 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Mutual Cross-Modal Attention for Context-Aware Human Affordance Generation
Feb 19, 2025



Human affordance learning investigates contextually relevant novel pose prediction such that the estimated pose represents a valid human action within the scene. While the task is fundamental to machine perception and automated interactive navigation agents, the exponentially large number of probable pose and action variations make the problem challenging and non-trivial. However, the existing datasets and methods for human affordance prediction in 2D scenes are significantly limited in the literature. In this paper, we propose a novel cross-attention mechanism to encode the scene context for affordance prediction by mutually attending spatial feature maps from two different modalities. The proposed method is disentangled among individual subtasks to efficiently reduce the problem complexity. First, we sample a probable location for a person within the scene using a variational autoencoder (VAE) conditioned on the global scene context encoding. Next, we predict a potential pose template from a set of existing human pose candidates using a classifier on the local context encoding around the predicted location. In the subsequent steps, we use two VAEs to sample the scale and deformation parameters for the predicted pose template by conditioning on the local context and template class. Our experiments show significant improvements over the previous baseline of human affordance injection into complex 2D scenes.
d-Sketch: Improving Visual Fidelity of Sketch-to-Image Translation with Pretrained Latent Diffusion Models without Retraining
Feb 19, 2025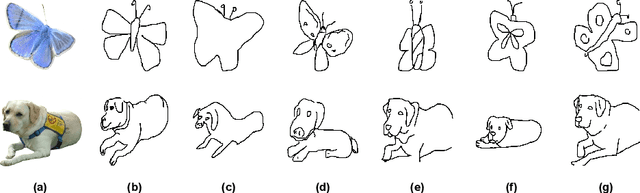
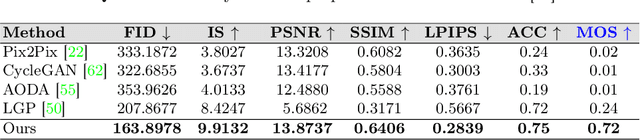

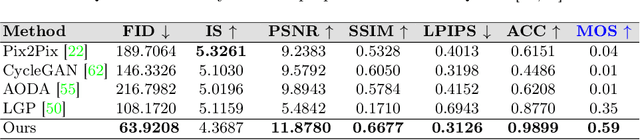
Structural guidance in an image-to-image translation allows intricate control over the shapes of synthesized images. Generating high-quality realistic images from user-specified rough hand-drawn sketches is one such task that aims to impose a structural constraint on the conditional generation process. While the premise is intriguing for numerous use cases of content creation and academic research, the problem becomes fundamentally challenging due to substantial ambiguities in freehand sketches. Furthermore, balancing the trade-off between shape consistency and realistic generation contributes to additional complexity in the process. Existing approaches based on Generative Adversarial Networks (GANs) generally utilize conditional GANs or GAN inversions, often requiring application-specific data and optimization objectives. The recent introduction of Denoising Diffusion Probabilistic Models (DDPMs) achieves a generational leap for low-level visual attributes in general image synthesis. However, directly retraining a large-scale diffusion model on a domain-specific subtask is often extremely difficult due to demanding computation costs and insufficient data. In this paper, we introduce a technique for sketch-to-image translation by exploiting the feature generalization capabilities of a large-scale diffusion model without retraining. In particular, we use a learnable lightweight mapping network to achieve latent feature translation from source to target domain. Experimental results demonstrate that the proposed method outperforms the existing techniques in qualitative and quantitative benchmarks, allowing high-resolution realistic image synthesis from rough hand-drawn sketches.
FAST: Font-Agnostic Scene Text Editing
Aug 05, 2023

Scene Text Editing (STE) is a challenging research problem, and it aims to modify existing texts in an image while preserving the background and the font style of the original text of the image. Due to its various real-life applications, researchers have explored several approaches toward STE in recent years. However, most of the existing STE methods show inferior editing performance because of (1) complex image backgrounds, (2) various font styles, and (3) varying word lengths within the text. To address such inferior editing performance issues, in this paper, we propose a novel font-agnostic scene text editing framework, named FAST, for simultaneously generating text in arbitrary styles and locations while preserving a natural and realistic appearance through combined mask generation and style transfer. The proposed approach differs from the existing methods as they directly modify all image pixels. Instead, the proposed method has introduced a filtering mechanism to remove background distractions, allowing the network to focus solely on the text regions where editing is required. Additionally, a text-style transfer module has been designed to mitigate the challenges posed by varying word lengths. Extensive experiments and ablations have been conducted, and the results demonstrate that the proposed method outperforms the existing methods both qualitatively and quantitatively.
MMC: Multi-Modal Colorization of Images using Textual Descriptions
Apr 25, 2023Handling various objects with different colors is a significant challenge for image colorization techniques. Thus, for complex real-world scenes, the existing image colorization algorithms often fail to maintain color consistency. In this work, we attempt to integrate textual descriptions as an auxiliary condition, along with the grayscale image that is to be colorized, to improve the fidelity of the colorization process. To do so, we have proposed a deep network that takes two inputs (grayscale image and the respective encoded text description) and tries to predict the relevant color components. Also, we have predicted each object in the image and have colorized them with their individual description to incorporate their specific attributes in the colorization process. After that, a fusion model fuses all the image objects (segments) to generate the final colorized image. As the respective textual descriptions contain color information of the objects present in the image, text encoding helps to improve the overall quality of predicted colors. In terms of performance, the proposed method outperforms existing colorization techniques in terms of LPIPS, PSNR and SSIM metrics.
A CNN Based Framework for Unistroke Numeral Recognition in Air-Writing
Mar 14, 2023Air-writing refers to virtually writing linguistic characters through hand gestures in three-dimensional space with six degrees of freedom. This paper proposes a generic video camera-aided convolutional neural network (CNN) based air-writing framework. Gestures are performed using a marker of fixed color in front of a generic video camera, followed by color-based segmentation to identify the marker and track the trajectory of the marker tip. A pre-trained CNN is then used to classify the gesture. The recognition accuracy is further improved using transfer learning with the newly acquired data. The performance of the system varies significantly on the illumination condition due to color-based segmentation. In a less fluctuating illumination condition, the system is able to recognize isolated unistroke numerals of multiple languages. The proposed framework has achieved 97.7%, 95.4% and 93.7% recognition rates in person independent evaluations on English, Bengali and Devanagari numerals, respectively.
Global Context-Aware Person Image Generation
Feb 28, 2023We propose a data-driven approach for context-aware person image generation. Specifically, we attempt to generate a person image such that the synthesized instance can blend into a complex scene. In our method, the position, scale, and appearance of the generated person are semantically conditioned on the existing persons in the scene. The proposed technique is divided into three sequential steps. At first, we employ a Pix2PixHD model to infer a coarse semantic mask that represents the new person's spatial location, scale, and potential pose. Next, we use a data-centric approach to select the closest representation from a precomputed cluster of fine semantic masks. Finally, we adopt a multi-scale, attention-guided architecture to transfer the appearance attributes from an exemplar image. The proposed strategy enables us to synthesize semantically coherent realistic persons that can blend into an existing scene without altering the global context. We conclude our findings with relevant qualitative and quantitative evaluations.
TIC: Text-Guided Image Colorization
Aug 04, 2022

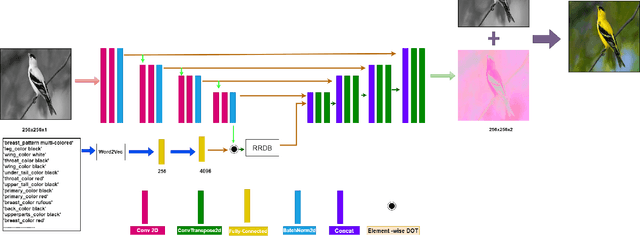
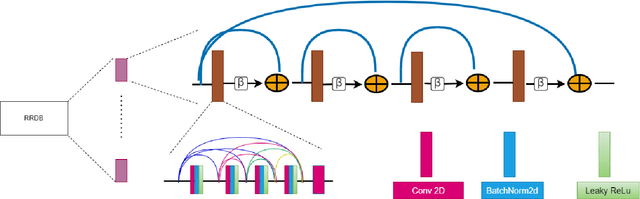
Image colorization is a well-known problem in computer vision. However, due to the ill-posed nature of the task, image colorization is inherently challenging. Though several attempts have been made by researchers to make the colorization pipeline automatic, these processes often produce unrealistic results due to a lack of conditioning. In this work, we attempt to integrate textual descriptions as an auxiliary condition, along with the grayscale image that is to be colorized, to improve the fidelity of the colorization process. To the best of our knowledge, this is one of the first attempts to incorporate textual conditioning in the colorization pipeline. To do so, we have proposed a novel deep network that takes two inputs (the grayscale image and the respective encoded text description) and tries to predict the relevant color gamut. As the respective textual descriptions contain color information of the objects present in the scene, the text encoding helps to improve the overall quality of the predicted colors. We have evaluated our proposed model using different metrics and found that it outperforms the state-of-the-art colorization algorithms both qualitatively and quantitatively.
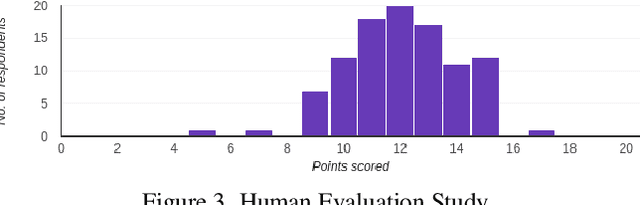
TIPS: Text-Induced Pose Synthesis
Jul 24, 2022
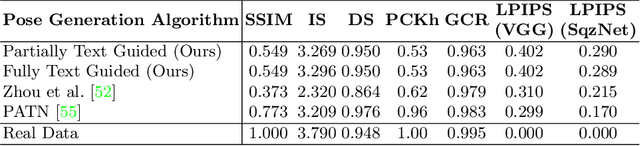
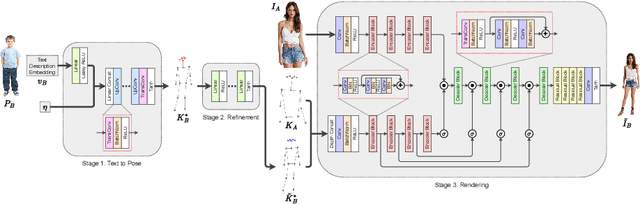
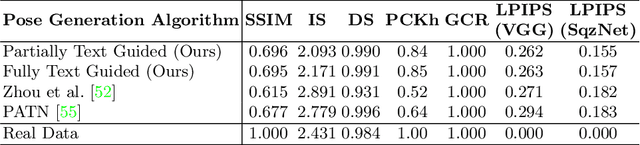
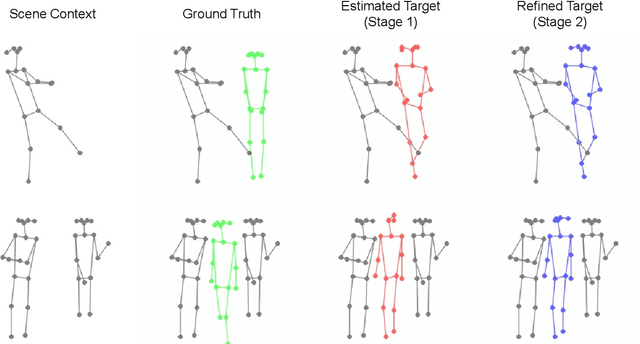
In computer vision, human pose synthesis and transfer deal with probabilistic image generation of a person in a previously unseen pose from an already available observation of that person. Though researchers have recently proposed several methods to achieve this task, most of these techniques derive the target pose directly from the desired target image on a specific dataset, making the underlying process challenging to apply in real-world scenarios as the generation of the target image is the actual aim. In this paper, we first present the shortcomings of current pose transfer algorithms and then propose a novel text-based pose transfer technique to address those issues. We divide the problem into three independent stages: (a) text to pose representation, (b) pose refinement, and (c) pose rendering. To the best of our knowledge, this is one of the first attempts to develop a text-based pose transfer framework where we also introduce a new dataset DF-PASS, by adding descriptive pose annotations for the images of the DeepFashion dataset. The proposed method generates promising results with significant qualitative and quantitative scores in our experiments.
Scene Aware Person Image Generation through Global Contextual Conditioning
Jun 06, 2022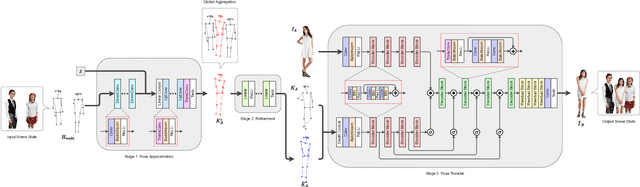


Person image generation is an intriguing yet challenging problem. However, this task becomes even more difficult under constrained situations. In this work, we propose a novel pipeline to generate and insert contextually relevant person images into an existing scene while preserving the global semantics. More specifically, we aim to insert a person such that the location, pose, and scale of the person being inserted blends in with the existing persons in the scene. Our method uses three individual networks in a sequential pipeline. At first, we predict the potential location and the skeletal structure of the new person by conditioning a Wasserstein Generative Adversarial Network (WGAN) on the existing human skeletons present in the scene. Next, the predicted skeleton is refined through a shallow linear network to achieve higher structural accuracy in the generated image. Finally, the target image is generated from the refined skeleton using another generative network conditioned on a given image of the target person. In our experiments, we achieve high-resolution photo-realistic generation results while preserving the general context of the scene. We conclude our paper with multiple qualitative and quantitative benchmarks on the results.
Multi-scale Attention Guided Pose Transfer
Feb 14, 2022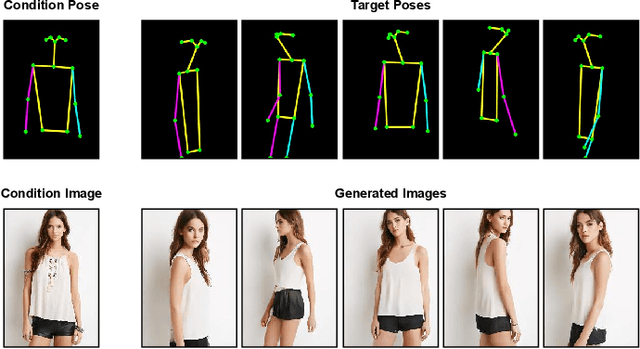
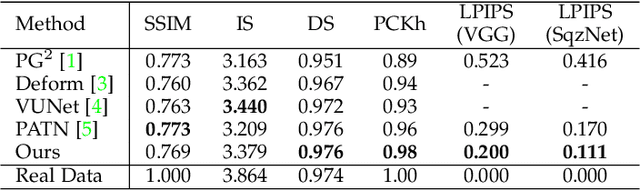
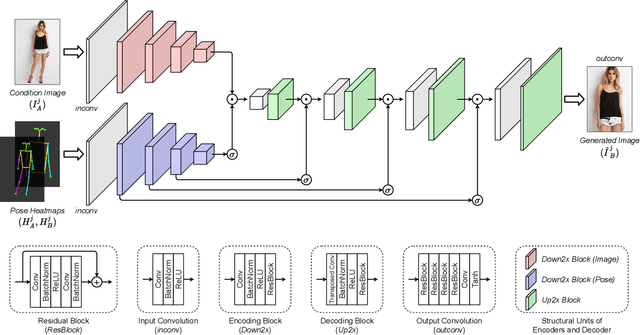
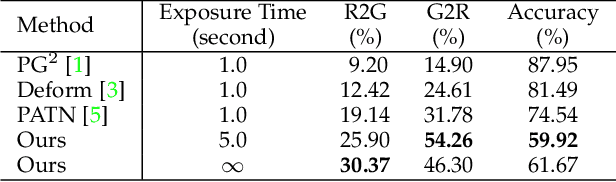
Pose transfer refers to the probabilistic image generation of a person with a previously unseen novel pose from another image of that person having a different pose. Due to potential academic and commercial applications, this problem is extensively studied in recent years. Among the various approaches to the problem, attention guided progressive generation is shown to produce state-of-the-art results in most cases. In this paper, we present an improved network architecture for pose transfer by introducing attention links at every resolution level of the encoder and decoder. By utilizing such dense multi-scale attention guided approach, we are able to achieve significant improvement over the existing methods both visually and analytically. We conclude our findings with extensive qualitative and quantitative comparisons against several existing methods on the DeepFashion dataset.