 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoTeS-Bank: Benchmarking Neural Transcription and Search for Scientific Notes Understanding
Apr 12, 2025Understanding and reasoning over academic handwritten notes remains a challenge in document AI, particularly for mathematical equations, diagrams, and scientific notations. Existing visual question answering (VQA) benchmarks focus on printed or structured handwritten text, limiting generalization to real-world note-taking. To address this, we introduce NoTeS-Bank, an evaluation benchmark for Neural Transcription and Search in note-based question answering. NoTeS-Bank comprises complex notes across multiple domains, requiring models to process unstructured and multimodal content. The benchmark defines two tasks: (1) Evidence-Based VQA, where models retrieve localized answers with bounding-box evidence, and (2) Open-Domain VQA, where models classify the domain before retrieving relevant documents and answers. Unlike classical Document VQA datasets relying on optical character recognition (OCR) and structured data, NoTeS-BANK demands vision-language fusion, retrieval, and multimodal reasoning. We benchmark state-of-the-art Vision-Language Models (VLMs) and retrieval frameworks, exposing structured transcription and reasoning limitations. NoTeS-Bank provides a rigorous evaluation with NDCG@5, MRR, Recall@K, IoU, and ANLS, establishing a new standard for visual document understanding and reasoning.
Advancing Question Answering on Handwritten Documents: A State-of-the-Art Recognition-Based Model for HW-SQuAD
Jun 25, 2024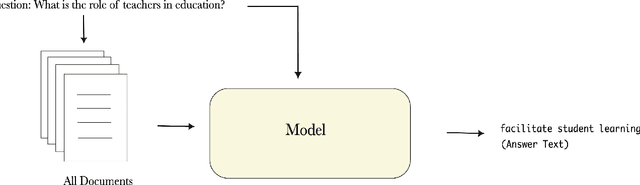
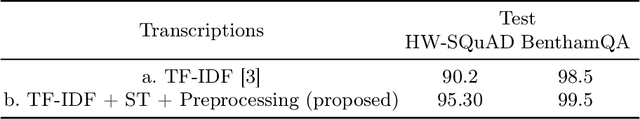
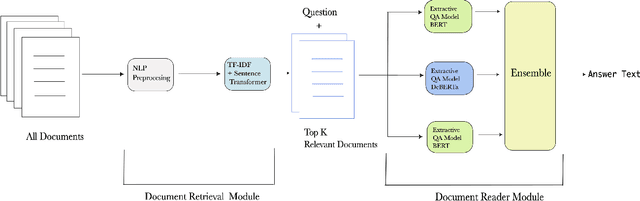

Question-answering handwritten documents is a challenging task with numerous real-world applications. This paper proposes a novel recognition-based approach that improves upon the previous state-of-the-art on the HW-SQuAD and BenthamQA datasets. Our model incorporates transformer-based document retrieval and ensemble methods at the model level, achieving an Exact Match score of 82.02% and 92.55% in HW-SQuAD and BenthamQA datasets, respectively, surpassing the previous best recognition-based approach by 10.89% and 26%. We also enhance the document retrieval component, boosting the top-5 retrieval accuracy from 90% to 95.30%. Our results demonstrate the significance of our proposed approach in advancing question answering on handwritten documents. The code and trained models will be publicly available to facilitate future research in this critical area of natural language.
DenseBAM-GI: Attention Augmented DeneseNet with momentum aided GRU for HMER
Jun 28, 2023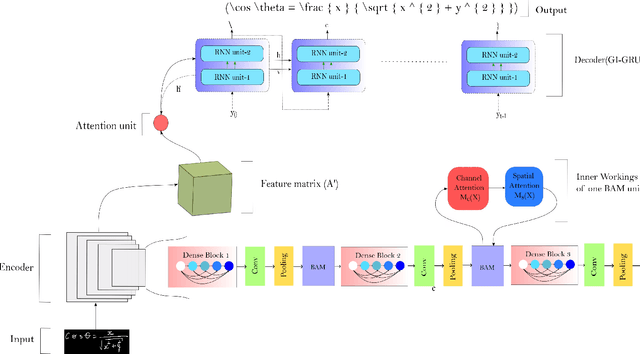
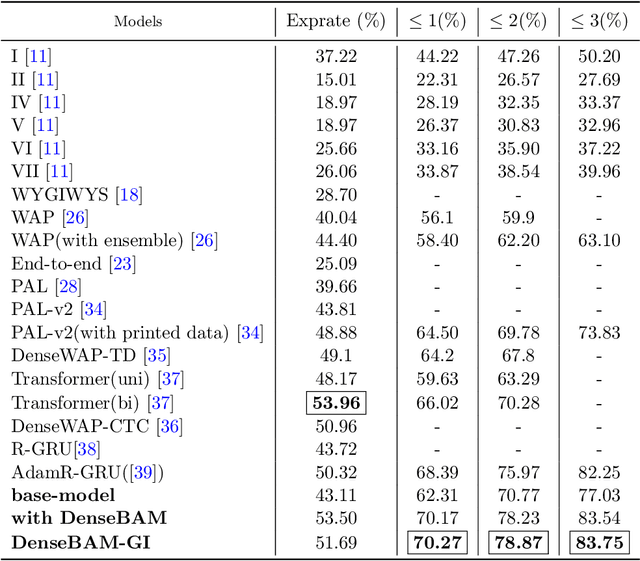
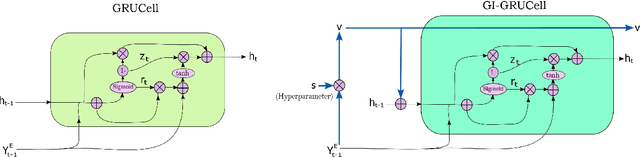
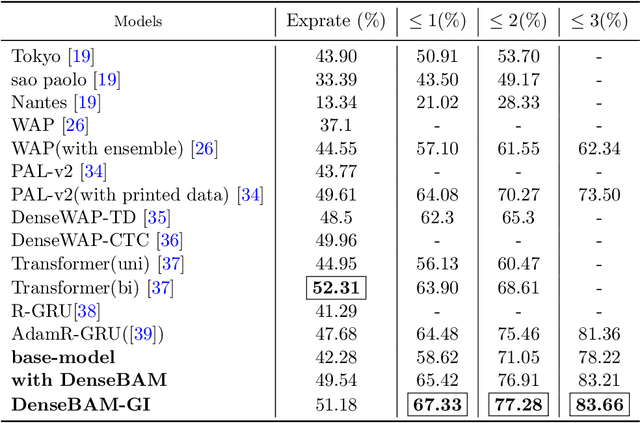
The task of recognising Handwritten Mathematical Expressions (HMER) is crucial in the fields of digital education and scholarly research. However, it is difficult to accurately determine the length and complex spatial relationships among symbols in handwritten mathematical expressions. In this study, we present a novel encoder-decoder architecture (DenseBAM-GI) for HMER, where the encoder has a Bottleneck Attention Module (BAM) to improve feature representation and the decoder has a Gated Input-GRU (GI-GRU) unit with an extra gate to make decoding long and complex expressions easier. The proposed model is an efficient and lightweight architecture with performance equivalent to state-of-the-art models in terms of Expression Recognition Rate (exprate). It also performs better in terms of top 1, 2, and 3 error accuracy across the CROHME 2014, 2016, and 2019 datasets. DenseBAM-GI achieves the best exprate among all models on the CROHME 2019 dataset. Importantly, these successes are accomplished with a drop in the complexity of the calculation and a reduction in the need for GPU memory.