work, we propose a personalized network to lipread an ALS patient using only one-shot examples. We depend on synthetically generated lip movements to augment the one-shot scenario. A Variational Encoder based domain adaptation technique is used to bridge the real-synthetic domain gap. Our approach significantly improves and achieves high top-5accuracy with 83.2% accuracy compared to 62.6% achieved by comparable methods for the patient. Apart from evaluating our approach on the ALS patient, we also extend it to people with hearing impairment relying extensively on lip movements to communicate.
More Parameters? No Thanks!
Jul 20, 2021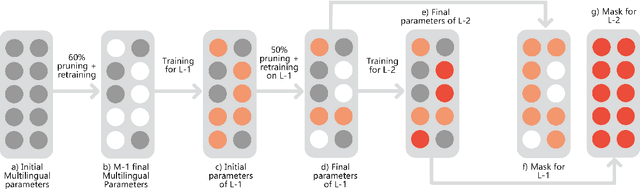
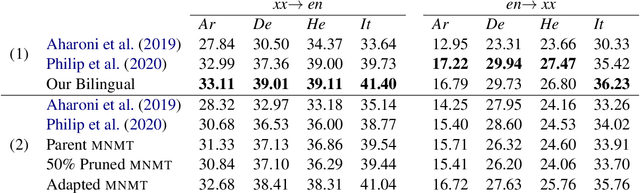
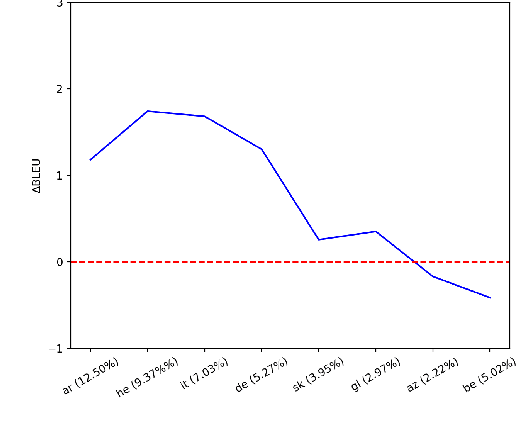

This work studies the long-standing problems of model capacity and negative interference in multilingual neural machine translation MNMT. We use network pruning techniques and observe that pruning 50-70% of the parameters from a trained MNMT model results only in a 0.29-1.98 drop in the BLEU score. Suggesting that there exist large redundancies even in MNMT models. These observations motivate us to use the redundant parameters and counter the interference problem efficiently. We propose a novel adaptation strategy, where we iteratively prune and retrain the redundant parameters of an MNMT to improve bilingual representations while retaining the multilinguality. Negative interference severely affects high resource languages, and our method alleviates it without any additional adapter modules. Hence, we call it parameter-free adaptation strategy, paving way for the efficient adaptation of MNMT. We demonstrate the effectiveness of our method on a 9 language MNMT trained on TED talks, and report an average improvement of +1.36 BLEU on high resource pairs. Code will be released here.
Towards Automatic Speech to Sign Language Generation
Jun 24, 2021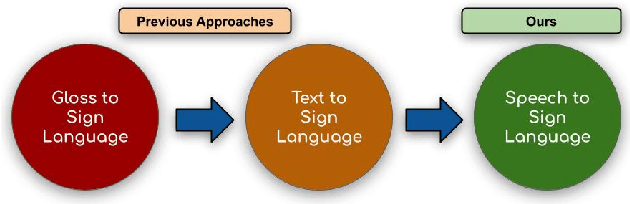
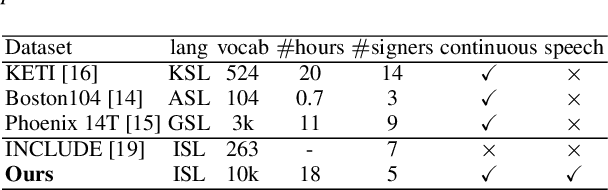

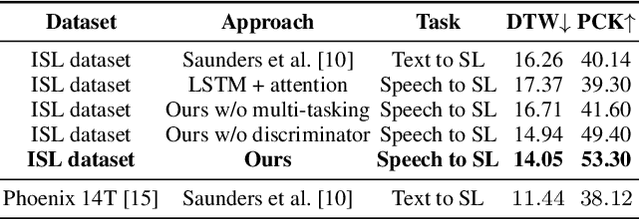
We aim to solve the highly challenging task of generating continuous sign language videos solely from speech segments for the first time. Recent efforts in this space have focused on generating such videos from human-annotated text transcripts without considering other modalities. However, replacing speech with sign language proves to be a practical solution while communicating with people suffering from hearing loss. Therefore, we eliminate the need of using text as input and design techniques that work for more natural, continuous, freely uttered speech covering an extensive vocabulary. Since the current datasets are inadequate for generating sign language directly from speech, we collect and release the first Indian sign language dataset comprising speech-level annotations, text transcripts, and the corresponding sign-language videos. Next, we propose a multi-tasking transformer network trained to generate signer's poses from speech segments. With speech-to-text as an auxiliary task and an additional cross-modal discriminator, our model learns to generate continuous sign pose sequences in an end-to-end manner. Extensive experiments and comparisons with other baselines demonstrate the effectiveness of our approach. We also conduct additional ablation studies to analyze the effect of different modules of our network. A demo video containing several results is attached to the supplementary material.
Canonical Saliency Maps: Decoding Deep Face Models
May 04, 2021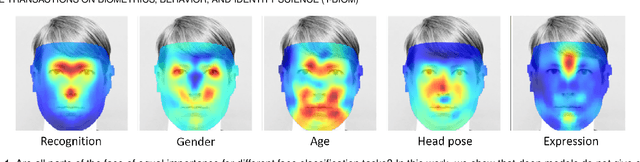

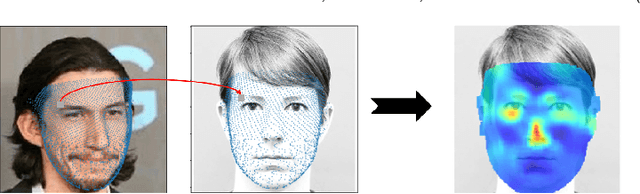

As Deep Neural Network models for face processing tasks approach human-like performance, their deployment in critical applications such as law enforcement and access control has seen an upswing, where any failure may have far-reaching consequences. We need methods to build trust in deployed systems by making their working as transparent as possible. Existing visualization algorithms are designed for object recognition and do not give insightful results when applied to the face domain. In this work, we present 'Canonical Saliency Maps', a new method that highlights relevant facial areas by projecting saliency maps onto a canonical face model. We present two kinds of Canonical Saliency Maps: image-level maps and model-level maps. Image-level maps highlight facial features responsible for the decision made by a deep face model on a given image, thus helping to understand how a DNN made a prediction on the image. Model-level maps provide an understanding of what the entire DNN model focuses on in each task and thus can be used to detect biases in the model. Our qualitative and quantitative results show the usefulness of the proposed canonical saliency maps, which can be used on any deep face model regardless of the architecture.
Exploring Pair-Wise NMT for Indian Languages
Dec 10, 2020
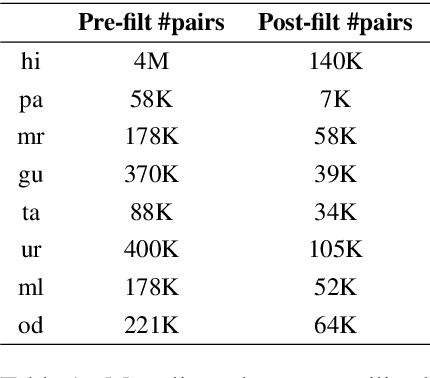
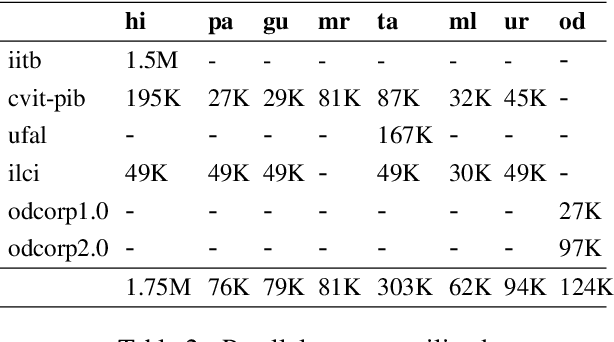
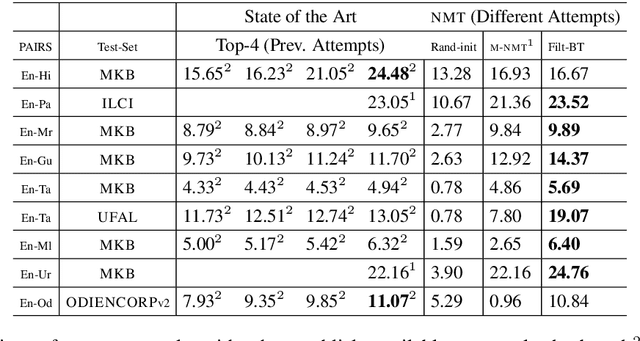
In this paper, we address the task of improving pair-wise machine translation for specific low resource Indian languages. Multilingual NMT models have demonstrated a reasonable amount of effectiveness on resource-poor languages. In this work, we show that the performance of these models can be significantly improved upon by using back-translation through a filtered back-translation process and subsequent fine-tuning on the limited pair-wise language corpora. The analysis in this paper suggests that this method can significantly improve a multilingual model's performance over its baseline, yielding state-of-the-art results for various Indian languages.