 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeFTX: Denoised Sparse Fine-Tuning for Zero-Shot Cross-Lingual Transfer
May 21, 2025Effective cross-lingual transfer remains a critical challenge in scaling the benefits of large language models from high-resource to low-resource languages. Towards this goal, prior studies have explored many approaches to combine task knowledge from task-specific data in a (high-resource) source language and language knowledge from unlabeled text in a (low-resource) target language. One notable approach proposed composable sparse fine-tuning (SFT) for cross-lingual transfer that learns task-specific and language-specific sparse masks to select a subset of the pretrained model's parameters that are further fine-tuned. These sparse fine-tuned vectors (SFTs) are subsequently composed with the pretrained model to facilitate zero-shot cross-lingual transfer to a task in a target language, using only task-specific data from a source language. These sparse masks for SFTs were identified using a simple magnitude-based pruning. In our work, we introduce DeFT-X, a novel composable SFT approach that denoises the weight matrices of a pretrained model before magnitude pruning using singular value decomposition, thus yielding more robust SFTs. We evaluate DeFT-X on a diverse set of extremely low-resource languages for sentiment classification (NusaX) and natural language inference (AmericasNLI) and demonstrate that it performs at par or outperforms SFT and other prominent cross-lingual transfer baselines.
AMPS: ASR with Multimodal Paraphrase Supervision
Nov 27, 2024Spontaneous or conversational multilingual speech presents many challenges for state-of-the-art automatic speech recognition (ASR) systems. In this work, we present a new technique AMPS that augments a multilingual multimodal ASR system with paraphrase-based supervision for improved conversational ASR in multiple languages, including Hindi, Marathi, Malayalam, Kannada, and Nyanja. We use paraphrases of the reference transcriptions as additional supervision while training the multimodal ASR model and selectively invoke this paraphrase objective for utterances with poor ASR performance. Using AMPS with a state-of-the-art multimodal model SeamlessM4T, we obtain significant relative reductions in word error rates (WERs) of up to 5%. We present detailed analyses of our system using both objective and human evaluation metrics.
Parameter-efficient Adaptation of Multilingual Multimodal Models for Low-resource ASR
Oct 17, 2024



Automatic speech recognition (ASR) for low-resource languages remains a challenge due to the scarcity of labeled training data. Parameter-efficient fine-tuning and text-only adaptation are two popular methods that have been used to address such low-resource settings. In this work, we investigate how these techniques can be effectively combined using a multilingual multimodal model like SeamlessM4T. Multimodal models are able to leverage unlabeled text via text-only adaptation with further parameter-efficient ASR fine-tuning, thus boosting ASR performance. We also show cross-lingual transfer from a high-resource language, achieving up to a relative 17% WER reduction over a baseline in a zero-shot setting without any labeled speech.
SALSA: Speedy ASR-LLM Synchronous Aggregation
Aug 29, 2024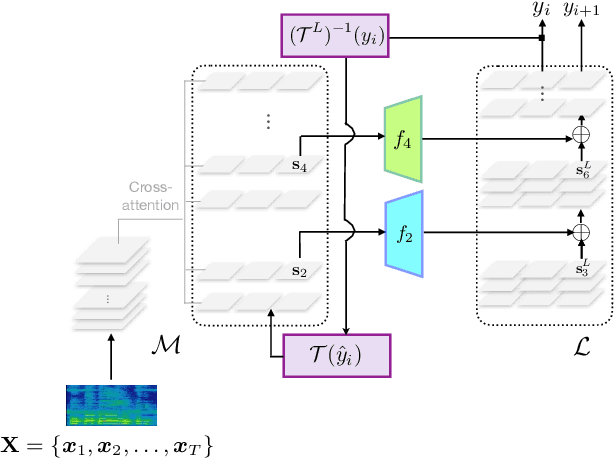


Harnessing pre-trained LLMs to improve ASR systems, particularly for low-resource languages, is now an emerging area of research. Existing methods range from using LLMs for ASR error correction to tightly coupled systems that replace the ASR decoder with the LLM. These approaches either increase decoding time or require expensive training of the cross-attention layers. We propose SALSA, which couples the decoder layers of the ASR to the LLM decoder, while synchronously advancing both decoders. Such coupling is performed with a simple projection of the last decoder state, and is thus significantly more training efficient than earlier approaches. A challenge of our proposed coupling is handling the mismatch between the tokenizers of the LLM and ASR systems. We handle this mismatch using cascading tokenization with respect to the LLM and ASR vocabularies. We evaluate SALSA on 8 low-resource languages in the FLEURS benchmark, yielding substantial WER reductions of up to 38%.
LoFTI: Localization and Factuality Transfer to Indian Locales
Jul 16, 2024



Large language models (LLMs) encode vast amounts of world knowledge acquired via training on large web-scale datasets crawled from the internet. However, these datasets typically exhibit a geographical bias towards English-speaking Western countries. This results in LLMs producing biased or hallucinated responses to queries that require answers localized to other geographical regions. In this work, we introduce a new benchmark named LoFTI (Localization and Factuality Transfer to Indian Locales) that can be used to evaluate an LLM's localization and factual text transfer capabilities. LoFTI consists of factual statements about entities in source and target locations; the source locations are spread across the globe and the target locations are all within India with varying degrees of hyperlocality (country, states, cities). The entities span a wide variety of categories. We use LoFTI to evaluate Mixtral, GPT-4 and two other Mixtral-based approaches well-suited to the task of localized factual transfer. We demonstrate that LoFTI is a high-quality evaluation benchmark and all the models, including GPT-4, produce skewed results across varying levels of hyperlocality.
Boosting Zero-Shot Crosslingual Performance using LLM-Based Augmentations with Effective Data Selection
Jul 15, 2024



Large language models (LLMs) are very proficient text generators. We leverage this capability of LLMs to generate task-specific data via zero-shot prompting and promote cross-lingual transfer for low-resource target languages. Given task-specific data in a source language and a teacher model trained on this data, we propose using this teacher to label LLM generations and employ a set of simple data selection strategies that use the teacher's label probabilities. Our data selection strategies help us identify a representative subset of diverse generations that help boost zero-shot accuracies while being efficient, in comparison to using all the LLM generations (without any subset selection). We also highlight other important design choices that affect cross-lingual performance such as the use of translations of source data and what labels are best to use for the LLM generations. We observe significant performance gains across sentiment analysis and natural language inference tasks (of up to a maximum of 7.13 absolute points and 1.5 absolute points on average) across a number of target languages (Hindi, Marathi, Urdu, Swahili) and domains.
CharSS: Character-Level Transformer Model for Sanskrit Word Segmentation
Jul 08, 2024Subword tokens in Indian languages inherently carry meaning, and isolating them can enhance NLP tasks, making sub-word segmentation a crucial process. Segmenting Sanskrit and other Indian languages into subtokens is not straightforward, as it may include sandhi, which may lead to changes in the word boundaries. We propose a new approach of utilizing a Character-level Transformer model for Sanskrit Word Segmentation (CharSS). We perform experiments on three benchmark datasets to compare the performance of our method against existing methods. On the UoH+SandhiKosh dataset, our method outperforms the current state-of-the-art system by an absolute gain of 6.72 points in split prediction accuracy. On the hackathon dataset, our method achieves a gain of 2.27 points over the current SOTA system in terms of perfect match metric. We also propose a use-case of Sanskrit-based segments for a linguistically informed translation of technical terms to lexically similar low-resource Indian languages. In two separate experimental settings for this task, we achieve an average improvement of 8.46 and 6.79 chrF++ scores, respectively.
Multi-Convformer: Extending Conformer with Multiple Convolution Kernels
Jul 04, 2024



Convolutions have become essential in state-of-the-art end-to-end Automatic Speech Recognition~(ASR) systems due to their efficient modelling of local context. Notably, its use in Conformers has led to superior performance compared to vanilla Transformer-based ASR systems. While components other than the convolution module in the Conformer have been reexamined, altering the convolution module itself has been far less explored. Towards this, we introduce Multi-Convformer that uses multiple convolution kernels within the convolution module of the Conformer in conjunction with gating. This helps in improved modeling of local dependencies at varying granularities. Our model rivals existing Conformer variants such as CgMLP and E-Branchformer in performance, while being more parameter efficient. We empirically compare our approach with Conformer and its variants across four different datasets and three different modelling paradigms and show up to 8% relative word error rate~(WER) improvements.
Improving Self-supervised Pre-training using Accent-Specific Codebooks
Jul 04, 2024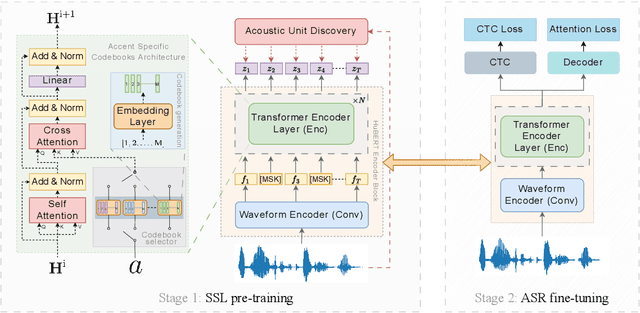


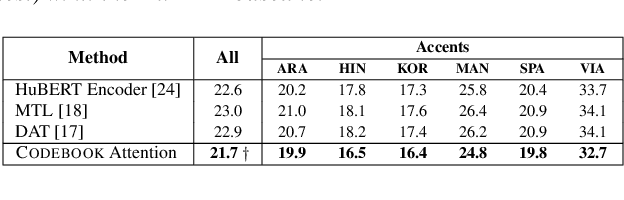
Speech accents present a serious challenge to the performance of state-of-the-art end-to-end Automatic Speech Recognition (ASR) systems. Even with self-supervised learning and pre-training of ASR models, accent invariance is seldom achieved. In this work, we propose an accent-aware adaptation technique for self-supervised learning that introduces a trainable set of accent-specific codebooks to the self-supervised architecture. These learnable codebooks enable the model to capture accent specific information during pre-training, that is further refined during ASR finetuning. On the Mozilla Common Voice dataset, our proposed approach outperforms all other accent-adaptation approaches on both seen and unseen English accents, with up to 9% relative reduction in word error rate (WER).
CoSTA: Code-Switched Speech Translation using Aligned Speech-Text Interleaving
Jun 16, 2024
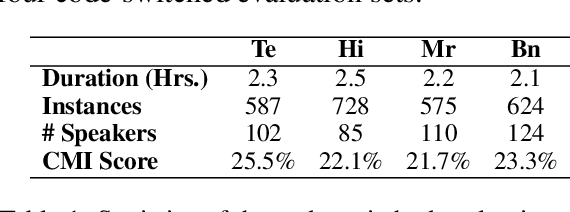

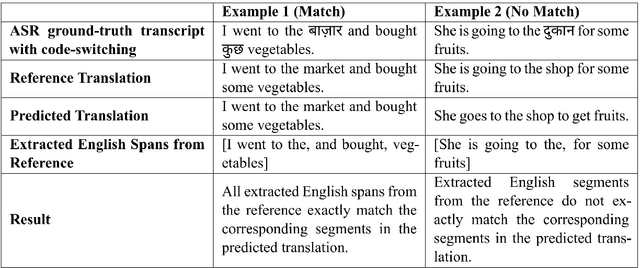
Code-switching is a widely prevalent linguistic phenomenon in multilingual societies like India. Building speech-to-text models for code-switched speech is challenging due to limited availability of datasets. In this work, we focus on the problem of spoken translation (ST) of code-switched speech in Indian languages to English text. We present a new end-to-end model architecture COSTA that scaffolds on pretrained automatic speech recognition (ASR) and machine translation (MT) modules (that are more widely available for many languages). Speech and ASR text representations are fused using an aligned interleaving scheme and are fed further as input to a pretrained MT module; the whole pipeline is then trained end-to-end for spoken translation using synthetically created ST data. We also release a new evaluation benchmark for code-switched Bengali-English, Hindi-English, Marathi-English and Telugu- English speech to English text. COSTA significantly outperforms many competitive cascaded and end-to-end multimodal baselines by up to 3.5 BLEU points.