 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Question Answering on Handwritten Documents: A State-of-the-Art Recognition-Based Model for HW-SQuAD
Jun 25, 2024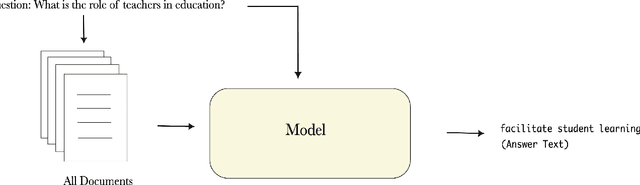
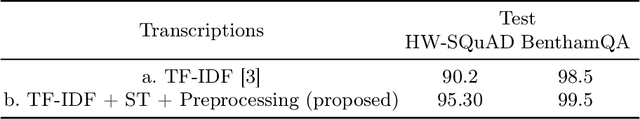
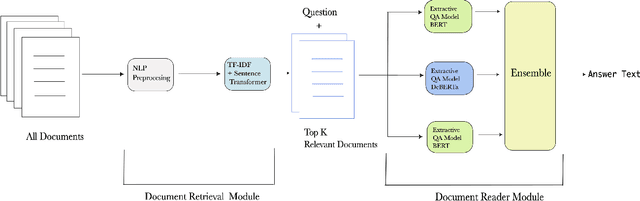

Question-answering handwritten documents is a challenging task with numerous real-world applications. This paper proposes a novel recognition-based approach that improves upon the previous state-of-the-art on the HW-SQuAD and BenthamQA datasets. Our model incorporates transformer-based document retrieval and ensemble methods at the model level, achieving an Exact Match score of 82.02% and 92.55% in HW-SQuAD and BenthamQA datasets, respectively, surpassing the previous best recognition-based approach by 10.89% and 26%. We also enhance the document retrieval component, boosting the top-5 retrieval accuracy from 90% to 95.30%. Our results demonstrate the significance of our proposed approach in advancing question answering on handwritten documents. The code and trained models will be publicly available to facilitate future research in this critical area of natural language.
IndicSTR12: A Dataset for Indic Scene Text Recognition
Mar 12, 2024The importance of Scene Text Recognition (STR) in today's increasingly digital world cannot be overstated. Given the significance of STR, data intensive deep learning approaches that auto-learn feature mappings have primarily driven the development of STR solutions. Several benchmark datasets and substantial work on deep learning models are available for Latin languages to meet this need. On more complex, syntactically and semantically, Indian languages spoken and read by 1.3 billion people, there is less work and datasets available. This paper aims to address the Indian space's lack of a comprehensive dataset by proposing the largest and most comprehensive real dataset - IndicSTR12 - and benchmarking STR performance on 12 major Indian languages. A few works have addressed the same issue, but to the best of our knowledge, they focused on a small number of Indian languages. The size and complexity of the proposed dataset are comparable to those of existing Latin contemporaries, while its multilingualism will catalyse the development of robust text detection and recognition models. It was created specifically for a group of related languages with different scripts. The dataset contains over 27000 word-images gathered from various natural scenes, with over 1000 word-images for each language. Unlike previous datasets, the images cover a broader range of realistic conditions, including blur, illumination changes, occlusion, non-iconic texts, low resolution, perspective text etc. Along with the new dataset, we provide a high-performing baseline on three models - PARSeq, CRNN, and STARNet.
Towards Robust Handwritten Text Recognition with On-the-fly User Participation
Dec 17, 2022Long-term OCR services aim to provide high-quality output to their users at competitive costs. It is essential to upgrade the models because of the complex data loaded by the users. The service providers encourage the users who provide data where the OCR model fails by rewarding them based on data complexity, readability, and available budget. Hitherto, the OCR works include preparing the models on standard datasets without considering the end-users. We propose a strategy of consistently upgrading an existing Handwritten Hindi OCR model three times on the dataset of 15 users. We fix the budget of 4 users for each iteration. For the first iteration, the model directly trains on the dataset from the first four users. For the rest iteration, all remaining users write a page each, which service providers later analyze to select the 4 (new) best users based on the quality of predictions on the human-readable words. Selected users write 23 more pages for upgrading the model. We upgrade the model with Curriculum Learning (CL) on the data available in the current iteration and compare the subset from previous iterations. The upgraded model is tested on a held-out set of one page each from all 23 users. We provide insights into our investigations on the effect of CL, user selection, and especially the data from unseen writing styles. Our work can be used for long-term OCR services in crowd-sourcing scenarios for the service providers and end users.
Enhancing Indic Handwritten Text Recognition Using Global Semantic Information
Dec 15, 2022Handwritten Text Recognition (HTR) is more interesting and challenging than printed text due to uneven variations in the handwriting style of the writers, content, and time. HTR becomes more challenging for the Indic languages because of (i) multiple characters combined to form conjuncts which increase the number of characters of respective languages, and (ii) near to 100 unique basic Unicode characters in each Indic script. Recently, many recognition methods based on the encoder-decoder framework have been proposed to handle such problems. They still face many challenges, such as image blur and incomplete characters due to varying writing styles and ink density. We argue that most encoder-decoder methods are based on local visual features without explicit global semantic information. In this work, we enhance the performance of Indic handwritten text recognizers using global semantic information. We use a semantic module in an encoder-decoder framework for extracting global semantic information to recognize the Indic handwritten texts. The semantic information is used in both the encoder for supervision and the decoder for initialization. The semantic information is predicted from the word embedding of a pre-trained language model. Extensive experiments demonstrate that the proposed framework achieves state-of-the-art results on handwritten texts of ten Indic languages.
Classroom Slide Narration System
Jan 21, 2022

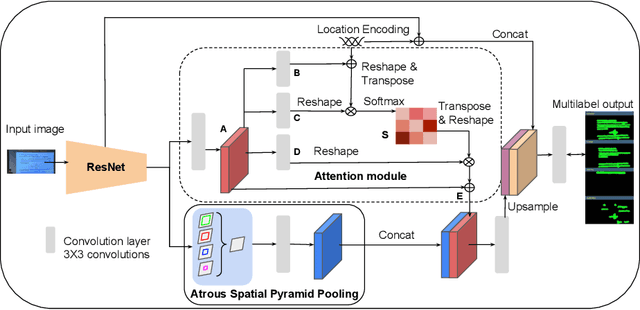

Slide presentations are an effective and efficient tool used by the teaching community for classroom communication. However, this teaching model can be challenging for blind and visually impaired (VI) students. The VI student required personal human assistance for understand the presented slide. This shortcoming motivates us to design a Classroom Slide Narration System (CSNS) that generates audio descriptions corresponding to the slide content. This problem poses as an image-to-markup language generation task. The initial step is to extract logical regions such as title, text, equation, figure, and table from the slide image. In the classroom slide images, the logical regions are distributed based on the location of the image. To utilize the location of the logical regions for slide image segmentation, we propose the architecture, Classroom Slide Segmentation Network (CSSN). The unique attributes of this architecture differs from most other semantic segmentation networks. Publicly available benchmark datasets such as WiSe and SPaSe are used to validate the performance of our segmentation architecture. We obtained 9.54 segmentation accuracy improvement in WiSe dataset. We extract content (information) from the slide using four well-established modules such as optical character recognition (OCR), figure classification, equation description, and table structure recognizer. With this information, we build a Classroom Slide Narration System (CSNS) to help VI students understand the slide content. The users have given better feedback on the quality output of the proposed CSNS in comparison to existing systems like Facebooks Automatic Alt-Text (AAT) and Tesseract.
New Performance Measures for Object Tracking under Complex Environments
Nov 13, 2021Various performance measures based on the ground truth and without ground truth exist to evaluate the quality of a developed tracking algorithm. The existing popular measures - average center location error (ACLE) and average tracking accuracy (ATA) based on ground truth, may sometimes create confusion to quantify the quality of a developed algorithm for tracking an object under some complex environments (e.g., scaled or oriented or both scaled and oriented object). In this article, we propose three new auxiliary performance measures based on ground truth information to evaluate the quality of a developed tracking algorithm under such complex environments. Moreover, one performance measure is developed by combining both two existing measures ACLE and ATA and three new proposed measures for better quantifying the developed tracking algorithm under such complex conditions. Some examples and experimental results conclude that the proposed measure is better than existing measures to quantify one developed algorithm for tracking objects under such complex environments.
Visual Understanding of Complex Table Structures from Document Images
Nov 13, 2021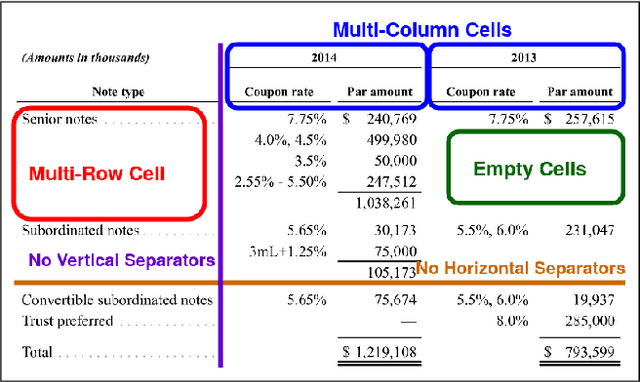
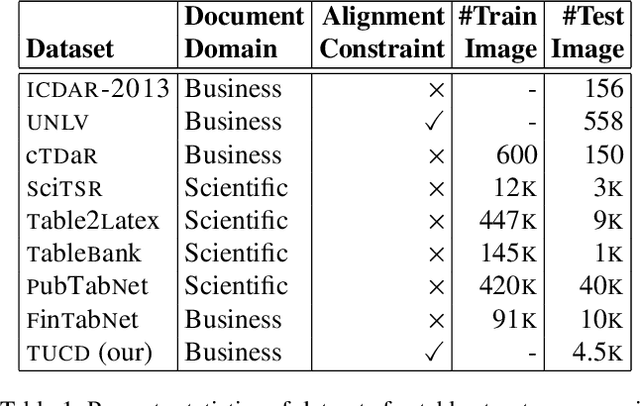
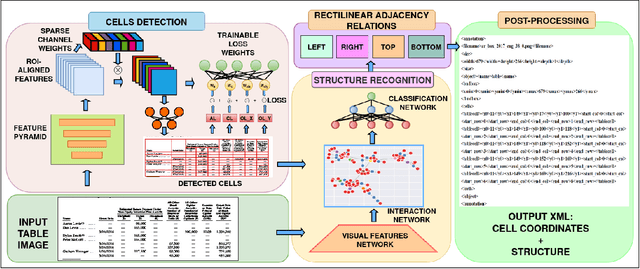
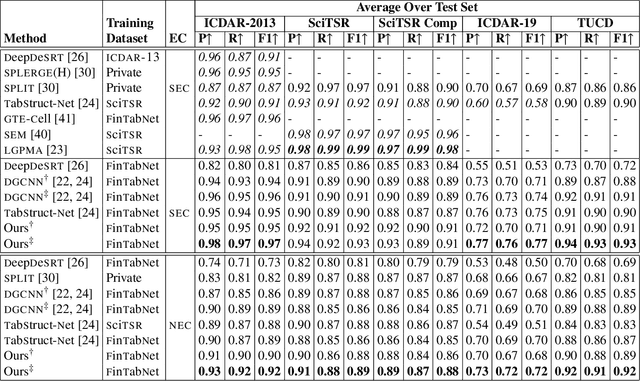
Table structure recognition is necessary for a comprehensive understanding of documents. Tables in unstructured business documents are tough to parse due to the high diversity of layouts, varying alignments of contents, and the presence of empty cells. The problem is particularly difficult because of challenges in identifying individual cells using visual or linguistic contexts or both. Accurate detection of table cells (including empty cells) simplifies structure extraction and hence, it becomes the prime focus of our work. We propose a novel object-detection-based deep model that captures the inherent alignments of cells within tables and is fine-tuned for fast optimization. Despite accurate detection of cells, recognizing structures for dense tables may still be challenging because of difficulties in capturing long-range row/column dependencies in presence of multi-row/column spanning cells. Therefore, we also aim to improve structure recognition by deducing a novel rectilinear graph-based formulation. From a semantics perspective, we highlight the significance of empty cells in a table. To take these cells into account, we suggest an enhancement to a popular evaluation criterion. Finally, we introduce a modestly sized evaluation dataset with an annotation style inspired by human cognition to encourage new approaches to the problem. Our framework improves the previous state-of-the-art performance by a 2.7% average F1-score on benchmark datasets.
Deep Neural Networks for Automatic Grain-matrix Segmentation in Plane and Cross-polarized Sandstone Photomicrographs
Nov 13, 2021


Grain segmentation of sandstone that is partitioning the grain from its surrounding matrix/cement in the thin section is the primary step for computer-aided mineral identification and sandstone classification. The microscopic images of sandstone contain many mineral grains and their surrounding matrix/cement. The distinction between adjacent grains and the matrix is often ambiguous, making grain segmentation difficult. Various solutions exist in literature to handle these problems; however, they are not robust against sandstone petrography's varied pattern. In this paper, we formulate grain segmentation as a pixel-wise two-class (i.e., grain and background) semantic segmentation task. We develop a deep learning-based end-to-end trainable framework named Deep Semantic Grain Segmentation network (DSGSN), a data-driven method, and provide a generic solution. As per the authors' knowledge, this is the first work where the deep neural network is explored to solve the grain segmentation problem. Extensive experiments on microscopic images highlight that our method obtains better segmentation accuracy than various segmentation architectures with more parameters.
Camouflaged Object Detection and Tracking: A Survey
Dec 25, 2020
Moving object detection and tracking have various applications, including surveillance, anomaly detection, vehicle navigation, etc. The literature on object detection and tracking is rich enough, and several essential survey papers exist. However, the research on camouflage object detection and tracking limited due to the complexity of the problem. Existing work on this problem has been done based on either biological characteristics of the camouflaged objects or computer vision techniques. In this article, we review the existing camouflaged object detection and tracking techniques using computer vision algorithms from the theoretical point of view. This article also addresses several issues of interest as well as future research direction on this area. We hope this review will help the reader to learn the recent advances in camouflaged object detection and tracking.
Table Structure Recognition using Top-Down and Bottom-Up Cues
Oct 09, 2020



Tables are information-rich structured objects in document images. While significant work has been done in localizing tables as graphic objects in document images, only limited attempts exist on table structure recognition. Most existing literature on structure recognition depends on extraction of meta-features from the PDF document or on the optical character recognition (OCR) models to extract low-level layout features from the image. However, these methods fail to generalize well because of the absence of meta-features or errors made by the OCR when there is a significant variance in table layouts and text organization. In our work, we focus on tables that have complex structures, dense content, and varying layouts with no dependency on meta-features and/or OCR. We present an approach for table structure recognition that combines cell detection and interaction modules to localize the cells and predict their row and column associations with other detected cells. We incorporate structural constraints as additional differential components to the loss function for cell detection. We empirically validate our method on the publicly available real-world datasets - ICDAR-2013, ICDAR-2019 (cTDaR) archival, UNLV, SciTSR, SciTSR-COMP, TableBank, and PubTabNet. Our attempt opens up a new direction for table structure recognition by combining top-down (table cells detection) and bottom-up (structure recognition) cues in visually understanding the tables.