 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoTeS-Bank: Benchmarking Neural Transcription and Search for Scientific Notes Understanding
Apr 12, 2025Understanding and reasoning over academic handwritten notes remains a challenge in document AI, particularly for mathematical equations, diagrams, and scientific notations. Existing visual question answering (VQA) benchmarks focus on printed or structured handwritten text, limiting generalization to real-world note-taking. To address this, we introduce NoTeS-Bank, an evaluation benchmark for Neural Transcription and Search in note-based question answering. NoTeS-Bank comprises complex notes across multiple domains, requiring models to process unstructured and multimodal content. The benchmark defines two tasks: (1) Evidence-Based VQA, where models retrieve localized answers with bounding-box evidence, and (2) Open-Domain VQA, where models classify the domain before retrieving relevant documents and answers. Unlike classical Document VQA datasets relying on optical character recognition (OCR) and structured data, NoTeS-BANK demands vision-language fusion, retrieval, and multimodal reasoning. We benchmark state-of-the-art Vision-Language Models (VLMs) and retrieval frameworks, exposing structured transcription and reasoning limitations. NoTeS-Bank provides a rigorous evaluation with NDCG@5, MRR, Recall@K, IoU, and ANLS, establishing a new standard for visual document understanding and reasoning.
Automatic Detection of COVID-19 from Chest X-ray Images Using Deep Learning Model
Aug 27, 2024The infectious disease caused by novel corona virus (2019-nCoV) has been widely spreading since last year and has shaken the entire world. It has caused an unprecedented effect on daily life, global economy and public health. Hence this disease detection has life-saving importance for both patients as well as doctors. Due to limited test kits, it is also a daunting task to test every patient with severe respiratory problems using conventional techniques (RT-PCR). Thus implementing an automatic diagnosis system is urgently required to overcome the scarcity problem of Covid-19 test kits at hospital, health care systems. The diagnostic approach is mainly classified into two categories-laboratory based and Chest radiography approach. In this paper, a novel approach for computerized corona virus (2019-nCoV) detection from lung x-ray images is presented. Here, we propose models using deep learning to show the effectiveness of diagnostic systems. In the experimental result, we evaluate proposed models on publicly available data-set which exhibit satisfactory performance and promising results compared with other previous existing methods.
FastTextSpotter: A High-Efficiency Transformer for Multilingual Scene Text Spotting
Aug 27, 2024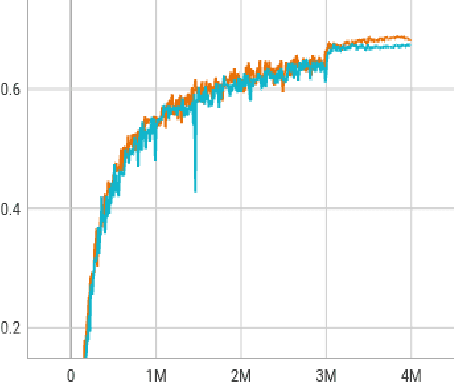
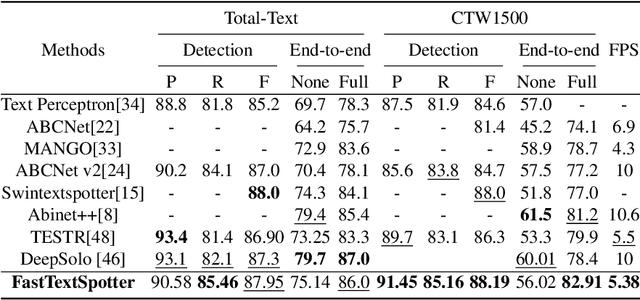
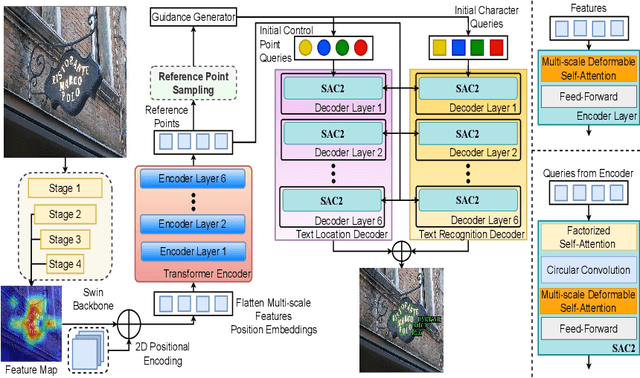
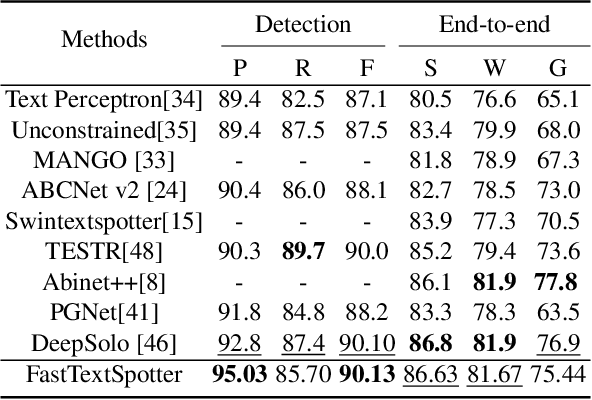
The proliferation of scene text in both structured and unstructured environments presents significant challenges in optical character recognition (OCR), necessitating more efficient and robust text spotting solutions. This paper presents FastTextSpotter, a framework that integrates a Swin Transformer visual backbone with a Transformer Encoder-Decoder architecture, enhanced by a novel, faster self-attention unit, SAC2, to improve processing speeds while maintaining accuracy. FastTextSpotter has been validated across multiple datasets, including ICDAR2015 for regular texts and CTW1500 and TotalText for arbitrary-shaped texts, benchmarking against current state-of-the-art models. Our results indicate that FastTextSpotter not only achieves superior accuracy in detecting and recognizing multilingual scene text (English and Vietnamese) but also improves model efficiency, thereby setting new benchmarks in the field. This study underscores the potential of advanced transformer architectures in improving the adaptability and speed of text spotting applications in diverse real-world settings. The dataset, code, and pre-trained models have been released in our Github.
Diving into the Depths of Spotting Text in Multi-Domain Noisy Scenes
Oct 06, 2023When used in a real-world noisy environment, the capacity to generalize to multiple domains is essential for any autonomous scene text spotting system. However, existing state-of-the-art methods employ pretraining and fine-tuning strategies on natural scene datasets, which do not exploit the feature interaction across other complex domains. In this work, we explore and investigate the problem of domain-agnostic scene text spotting, i.e., training a model on multi-domain source data such that it can directly generalize to target domains rather than being specialized for a specific domain or scenario. In this regard, we present the community a text spotting validation benchmark called Under-Water Text (UWT) for noisy underwater scenes to establish an important case study. Moreover, we also design an efficient super-resolution based end-to-end transformer baseline called DA-TextSpotter which achieves comparable or superior performance over existing text spotting architectures for both regular and arbitrary-shaped scene text spotting benchmarks in terms of both accuracy and model efficiency. The dataset, code and pre-trained models will be released upon acceptance.
Harnessing the Power of Multi-Lingual Datasets for Pre-training: Towards Enhancing Text Spotting Performance
Oct 06, 2023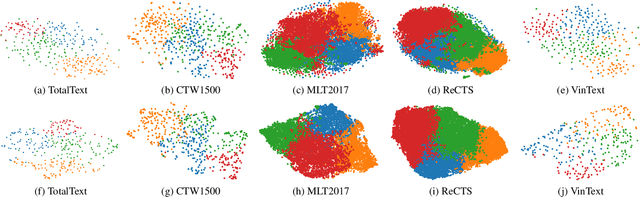



The adaptation capability to a wide range of domains is crucial for scene text spotting models when deployed to real-world conditions. However, existing state-of-the-art (SOTA) approaches usually incorporate scene text detection and recognition simply by pretraining on natural scene text datasets, which do not directly exploit the intermediate feature representations between multiple domains. Here, we investigate the problem of domain-adaptive scene text spotting, i.e., training a model on multi-domain source data such that it can directly adapt to target domains rather than being specialized for a specific domain or scenario. Further, we investigate a transformer baseline called Swin-TESTR to focus on solving scene-text spotting for both regular and arbitrary-shaped scene text along with an exhaustive evaluation. The results clearly demonstrate the potential of intermediate representations to achieve significant performance on text spotting benchmarks across multiple domains (e.g. language, synth-to-real, and documents). both in terms of accuracy and efficiency.
FAST: Font-Agnostic Scene Text Editing
Aug 05, 2023

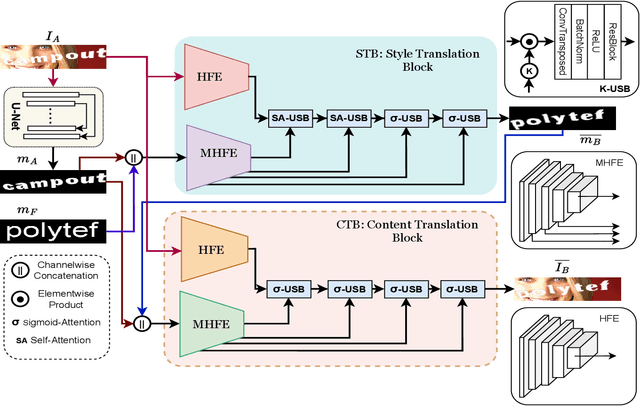
Scene Text Editing (STE) is a challenging research problem, and it aims to modify existing texts in an image while preserving the background and the font style of the original text of the image. Due to its various real-life applications, researchers have explored several approaches toward STE in recent years. However, most of the existing STE methods show inferior editing performance because of (1) complex image backgrounds, (2) various font styles, and (3) varying word lengths within the text. To address such inferior editing performance issues, in this paper, we propose a novel font-agnostic scene text editing framework, named FAST, for simultaneously generating text in arbitrary styles and locations while preserving a natural and realistic appearance through combined mask generation and style transfer. The proposed approach differs from the existing methods as they directly modify all image pixels. Instead, the proposed method has introduced a filtering mechanism to remove background distractions, allowing the network to focus solely on the text regions where editing is required. Additionally, a text-style transfer module has been designed to mitigate the challenges posed by varying word lengths. Extensive experiments and ablations have been conducted, and the results demonstrate that the proposed method outperforms the existing methods both qualitatively and quantitatively.