 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDRG-Font: Dynamic Reference-Guided Few-shot Font Generation via Contrastive Style-Content Disentanglement
Apr 15, 2026Few-shot Font Generation aims to generate stylistically consistent glyphs from a few reference glyphs. However, capturing complex font styles from a few exemplars remains challenging, and the existing methods often struggle to retain discernible local characteristics in generated samples. This paper introduces DRG-Font, a contrastive font generation strategy that learns complex glyph attributes by decomposing style and content embedding spaces. For optimal style supervision, the proposed architecture incorporates a Reference Selection (RS) Module to dynamically select the best style reference from an available pool of candidates. The network learns to decompose glyph attributes into style and shape priors through a Multi-scale Style Head Block (MSHB) and a Multi-scale Content Head Block (MCHB). For style adaptation, a Multi-Fusion Upsampling Block (MFUB) produces the target glyph by combining the reference style prior and target content prior. The proposed method demonstrates significant improvements over state-of-the-art approaches across multiple visual and analytical benchmarks.
DocRevive: A Unified Pipeline for Document Text Restoration
Apr 11, 2026In Document Understanding, the challenge of reconstructing damaged, occluded, or incomplete text remains a critical yet unexplored problem. Subsequent document understanding tasks can benefit from a document reconstruction process. In response, this paper presents a novel unified pipeline combining state-of-the-art Optical Character Recognition (OCR), advanced image analysis, masked language modeling, and diffusion-based models to restore and reconstruct text while preserving visual integrity. We create a synthetic dataset of 30{,}078 degraded document images that simulates diverse document degradation scenarios, setting a benchmark for restoration tasks. Our pipeline detects and recognizes text, identifies degradation with an occlusion detector, and uses an inpainting model for semantically coherent reconstruction. A diffusion-based module seamlessly reintegrates text, matching font, size, and alignment. To evaluate restoration quality, we propose a Unified Context Similarity Metric (UCSM), incorporating edit, semantic, and length similarities with a contextual predictability measure that penalizes deviations when the correct text is contextually obvious. Our work advances document restoration, benefiting archival research and digital preservation while setting a new standard for text reconstruction. The OPRB dataset and code are available at \href{https://huggingface.co/datasets/kpurkayastha/OPRB}{Hugging Face} and \href{https://github.com/kunalpurkayastha/DocRevive}{Github} respectively.
Reliability-Aware Weighted Multi-Scale Spatio-Temporal Maps for Heart Rate Monitoring
Mar 27, 2026Remote photoplethysmography (rPPG) allows for the contactless estimation of physiological signals from facial videos by analyzing subtle skin color changes. However, rPPG signals are extremely susceptible to illumination changes, motion, shadows, and specular reflections, resulting in low-quality signals in unconstrained environments. To overcome these issues, we present a Reliability-Aware Weighted Multi-Scale Spatio-Temporal (WMST) map that models pixel reliability through the suppression of environmental noises. These noises are modeled using different weighting strategies to focus on more physiologically valid areas. Leveraging the WMST map, we develop an SSL contrastive learning approach based on Swin-Unet, where positive pairs are generated from conventional rPPG signals and temporally expanded WMST maps. Moreover, we introduce a new High-High-High (HHH) wavelet map as a negative example that maintains motion and structural details while filtering out physiological information. Here, our aim is to estimate heart rate (HR), and the experiments on public rPPG benchmarks show that our approach enhances motion and illumination robustness with lower HR estimation error and higher Pearson correlation than existing Self-Supervised Learning (SSL) based rPPG methods.
Towards Robust Cross-Dataset Object Detection Generalization under Domain Specificity
Jan 14, 2026Object detectors often perform well in-distribution, yet degrade sharply on a different benchmark. We study cross-dataset object detection (CD-OD) through a lens of setting specificity. We group benchmarks into setting-agnostic datasets with diverse everyday scenes and setting-specific datasets tied to a narrow environment, and evaluate a standard detector family across all train--test pairs. This reveals a clear structure in CD-OD: transfer within the same setting type is relatively stable, while transfer across setting types drops substantially and is often asymmetric. The most severe breakdowns occur when transferring from specific sources to agnostic targets, and persist after open-label alignment, indicating that domain shift dominates in the hardest regimes. To disentangle domain shift from label mismatch, we compare closed-label transfer with an open-label protocol that maps predicted classes to the nearest target label using CLIP similarity. Open-label evaluation yields consistent but bounded gains, and many corrected cases correspond to semantic near-misses supported by the image evidence. Overall, we provide a principled characterization of CD-OD under setting specificity and practical guidance for evaluating detectors under distribution shift. Code will be released at \href{[https://github.com/Ritabrata04/cdod-icpr.git}{https://github.com/Ritabrata04/cdod-icpr}.
TaleDiffusion: Multi-Character Story Generation with Dialogue Rendering
Sep 04, 2025Text-to-story visualization is challenging due to the need for consistent interaction among multiple characters across frames. Existing methods struggle with character consistency, leading to artifact generation and inaccurate dialogue rendering, which results in disjointed storytelling. In response, we introduce TaleDiffusion, a novel framework for generating multi-character stories with an iterative process, maintaining character consistency, and accurate dialogue assignment via postprocessing. Given a story, we use a pre-trained LLM to generate per-frame descriptions, character details, and dialogues via in-context learning, followed by a bounded attention-based per-box mask technique to control character interactions and minimize artifacts. We then apply an identity-consistent self-attention mechanism to ensure character consistency across frames and region-aware cross-attention for precise object placement. Dialogues are also rendered as bubbles and assigned to characters via CLIPSeg. Experimental results demonstrate that TaleDiffusion outperforms existing methods in consistency, noise reduction, and dialogue rendering.
Conformal uncertainty quantification to evaluate predictive fairness of foundation AI model for skin lesion classes across patient demographics
Mar 31, 2025


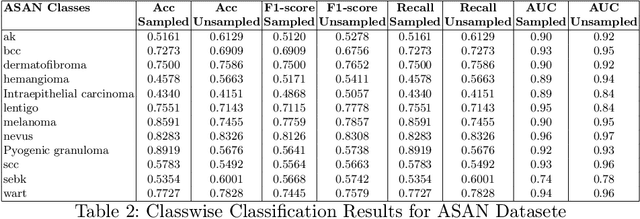
Deep learning based diagnostic AI systems based on medical images are starting to provide similar performance as human experts. However these data hungry complex systems are inherently black boxes and therefore slow to be adopted for high risk applications like healthcare. This problem of lack of transparency is exacerbated in the case of recent large foundation models, which are trained in a self supervised manner on millions of data points to provide robust generalisation across a range of downstream tasks, but the embeddings generated from them happen through a process that is not interpretable, and hence not easily trustable for clinical applications. To address this timely issue, we deploy conformal analysis to quantify the predictive uncertainty of a vision transformer (ViT) based foundation model across patient demographics with respect to sex, age and ethnicity for the tasks of skin lesion classification using several public benchmark datasets. The significant advantage of this method is that conformal analysis is method independent and it not only provides a coverage guarantee at population level but also provides an uncertainty score for each individual. We used a model-agnostic dynamic F1-score-based sampling during model training, which helped to stabilize the class imbalance and we investigate the effects on uncertainty quantification (UQ) with or without this bias mitigation step. Thus we show how this can be used as a fairness metric to evaluate the robustness of the feature embeddings of the foundation model (Google DermFoundation) and thus advance the trustworthiness and fairness of clinical AI.
A Context-Driven Training-Free Network for Lightweight Scene Text Segmentation and Recognition
Mar 19, 2025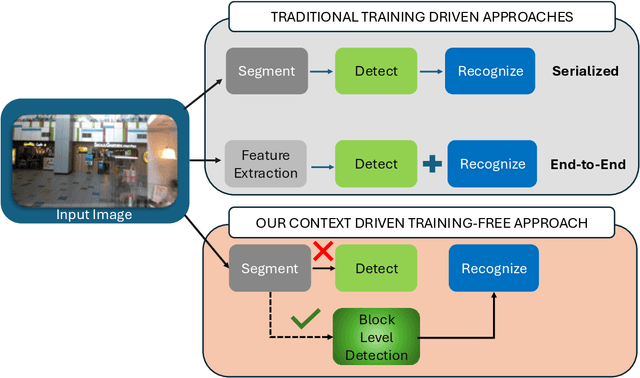

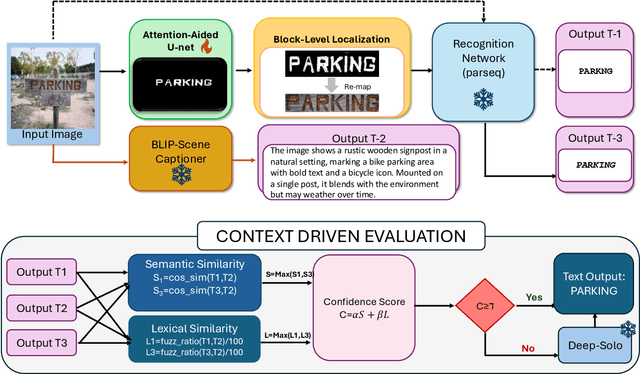

Modern scene text recognition systems often depend on large end-to-end architectures that require extensive training and are prohibitively expensive for real-time scenarios. In such cases, the deployment of heavy models becomes impractical due to constraints on memory, computational resources, and latency. To address these challenges, we propose a novel, training-free plug-and-play framework that leverages the strengths of pre-trained text recognizers while minimizing redundant computations. Our approach uses context-based understanding and introduces an attention-based segmentation stage, which refines candidate text regions at the pixel level, improving downstream recognition. Instead of performing traditional text detection that follows a block-level comparison between feature map and source image and harnesses contextual information using pretrained captioners, allowing the framework to generate word predictions directly from scene context.Candidate texts are semantically and lexically evaluated to get a final score. Predictions that meet or exceed a pre-defined confidence threshold bypass the heavier process of end-to-end text STR profiling, ensuring faster inference and cutting down on unnecessary computations. Experiments on public benchmarks demonstrate that our paradigm achieves performance on par with state-of-the-art systems, yet requires substantially fewer resources.
d-Sketch: Improving Visual Fidelity of Sketch-to-Image Translation with Pretrained Latent Diffusion Models without Retraining
Feb 19, 2025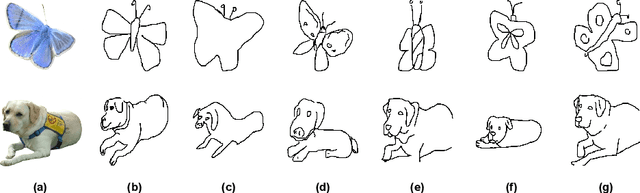
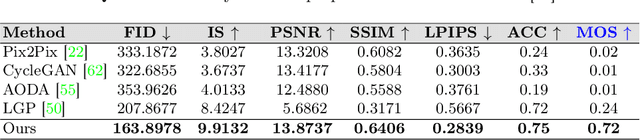

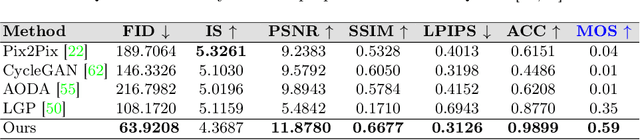
Structural guidance in an image-to-image translation allows intricate control over the shapes of synthesized images. Generating high-quality realistic images from user-specified rough hand-drawn sketches is one such task that aims to impose a structural constraint on the conditional generation process. While the premise is intriguing for numerous use cases of content creation and academic research, the problem becomes fundamentally challenging due to substantial ambiguities in freehand sketches. Furthermore, balancing the trade-off between shape consistency and realistic generation contributes to additional complexity in the process. Existing approaches based on Generative Adversarial Networks (GANs) generally utilize conditional GANs or GAN inversions, often requiring application-specific data and optimization objectives. The recent introduction of Denoising Diffusion Probabilistic Models (DDPMs) achieves a generational leap for low-level visual attributes in general image synthesis. However, directly retraining a large-scale diffusion model on a domain-specific subtask is often extremely difficult due to demanding computation costs and insufficient data. In this paper, we introduce a technique for sketch-to-image translation by exploiting the feature generalization capabilities of a large-scale diffusion model without retraining. In particular, we use a learnable lightweight mapping network to achieve latent feature translation from source to target domain. Experimental results demonstrate that the proposed method outperforms the existing techniques in qualitative and quantitative benchmarks, allowing high-resolution realistic image synthesis from rough hand-drawn sketches.
Exploring Mutual Cross-Modal Attention for Context-Aware Human Affordance Generation
Feb 19, 2025



Human affordance learning investigates contextually relevant novel pose prediction such that the estimated pose represents a valid human action within the scene. While the task is fundamental to machine perception and automated interactive navigation agents, the exponentially large number of probable pose and action variations make the problem challenging and non-trivial. However, the existing datasets and methods for human affordance prediction in 2D scenes are significantly limited in the literature. In this paper, we propose a novel cross-attention mechanism to encode the scene context for affordance prediction by mutually attending spatial feature maps from two different modalities. The proposed method is disentangled among individual subtasks to efficiently reduce the problem complexity. First, we sample a probable location for a person within the scene using a variational autoencoder (VAE) conditioned on the global scene context encoding. Next, we predict a potential pose template from a set of existing human pose candidates using a classifier on the local context encoding around the predicted location. In the subsequent steps, we use two VAEs to sample the scale and deformation parameters for the predicted pose template by conditioning on the local context and template class. Our experiments show significant improvements over the previous baseline of human affordance injection into complex 2D scenes.
Decorrelation-based Self-Supervised Visual Representation Learning for Writer Identification
Oct 02, 2024



Self-supervised learning has developed rapidly over the last decade and has been applied in many areas of computer vision. Decorrelation-based self-supervised pretraining has shown great promise among non-contrastive algorithms, yielding performance at par with supervised and contrastive self-supervised baselines. In this work, we explore the decorrelation-based paradigm of self-supervised learning and apply the same to learning disentangled stroke features for writer identification. Here we propose a modified formulation of the decorrelation-based framework named SWIS which was proposed for signature verification by standardizing the features along each dimension on top of the existing framework. We show that the proposed framework outperforms the contemporary self-supervised learning framework on the writer identification benchmark and also outperforms several supervised methods as well. To the best of our knowledge, this work is the first of its kind to apply self-supervised learning for learning representations for writer verification tasks.