 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuromorphic Readout for Hadron Calorimeters
Feb 18, 2025We simulate hadrons impinging on a homogeneous lead-tungstate (PbWO4) calorimeter to investigate how the resulting light yield and its temporal structure, as detected by an array of light-sensitive sensors, can be processed by a neuromorphic computing system. Our model encodes temporal photon distributions as spike trains and employs a fully connected spiking neural network to estimate the total deposited energy, as well as the position and spatial distribution of the light emissions within the sensitive material. The extracted primitives offer valuable topological information about the shower development in the material, achieved without requiring a segmentation of the active medium. A potential nanophotonic implementation using III-V semiconductor nanowires is discussed. It can be both fast and energy efficient.
An Adversarial Attack Analysis on Malicious Advertisement URL Detection Framework
Apr 27, 2022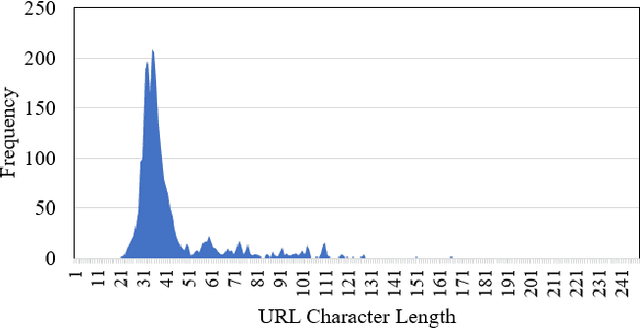
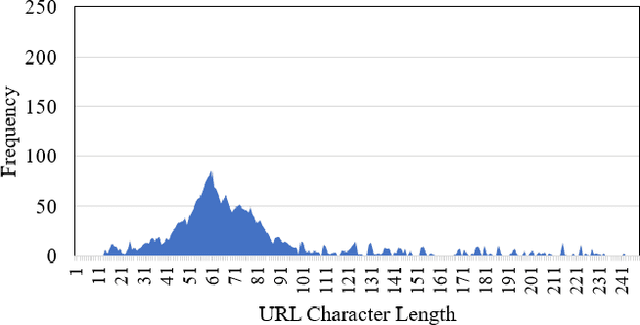
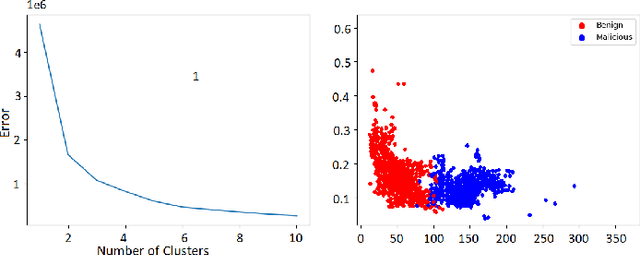
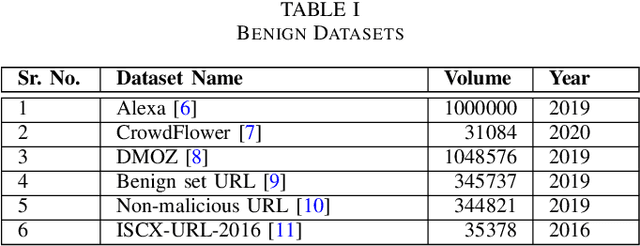
Malicious advertisement URLs pose a security risk since they are the source of cyber-attacks, and the need to address this issue is growing in both industry and academia. Generally, the attacker delivers an attack vector to the user by means of an email, an advertisement link or any other means of communication and directs them to a malicious website to steal sensitive information and to defraud them. Existing malicious URL detection techniques are limited and to handle unseen features as well as generalize to test data. In this study, we extract a novel set of lexical and web-scrapped features and employ machine learning technique to set up system for fraudulent advertisement URLs detection. The combination set of six different kinds of features precisely overcome the obfuscation in fraudulent URL classification. Based on different statistical properties, we use twelve different formatted datasets for detection, prediction and classification task. We extend our prediction analysis for mismatched and unlabelled datasets. For this framework, we analyze the performance of four machine learning techniques: Random Forest, Gradient Boost, XGBoost and AdaBoost in the detection part. With our proposed method, we can achieve a false negative rate as low as 0.0037 while maintaining high accuracy of 99.63%. Moreover, we devise a novel unsupervised technique for data clustering using K- Means algorithm for the visual analysis. This paper analyses the vulnerability of decision tree-based models using the limited knowledge attack scenario. We considered the exploratory attack and implemented Zeroth Order Optimization adversarial attack on the detection models.
Cross-Modal learning for Audio-Visual Video Parsing
Apr 03, 2021
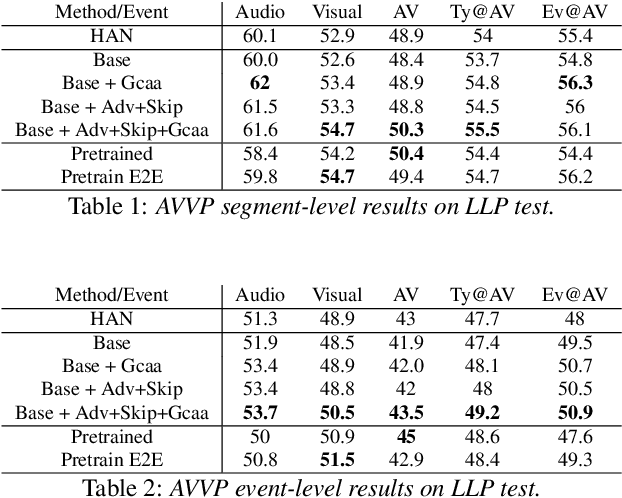
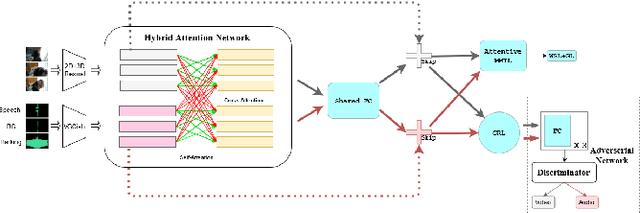

In this paper we present a novel approach to the Audio-visual video parsing task that takes into cognizance how event categories bind to audio and visual modalities. The proposed parsing approach simultaneously detects the temporal boundaries in terms of start and end times of such events. This task can be naturally formulated as a Multimodal Multiple Instance Learning (MMIL) problem. We show how the MMIL task can benefit from the following techniques geared toward self and cross modal learning: (i) self-supervised pre-training based on highly aligned task audio-video grounding, (ii) global context aware attention and (iii) adversarial training. As for pre-training, we boostrap on the Uniter (style) %\todo{add citation} transformer architecture using a self-supervised objective audio-video grounding over the relatively large AudioSet dataset. This pretrained model is fine-tuned on an architectural variant of the state-of-the-art Hybrid Attention Network (HAN) %\todo{Add citation} that uses global context aware attention and adversarial training objectives for audio visual video parsing. %Further, we use a hybrid attention network and adversarial training to improve self and cross modal learning. Attentive MMIL pooling method is leveraged to adaptively explore useful audio and visual signals from different temporal segments and modalities. We present extensive experimental evaluations on the Look, Listen, and Parse (LLP) dataset and compare it against HAN. We also present several ablation tests to validate the effect of pre-training, attention and adversarial training.
Rudder: A Cross Lingual Video and Text Retrieval Dataset
Mar 09, 2021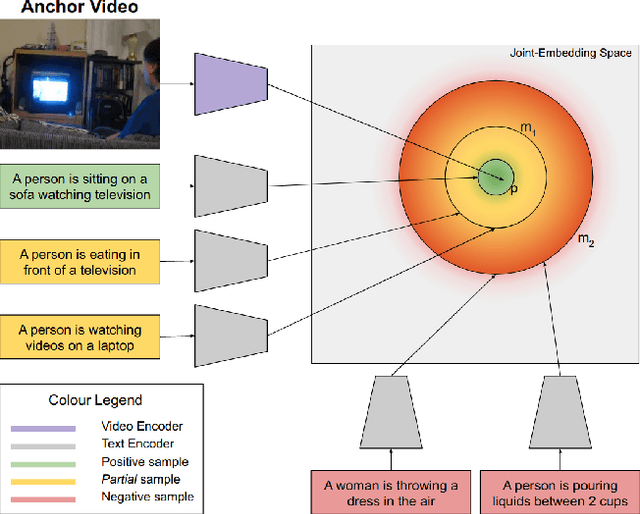
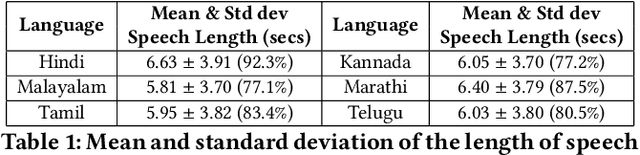
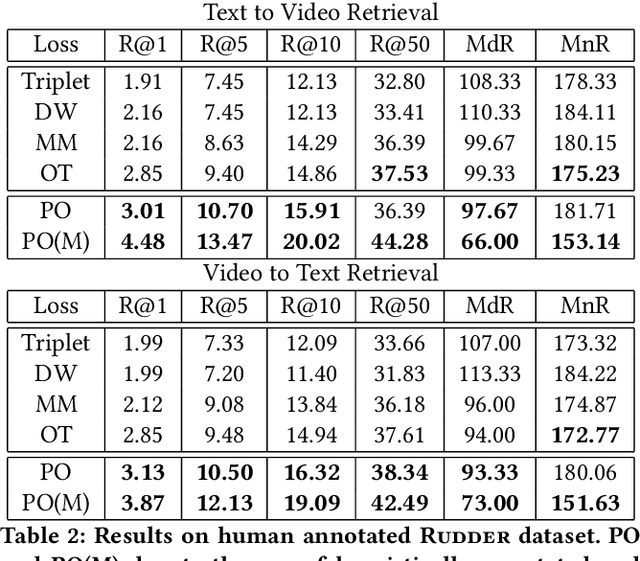
Video retrieval using natural language queries requires learning semantically meaningful joint embeddings between the text and the audio-visual input. Often, such joint embeddings are learnt using pairwise (or triplet) contrastive loss objectives which cannot give enough attention to 'difficult-to-retrieve' samples during training. This problem is especially pronounced in data-scarce settings where the data is relatively small (10% of the large scale MSR-VTT) to cover the rather complex audio-visual embedding space. In this context, we introduce Rudder - a multilingual video-text retrieval dataset that includes audio and textual captions in Marathi, Hindi, Tamil, Kannada, Malayalam and Telugu. Furthermore, we propose to compensate for data scarcity by using domain knowledge to augment supervision. To this end, in addition to the conventional three samples of a triplet (anchor, positive, and negative), we introduce a fourth term - a partial - to define a differential margin based partialorder loss. The partials are heuristically sampled such that they semantically lie in the overlap zone between the positives and the negatives, thereby resulting in broader embedding coverage. Our proposals consistently outperform the conventional max-margin and triplet losses and improve the state-of-the-art on MSR-VTT and DiDeMO datasets. We report benchmark results on Rudder while also observing significant gains using the proposed partial order loss, especially when the language specific retrieval models are jointly trained by availing the cross-lingual alignment across the language-specific datasets.
Parzen Window Approximation on Riemannian Manifold
Dec 29, 2020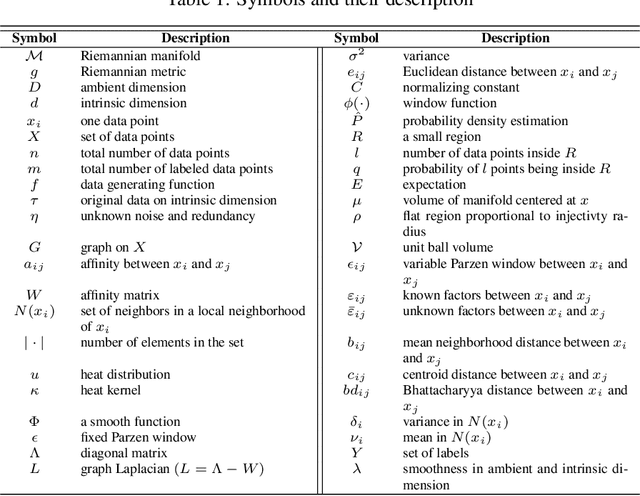

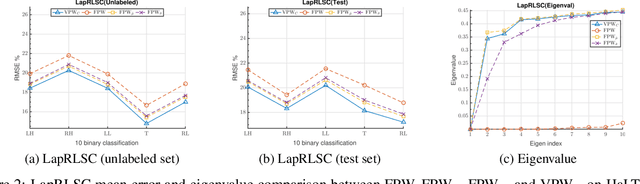
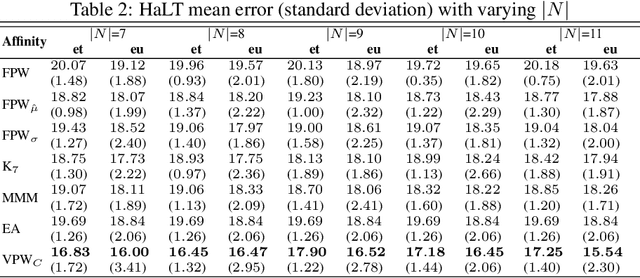
In graph motivated learning, label propagation largely depends on data affinity represented as edges between connected data points. The affinity assignment implicitly assumes even distribution of data on the manifold. This assumption may not hold and may lead to inaccurate metric assignment due to drift towards high-density regions. The drift affected heat kernel based affinity with a globally fixed Parzen window either discards genuine neighbors or forces distant data points to become a member of the neighborhood. This yields a biased affinity matrix. In this paper, the bias due to uneven data sampling on the Riemannian manifold is catered to by a variable Parzen window determined as a function of neighborhood size, ambient dimension, flatness range, etc. Additionally, affinity adjustment is used which offsets the effect of uneven sampling responsible for the bias. An affinity metric which takes into consideration the irregular sampling effect to yield accurate label propagation is proposed. Extensive experiments on synthetic and real-world data sets confirm that the proposed method increases the classification accuracy significantly and outperforms existing Parzen window estimators in graph Laplacian manifold regularization methods.
Fine-Grained Entity Type Classification by Jointly Learning Representations and Label Embeddings
Feb 22, 2017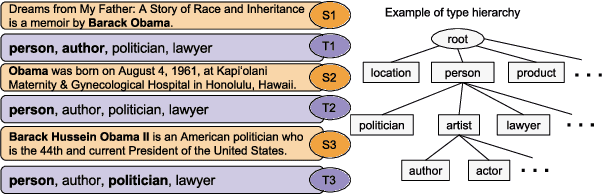
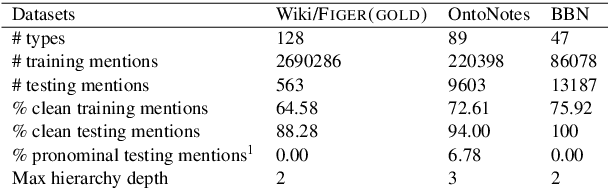

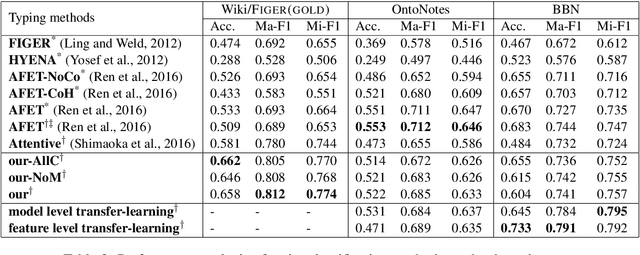
Fine-grained entity type classification (FETC) is the task of classifying an entity mention to a broad set of types. Distant supervision paradigm is extensively used to generate training data for this task. However, generated training data assigns same set of labels to every mention of an entity without considering its local context. Existing FETC systems have two major drawbacks: assuming training data to be noise free and use of hand crafted features. Our work overcomes both drawbacks. We propose a neural network model that jointly learns entity mentions and their context representation to eliminate use of hand crafted features. Our model treats training data as noisy and uses non-parametric variant of hinge loss function. Experiments show that the proposed model outperforms previous state-of-the-art methods on two publicly available datasets, namely FIGER (GOLD) and BBN with an average relative improvement of 2.69% in micro-F1 score. Knowledge learnt by our model on one dataset can be transferred to other datasets while using same model or other FETC systems. These approaches of transferring knowledge further improve the performance of respective models.