 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining In-Context and In-Weights Mixtures Via Contrastive Context Sampling
Apr 02, 2026We investigate training strategies that co-develop in-context learning (ICL) and in-weights learning (IWL), and the ability to switch between them based on context relevance. Although current LLMs exhibit both modes, standard task-specific fine-tuning often erodes ICL, motivating IC-Train - fine-tuning with in-context examples. Prior work has shown that emergence of ICL after IC-Train depends on factors such as task diversity and training duration. In this paper we show that the similarity structure between target inputs and context examples also plays an important role. Random context leads to loss of ICL and IWL dominance, while only similar examples in context causes ICL to degenerate to copying labels without regard to relevance. To address this, we propose a simple Contrastive-Context which enforces two types of contrasts: (1) mix of similar and random examples within a context to evolve a correct form of ICL, and (2) varying grades of similarity across contexts to evolve ICL-IWL mixtures. We present insights on the importance of such contrast with theoretical analysis of a minimal model. We validate with extensive empirical evaluation on four LLMs and several tasks. Diagnostic probes confirm that contrasted contexts yield stable ICL-IWL mixtures, avoiding collapse into pure ICL, IWL, or copying.
TFMAdapter: Lightweight Instance-Level Adaptation of Foundation Models for Forecasting with Covariates
Sep 17, 2025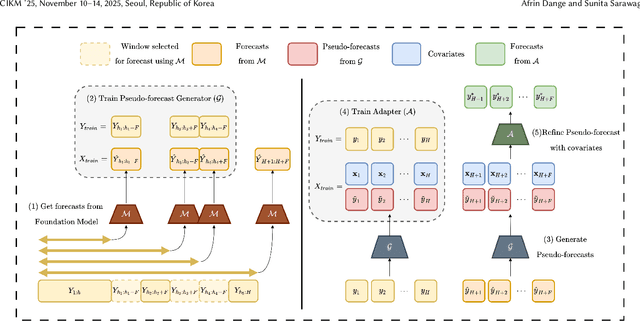
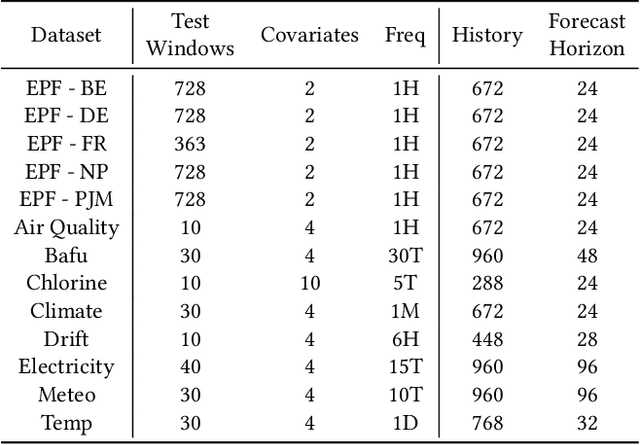
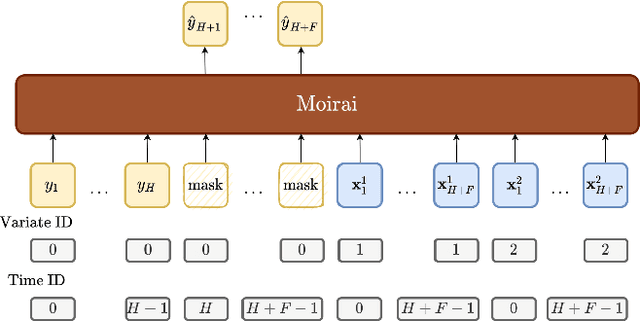
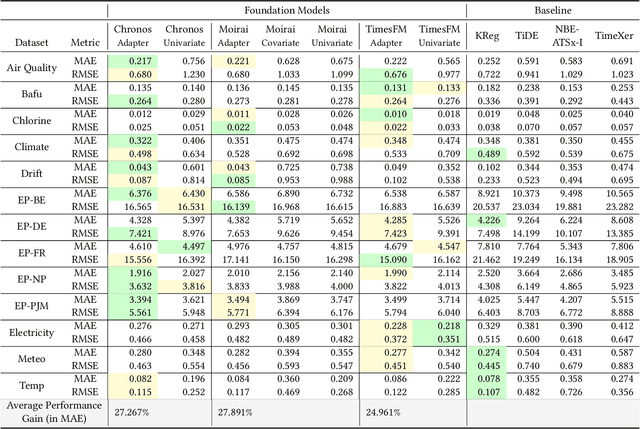
Time Series Foundation Models (TSFMs) have recently achieved state-of-the-art performance in univariate forecasting on new time series simply by conditioned on a brief history of past values. Their success demonstrates that large-scale pretraining across diverse domains can acquire the inductive bias to generalize from temporal patterns in a brief history. However, most TSFMs are unable to leverage covariates -- future-available exogenous variables critical for accurate forecasting in many applications -- due to their domain-specific nature and the lack of associated inductive bias. We propose TFMAdapter, a lightweight, instance-level adapter that augments TSFMs with covariate information without fine-tuning. Instead of retraining, TFMAdapter operates on the limited history provided during a single model call, learning a non-parametric cascade that combines covariates with univariate TSFM forecasts. However, such learning would require univariate forecasts at all steps in the history, requiring too many calls to the TSFM. To enable training on the full historical context while limiting TSFM invocations, TFMAdapter uses a two-stage method: (1) generating pseudo-forecasts with a simple regression model, and (2) training a Gaussian Process regressor to refine predictions using both pseudo- and TSFM forecasts alongside covariates. Extensive experiments on real-world datasets demonstrate that TFMAdapter consistently outperforms both foundation models and supervised baselines, achieving a 24-27\% improvement over base foundation models with minimal data and computational overhead. Our results highlight the potential of lightweight adapters to bridge the gap between generic foundation models and domain-specific forecasting needs.
From Search To Sampling: Generative Models For Robust Algorithmic Recourse
May 12, 2025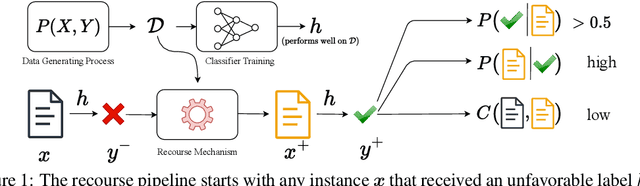



Algorithmic Recourse provides recommendations to individuals who are adversely impacted by automated model decisions, on how to alter their profiles to achieve a favorable outcome. Effective recourse methods must balance three conflicting goals: proximity to the original profile to minimize cost, plausibility for realistic recourse, and validity to ensure the desired outcome. We show that existing methods train for these objectives separately and then search for recourse through a joint optimization over the recourse goals during inference, leading to poor recourse recommendations. We introduce GenRe, a generative recourse model designed to train the three recourse objectives jointly. Training such generative models is non-trivial due to lack of direct recourse supervision. We propose efficient ways to synthesize such supervision and further show that GenRe's training leads to a consistent estimator. Unlike most prior methods, that employ non-robust gradient descent based search during inference, GenRe simply performs a forward sampling over the generative model to produce minimum cost recourse, leading to superior performance across multiple metrics. We also demonstrate GenRe provides the best trade-off between cost, plausibility and validity, compared to state-of-art baselines. Our code is available at: https://github.com/prateekgargx/genre.
Robust Root Cause Diagnosis using In-Distribution Interventions
May 02, 2025



Diagnosing the root cause of an anomaly in a complex interconnected system is a pressing problem in today's cloud services and industrial operations. We propose In-Distribution Interventions (IDI), a novel algorithm that predicts root cause as nodes that meet two criteria: 1) **Anomaly:** root cause nodes should take on anomalous values; 2) **Fix:** had the root cause nodes assumed usual values, the target node would not have been anomalous. Prior methods of assessing the fix condition rely on counterfactuals inferred from a Structural Causal Model (SCM) trained on historical data. But since anomalies are rare and fall outside the training distribution, the fitted SCMs yield unreliable counterfactual estimates. IDI overcomes this by relying on interventional estimates obtained by solely probing the fitted SCM at in-distribution inputs. We present a theoretical analysis comparing and bounding the errors in assessing the fix condition using interventional and counterfactual estimates. We then conduct experiments by systematically varying the SCM's complexity to demonstrate the cases where IDI's interventional approach outperforms the counterfactual approach and vice versa. Experiments on both synthetic and PetShop RCD benchmark datasets demonstrate that \our\ consistently identifies true root causes more accurately and robustly than nine existing state-of-the-art RCD baselines. Code is released at https://github.com/nlokeshiisc/IDI_release.
Diverse In-Context Example Selection After Decomposing Programs and Aligned Utterances Improves Semantic Parsing
Apr 04, 2025LLMs are increasingly used as seq2seq translators from natural language utterances to structured programs, a process called semantic interpretation. Unlike atomic labels or token sequences, programs are naturally represented as abstract syntax trees (ASTs). Such structured representation raises novel issues related to the design and selection of in-context examples (ICEs) presented to the LLM. We focus on decomposing the pool of available ICE trees into fragments, some of which may be better suited to solving the test instance. Next, we propose how to use (additional invocations of) an LLM with prompted syntax constraints to automatically map the fragments to corresponding utterances. Finally, we adapt and extend a recent method for diverse ICE selection to work with whole and fragmented ICE instances. We evaluate our system, SCUD4ICL, on popular diverse semantic parsing benchmarks, showing visible accuracy gains from our proposed decomposed diverse demonstration method. Benefits are particularly notable for smaller LLMs, ICE pools having larger labeled trees, and programs in lower resource languages.
Leveraging a Simulator for Learning Causal Representations from Post-Treatment Covariates for CATE
Feb 07, 2025Treatment effect estimation involves assessing the impact of different treatments on individual outcomes. Current methods estimate Conditional Average Treatment Effect (CATE) using observational datasets where covariates are collected before treatment assignment and outcomes are observed afterward, under assumptions like positivity and unconfoundedness. In this paper, we address a scenario where both covariates and outcomes are gathered after treatment. We show that post-treatment covariates render CATE unidentifiable, and recovering CATE requires learning treatment-independent causal representations. Prior work shows that such representations can be learned through contrastive learning if counterfactual supervision is available in observational data. However, since counterfactuals are rare, other works have explored using simulators that offer synthetic counterfactual supervision. Our goal in this paper is to systematically analyze the role of simulators in estimating CATE. We analyze the CATE error of several baselines and highlight their limitations. We then establish a generalization bound that characterizes the CATE error from jointly training on real and simulated distributions, as a function of the real-simulator mismatch. Finally, we introduce SimPONet, a novel method whose loss function is inspired from our generalization bound. We further show how SimPONet adjusts the simulator's influence on the learning objective based on the simulator's relevance to the CATE task. We experiment with various DGPs, by systematically varying the real-simulator distribution gap to evaluate SimPONet's efficacy against state-of-the-art CATE baselines.
Synthetic Tabular Data Generation for Imbalanced Classification: The Surprising Effectiveness of an Overlap Class
Dec 20, 2024Handling imbalance in class distribution when building a classifier over tabular data has been a problem of long-standing interest. One popular approach is augmenting the training dataset with synthetically generated data. While classical augmentation techniques were limited to linear interpolation of existing minority class examples, recently higher capacity deep generative models are providing greater promise. However, handling of imbalance in class distribution when building a deep generative model is also a challenging problem, that has not been studied as extensively as imbalanced classifier model training. We show that state-of-the-art deep generative models yield significantly lower-quality minority examples than majority examples. %In this paper, we start with the observation that imbalanced data training of generative models trained imbalanced dataset which under-represent the minority class. We propose a novel technique of converting the binary class labels to ternary class labels by introducing a class for the region where minority and majority distributions overlap. We show that just this pre-processing of the training set, significantly improves the quality of data generated spanning several state-of-the-art diffusion and GAN-based models. While training the classifier using synthetic data, we remove the overlap class from the training data and justify the reasons behind the enhanced accuracy. We perform extensive experiments on four real-life datasets, five different classifiers, and five generative models demonstrating that our method enhances not only the synthesizer performance of state-of-the-art models but also the classifier performance.
Text-to-SQL Calibration: No Need to Ask -- Just Rescale Model Probabilities
Nov 23, 2024
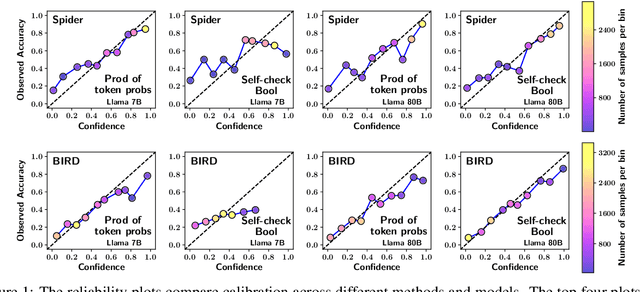

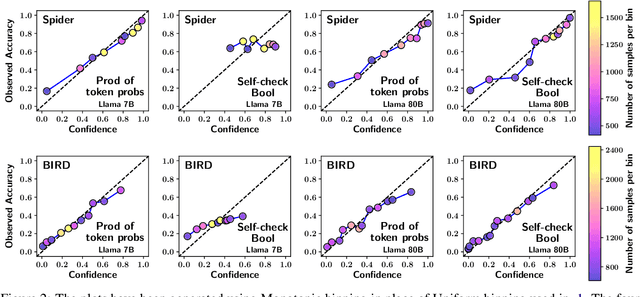
Calibration is crucial as large language models (LLMs) are increasingly deployed to convert natural language queries into SQL for commercial databases. In this work, we investigate calibration techniques for assigning confidence to generated SQL queries. We show that a straightforward baseline -- deriving confidence from the model's full-sequence probability -- outperforms recent methods that rely on follow-up prompts for self-checking and confidence verbalization. Our comprehensive evaluation, conducted across two widely-used Text-to-SQL benchmarks and multiple LLM architectures, provides valuable insights into the effectiveness of various calibration strategies.
SALSA: Speedy ASR-LLM Synchronous Aggregation
Aug 29, 2024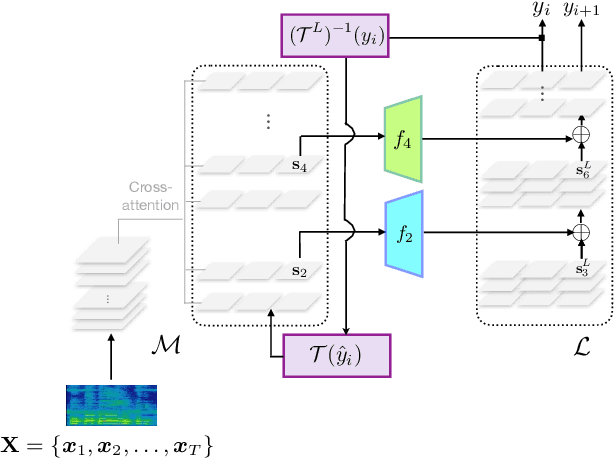

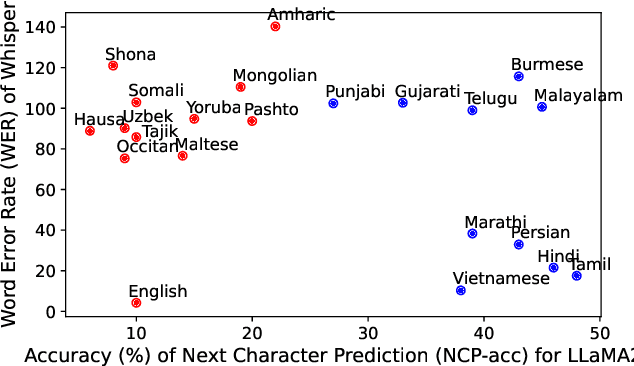

Harnessing pre-trained LLMs to improve ASR systems, particularly for low-resource languages, is now an emerging area of research. Existing methods range from using LLMs for ASR error correction to tightly coupled systems that replace the ASR decoder with the LLM. These approaches either increase decoding time or require expensive training of the cross-attention layers. We propose SALSA, which couples the decoder layers of the ASR to the LLM decoder, while synchronously advancing both decoders. Such coupling is performed with a simple projection of the last decoder state, and is thus significantly more training efficient than earlier approaches. A challenge of our proposed coupling is handling the mismatch between the tokenizers of the LLM and ASR systems. We handle this mismatch using cascading tokenization with respect to the LLM and ASR vocabularies. We evaluate SALSA on 8 low-resource languages in the FLEURS benchmark, yielding substantial WER reductions of up to 38%.
Efficient Training of Language Models with Compact and Consistent Next Token Distributions
Jul 03, 2024

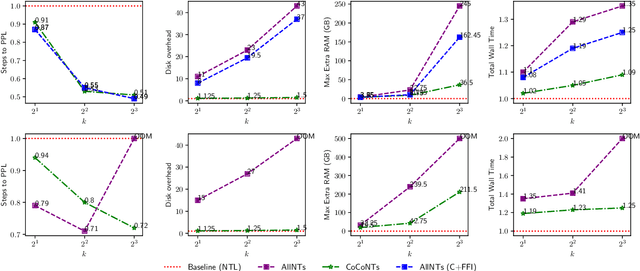

Maximizing the likelihood of the next token is an established, statistically sound objective for pre-training language models. In this paper we show that we can train better models faster by pre-aggregating the corpus with a collapsed $n$-gram distribution. Previous studies have proposed corpus-level $n$-gram statistics as a regularizer; however, the construction and querying of such $n$-grams, if done naively, prove to be costly and significantly impede training speed, thereby limiting their application in modern large language model pre-training. We introduce an alternative compact representation of the next token distribution that, in expectation, aligns with the complete $n$-gram distribution while markedly reducing variance across mini-batches compared to the standard next-token loss. Empirically, we demonstrate that both the $n$-gram regularized model and our approximation yield substantial improvements in model quality and convergence rate compared to existing methods. Furthermore, our approximation facilitates scalability of gains to larger datasets and models compared to the straightforward $n$-gram regularization method.