 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeight-Decay Turns Transformer Loss Landscapes Villani: Functional-Analytic Foundations for Optimization and Generalization
May 07, 2026Weight decay is widely used as a regularizer in large language models, yet its precise role in shaping Transformer loss landscapes remains theoretically underexplored. This paper provides the first rigorous functional-analytic characterization of the standard Transformer objective--cross-entropy loss with $L^2$ regularization--by proving it satisfies Villani's criteria for coercive energy functions. Specifically, we show that the regularized loss $\mathcal{F}$ is infinitely differentiable, grows at least quadratically, has Gaussian-integrable tails, and satisfies the differential growth condition $-Δ\mathcal{F} + \tfrac{1}{s}\|\nabla\mathcal{F}\|^{2} \to \infty$ as $\|θ\| \to \infty$ for all $s>0$. From this structure, we derive explicit log-Sobolev and Poincaré constants $C_{\mathrm{LS}} \leq λ^{-1} + d/λ^{2}$, linking the regularization strength $λ$ and model dimension $d$ to finite-time convergence guarantees for noisy stochastic gradient descent and PAC-Bayesian generalization bounds that tighten with increasing $λ$. To validate our theory, we introduce a scalable Villani diagnostic $Ψ_s(θ) = -Δ\mathcal{F} + s^{-1}\|\nabla \mathcal{F}\|^2$ and estimate it efficiently using Hutchinson trace probes in models with over 100M parameters. Experiments on GPT-Neo-125M across Penn Treebank and WikiText-103 confirm the predicted quadratic growth of $Ψ_s$, spectral inflation of the Hessian, and exponential convergence behavior consistent with our log-Sobolev analysis. These results demonstrate that weight decay not only improves generalization empirically but also establishes the mathematical conditions required for fast Langevin mixing and theoretically grounded curvature-aware optimization in deep learning.
B-MoE: A Body-Part-Aware Mixture-of-Experts "All Parts Matter" Approach to Micro-Action Recognition
Mar 25, 2026Micro-actions, fleeting and low-amplitude motions, such as glances, nods, or minor posture shifts, carry rich social meaning but remain difficult for current action recognition models to recognize due to their subtlety, short duration, and high inter-class ambiguity. In this paper, we introduce B-MoE, a Body-part-aware Mixture-of-Experts framework designed to explicitly model the structured nature of human motion. In B-MoE, each expert specializes in a distinct body region (head, body, upper limbs, lower limbs), and is based on the lightweight Macro-Micro Motion Encoder (M3E) that captures long-range contextual structure and fine-grained local motion. A cross-attention routing mechanism learns inter-region relationships and dynamically selects the most informative regions for each micro-action. B-MoE uses a dual-stream encoder that fuses these region-specific semantic cues with global motion features to jointly capture spatially localized cues and temporally subtle variations that characterize micro-actions. Experiments on three challenging benchmarks (MA-52, SocialGesture, and MPII-GroupInteraction) show consistent state-of-theart gains, with improvements in ambiguous, underrepresented, and low amplitude classes.
A Backbone Benchmarking Study on Self-supervised Learning as a Auxiliary Task with Texture-based Local Descriptors for Face Analysis
Mar 23, 2026In this work, we benchmark with different backbones and study their impact for self-supervised learning (SSL) as an auxiliary task to blend texture-based local descriptors into feature modelling for efficient face analysis. It is established in previous work that combining a primary task and a self-supervised auxiliary task enables more robust and discriminative representation learning. We employed different shallow to deep backbones for the SSL task of Masked Auto-Encoder (MAE) as an auxiliary objective to reconstruct texture features such as local patterns alongside the primary task in local pattern SSAT (L-SSAT), ensuring robust and unbiased face analysis. To expand the benchmark, we conducted a comprehensive comparative analysis across multiple model configurations within the proposed framework. To this end, we address the three research questions: "What is the role of the backbone in performance L-SSAT?", "What type of backbone is effective for different face analysis tasks?", and "Is there any generalized backbone for effective face analysis with L-SSAT?". Towards answering these questions, we provide a detailed study and experiments. The performance evaluation demonstrates that the backbone for the proposed method is highly dependent on the downstream task, achieving average accuracies of 0.94 on FaceForensics++, 0.87 on CelebA, and 0.88 on AffectNet. For consistency of feature representation quality and generalisation capability across various face analysis paradigms, including face attribute prediction, emotion classification, and deepfake detection, there is no unified backbone.
DenVisCoM: Dense Vision Correspondence Mamba for Efficient and Real-time Optical Flow and Stereo Estimation
Feb 02, 2026In this work, we propose a novel Mamba block DenVisCoM, as well as a novel hybrid architecture specifically tailored for accurate and real-time estimation of optical flow and disparity estimation. Given that such multi-view geometry and motion tasks are fundamentally related, we propose a unified architecture to tackle them jointly. Specifically, the proposed hybrid architecture is based on DenVisCoM and a Transformer-based attention block that efficiently addresses real-time inference, memory footprint, and accuracy at the same time for joint estimation of motion and 3D dense perception tasks. We extensively analyze the benchmark trade-off of accuracy and real-time processing on a large number of datasets. Our experimental results and related analysis suggest that our proposed model can accurately estimate optical flow and disparity estimation in real time. All models and associated code are available at https://github.com/vimstereo/DenVisCoM.
Continual-learning for Modelling Low-Resource Languages from Large Language Models
Jan 09, 2026Modelling a language model for a multi-lingual scenario includes several potential challenges, among which catastrophic forgetting is the major challenge. For example, small language models (SLM) built for low-resource languages by adapting large language models (LLMs) pose the challenge of catastrophic forgetting. This work proposes to employ a continual learning strategy using parts-of-speech (POS)-based code-switching along with a replay adapter strategy to mitigate the identified gap of catastrophic forgetting while training SLM from LLM. Experiments conducted on vision language tasks such as visual question answering and language modelling task exhibits the success of the proposed architecture.
Investigating the Viability of Employing Multi-modal Large Language Models in the Context of Audio Deepfake Detection
Jan 02, 2026While Vision-Language Models (VLMs) and Multimodal Large Language Models (MLLMs) have shown strong generalisation in detecting image and video deepfakes, their use for audio deepfake detection remains largely unexplored. In this work, we aim to explore the potential of MLLMs for audio deepfake detection. Combining audio inputs with a range of text prompts as queries to find out the viability of MLLMs to learn robust representations across modalities for audio deepfake detection. Therefore, we attempt to explore text-aware and context-rich, question-answer based prompts with binary decisions. We hypothesise that such a feature-guided reasoning will help in facilitating deeper multimodal understanding and enable robust feature learning for audio deepfake detection. We evaluate the performance of two MLLMs, Qwen2-Audio-7B-Instruct and SALMONN, in two evaluation modes: (a) zero-shot and (b) fine-tuned. Our experiments demonstrate that combining audio with a multi-prompt approach could be a viable way forward for audio deepfake detection. Our experiments show that the models perform poorly without task-specific training and struggle to generalise to out-of-domain data. However, they achieve good performance on in-domain data with minimal supervision, indicating promising potential for audio deepfake detection.
Fusion-SSAT: Unleashing the Potential of Self-supervised Auxiliary Task by Feature Fusion for Generalized Deepfake Detection
Jan 02, 2026In this work, we attempted to unleash the potential of self-supervised learning as an auxiliary task that can optimise the primary task of generalised deepfake detection. To explore this, we examined different combinations of the training schemes for these tasks that can be most effective. Our findings reveal that fusing the feature representation from self-supervised auxiliary tasks is a powerful feature representation for the problem at hand. Such a representation can leverage the ultimate potential and bring in a unique representation of both the self-supervised and primary tasks, achieving better performance for the primary task. We experimented on a large set of datasets, which includes DF40, FaceForensics++, Celeb-DF, DFD, FaceShifter, UADFV, and our results showed better generalizability on cross-dataset evaluation when compared with current state-of-the-art detectors.
DensePercept-NCSSD: Vision Mamba towards Real-time Dense Visual Perception with Non-Causal State Space Duality
Nov 16, 2025In this work, we propose an accurate and real-time optical flow and disparity estimation model by fusing pairwise input images in the proposed non-causal selective state space for dense perception tasks. We propose a non-causal Mamba block-based model that is fast and efficient and aptly manages the constraints present in a real-time applications. Our proposed model reduces inference times while maintaining high accuracy and low GPU usage for optical flow and disparity map generation. The results and analysis, and validation in real-life scenario justify that our proposed model can be used for unified real-time and accurate 3D dense perception estimation tasks. The code, along with the models, can be found at https://github.com/vimstereo/DensePerceptNCSSD
Towards Obstacle-Avoiding Control of Planar Snake Robots Exploring Neuro-Evolution of Augmenting Topologies
Nov 15, 2025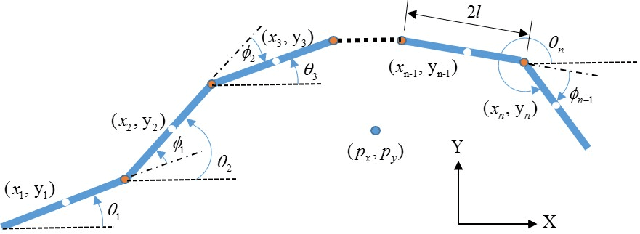
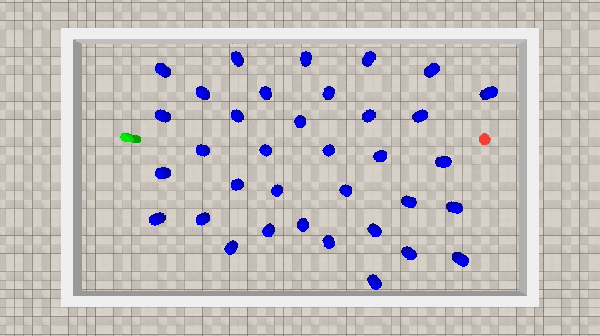
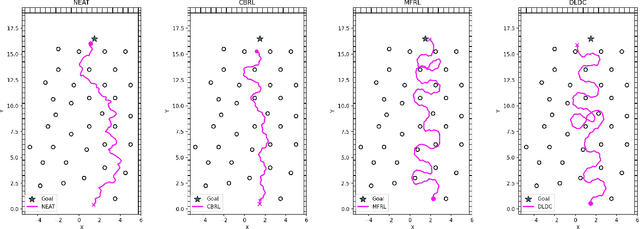
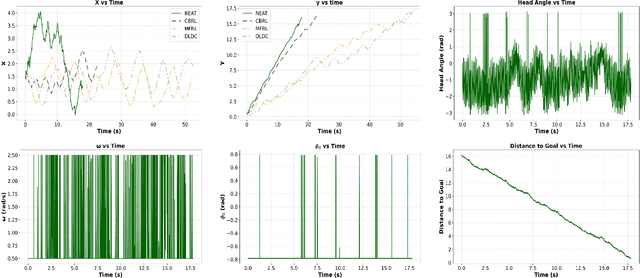
This work aims to develop a resource-efficient solution for obstacle-avoiding tracking control of a planar snake robot in a densely cluttered environment with obstacles. Particularly, Neuro-Evolution of Augmenting Topologies (NEAT) has been employed to generate dynamic gait parameters for the serpenoid gait function, which is implemented on the joint angles of the snake robot, thus controlling the robot on a desired dynamic path. NEAT is a single neural-network based evolutionary algorithm that is known to work extremely well when the input layer is of significantly higher dimension and the output layer is of a smaller size. For the planar snake robot, the input layer consists of the joint angles, link positions, head link position as well as obstacle positions in the vicinity. However, the output layer consists of only the frequency and offset angle of the serpenoid gait that control the speed and heading of the robot, respectively. Obstacle data from a LiDAR and the robot data from various sensors, along with the location of the end goal and time, are employed to parametrize a reward function that is maximized over iterations by selective propagation of superior neural networks. The implementation and experimental results showcase that the proposed approach is computationally efficient, especially for large environments with many obstacles. The proposed framework has been verified through a physics engine simulation study on PyBullet. The approach shows superior results to existing state-of-the-art methodologies and comparable results to the very recent CBRL approach with significantly lower computational overhead. The video of the simulation can be found here: https://sites.google.com/view/neatsnakerobot
Neuromorphic Readout for Hadron Calorimeters
Feb 18, 2025We simulate hadrons impinging on a homogeneous lead-tungstate (PbWO4) calorimeter to investigate how the resulting light yield and its temporal structure, as detected by an array of light-sensitive sensors, can be processed by a neuromorphic computing system. Our model encodes temporal photon distributions as spike trains and employs a fully connected spiking neural network to estimate the total deposited energy, as well as the position and spatial distribution of the light emissions within the sensitive material. The extracted primitives offer valuable topological information about the shower development in the material, achieved without requiring a segmentation of the active medium. A potential nanophotonic implementation using III-V semiconductor nanowires is discussed. It can be both fast and energy efficient.