 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharting the Design Space of Neural Graph Representations for Subgraph Matching
Oct 27, 2025Subgraph matching is vital in knowledge graph (KG) question answering, molecule design, scene graph, code and circuit search, etc. Neural methods have shown promising results for subgraph matching. Our study of recent systems suggests refactoring them into a unified design space for graph matching networks. Existing methods occupy only a few isolated patches in this space, which remains largely uncharted. We undertake the first comprehensive exploration of this space, featuring such axes as attention-based vs. soft permutation-based interaction between query and corpus graphs, aligning nodes vs. edges, and the form of the final scoring network that integrates neural representations of the graphs. Our extensive experiments reveal that judicious and hitherto-unexplored combinations of choices in this space lead to large performance benefits. Beyond better performance, our study uncovers valuable insights and establishes general design principles for neural graph representation and interaction, which may be of wider interest.
Iteratively Refined Early Interaction Alignment for Subgraph Matching based Graph Retrieval
Oct 26, 2025Graph retrieval based on subgraph isomorphism has several real-world applications such as scene graph retrieval, molecular fingerprint detection and circuit design. Roy et al. [35] proposed IsoNet, a late interaction model for subgraph matching, which first computes the node and edge embeddings of each graph independently of paired graph and then computes a trainable alignment map. Here, we present IsoNet++, an early interaction graph neural network (GNN), based on several technical innovations. First, we compute embeddings of all nodes by passing messages within and across the two input graphs, guided by an injective alignment between their nodes. Second, we update this alignment in a lazy fashion over multiple rounds. Within each round, we run a layerwise GNN from scratch, based on the current state of the alignment. After the completion of one round of GNN, we use the last-layer embeddings to update the alignments, and proceed to the next round. Third, IsoNet++ incorporates a novel notion of node-pair partner interaction. Traditional early interaction computes attention between a node and its potential partners in the other graph, the attention then controlling messages passed across graphs. In contrast, we consider node pairs (not single nodes) as potential partners. Existence of an edge between the nodes in one graph and non-existence in the other provide vital signals for refining the alignment. Our experiments on several datasets show that the alignments get progressively refined with successive rounds, resulting in significantly better retrieval performance than existing methods. We demonstrate that all three innovations contribute to the enhanced accuracy. Our code and datasets are publicly available at https://github.com/structlearning/isonetpp.
Contextual Tokenization for Graph Inverted Indices
Oct 26, 2025Retrieving graphs from a large corpus, that contain a subgraph isomorphic to a given query graph, is a core operation in many real-world applications. While recent multi-vector graph representations and scores based on set alignment and containment can provide accurate subgraph isomorphism tests, their use in retrieval remains limited by their need to score corpus graphs exhaustively. We introduce CORGII (Contextual Representation of Graphs for Inverted Indexing), a graph indexing framework in which, starting with a contextual dense graph representation, a differentiable discretization module computes sparse binary codes over a learned latent vocabulary. This text document-like representation allows us to leverage classic, highly optimized inverted indices, while supporting soft (vector) set containment scores. Pushing this paradigm further, we replace the classical, fixed impact weight of a `token' on a graph (such as TFIDF or BM25) with a data-driven, trainable impact weight. Finally, we explore token expansion to support multi-probing the index for smoother accuracy-efficiency tradeoffs. To our knowledge, CORGII is the first indexer of dense graph representations using discrete tokens mapping to efficient inverted lists. Extensive experiments show that CORGII provides better trade-offs between accuracy and efficiency, compared to several baselines.
Diverse In-Context Example Selection After Decomposing Programs and Aligned Utterances Improves Semantic Parsing
Apr 04, 2025LLMs are increasingly used as seq2seq translators from natural language utterances to structured programs, a process called semantic interpretation. Unlike atomic labels or token sequences, programs are naturally represented as abstract syntax trees (ASTs). Such structured representation raises novel issues related to the design and selection of in-context examples (ICEs) presented to the LLM. We focus on decomposing the pool of available ICE trees into fragments, some of which may be better suited to solving the test instance. Next, we propose how to use (additional invocations of) an LLM with prompted syntax constraints to automatically map the fragments to corresponding utterances. Finally, we adapt and extend a recent method for diverse ICE selection to work with whole and fragmented ICE instances. We evaluate our system, SCUD4ICL, on popular diverse semantic parsing benchmarks, showing visible accuracy gains from our proposed decomposed diverse demonstration method. Benefits are particularly notable for smaller LLMs, ICE pools having larger labeled trees, and programs in lower resource languages.
Efficient Continual Pre-training of LLMs for Low-resource Languages
Dec 13, 2024Open-source Large Language models (OsLLMs) propel the democratization of natural language research by giving the flexibility to augment or update model parameters for performance improvement. Nevertheless, like proprietary LLMs, Os-LLMs offer poorer performance on low-resource languages (LRLs) than high-resource languages (HRLs), owing to smaller amounts of training data and underrepresented vocabulary. On the other hand, continual pre-training (CPT) with large amounts of language-specific data is a costly proposition in terms of data acquisition and computational resources. Our goal is to drastically reduce CPT cost. To that end, we first develop a new algorithm to select a subset of texts from a larger corpus. We show the effectiveness of our technique using very little CPT data. In search of further improvement, we design a new algorithm to select tokens to include in the LLM vocabulary. We experiment with the recent Llama-3 model and nine Indian languages with diverse scripts and extent of resource availability. For evaluation, we use IndicGenBench, a generation task benchmark dataset for Indic languages. We experiment with various CPT corpora and augmented vocabulary size and offer insights across language families.
Graph Edit Distance with General Costs Using Neural Set Divergence
Sep 26, 2024



Graph Edit Distance (GED) measures the (dis-)similarity between two given graphs, in terms of the minimum-cost edit sequence that transforms one graph to the other. However, the exact computation of GED is NP-Hard, which has recently motivated the design of neural methods for GED estimation. However, they do not explicitly account for edit operations with different costs. In response, we propose GRAPHEDX, a neural GED estimator that can work with general costs specified for the four edit operations, viz., edge deletion, edge addition, node deletion and node addition. We first present GED as a quadratic assignment problem (QAP) that incorporates these four costs. Then, we represent each graph as a set of node and edge embeddings and use them to design a family of neural set divergence surrogates. We replace the QAP terms corresponding to each operation with their surrogates. Computing such neural set divergence require aligning nodes and edges of the two graphs. We learn these alignments using a Gumbel-Sinkhorn permutation generator, additionally ensuring that the node and edge alignments are consistent with each other. Moreover, these alignments are cognizant of both the presence and absence of edges between node-pairs. Experiments on several datasets, under a variety of edit cost settings, show that GRAPHEDX consistently outperforms state-of-the-art methods and heuristics in terms of prediction error.
* Published at NeurIPS 2024
Cost-Performance Optimization for Processing Low-Resource Language Tasks Using Commercial LLMs
Mar 08, 2024



Large Language Models (LLMs) exhibit impressive zero/few-shot inference and generation quality for high-resource languages(HRLs). A few of them have been trained in low-resource languages (LRLs) and give decent performance. Owing to the prohibitive costs of training LLMs, they are usually used as a network service, with the client charged by the count of input and output tokens. The number of tokens strongly depends on the script and language, as well as the LLM's sub-word vocabulary. We show that LRLs are at a pricing disadvantage, because the well-known LLMs produce more tokens for LRLs than HRLs. This is because most currently popular LLMs are optimized for HRL vocabularies. Our objective is to level the playing field: reduce the cost of processing LRLs in contemporary LLMs while ensuring that predictive and generative qualities are not compromised. As means to reduce the number of tokens processed by the LLM, we consider code-mixing, translation, and transliteration of LRLs to HRLs. We perform an extensive study using the IndicXTREME dataset, covering 15 Indian languages, while using GPT-4 (one of the costliest LLM services released so far) as a commercial LLM. We observe and analyze interesting patterns involving token count, cost,and quality across a multitude of languages and tasks. We show that choosing the best policy to interact with the LLM can reduce cost by 90% while giving better or comparable performance, compared to communicating with the LLM in the original LRL.
How to think step-by-step: A mechanistic understanding of chain-of-thought reasoning
Feb 28, 2024



Despite superior reasoning prowess demonstrated by Large Language Models (LLMs) with Chain-of-Thought (CoT) prompting, a lack of understanding prevails around the internal mechanisms of the models that facilitate CoT generation. This work investigates the neural sub-structures within LLMs that manifest CoT reasoning from a mechanistic point of view. From an analysis of LLaMA-2 7B applied to multistep reasoning over fictional ontologies, we demonstrate that LLMs deploy multiple parallel pathways of answer generation for step-by-step reasoning. These parallel pathways provide sequential answers from the input question context as well as the generated CoT. We observe a striking functional rift in the middle layers of the LLM. Token representations in the initial half remain strongly biased towards the pretraining prior, with the in-context taking over abruptly in the later half. This internal phase shift manifests in different functional components: attention heads that write the answer token predominantly appear in the later half, attention heads that move information along ontological relationships appear exclusively in the initial half, and so on. To the best of our knowledge, this is the first attempt towards mechanistic investigation of CoT reasoning in LLMs.
Graph Regularized Encoder Training for Extreme Classification
Feb 28, 2024
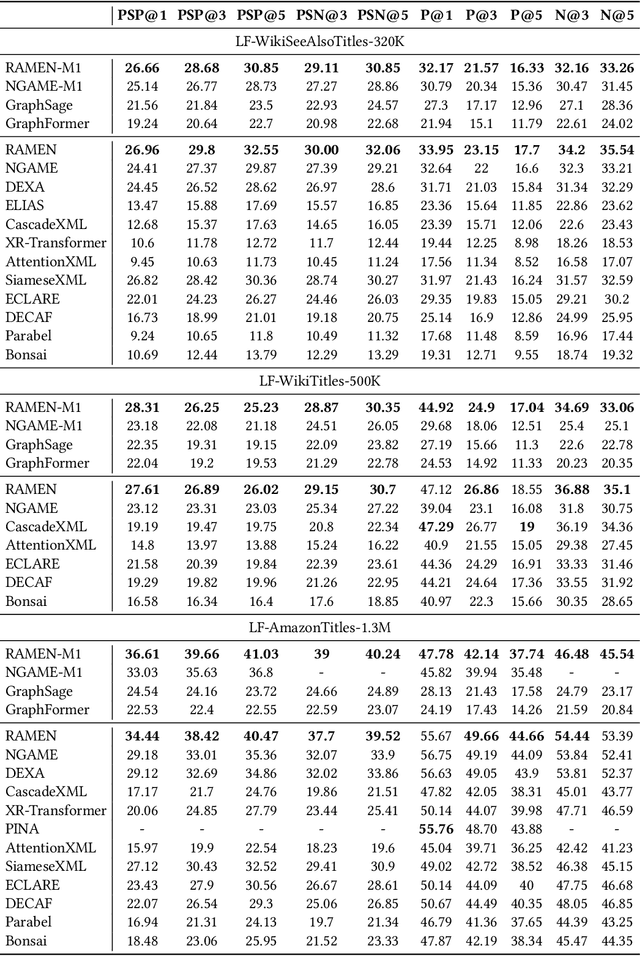
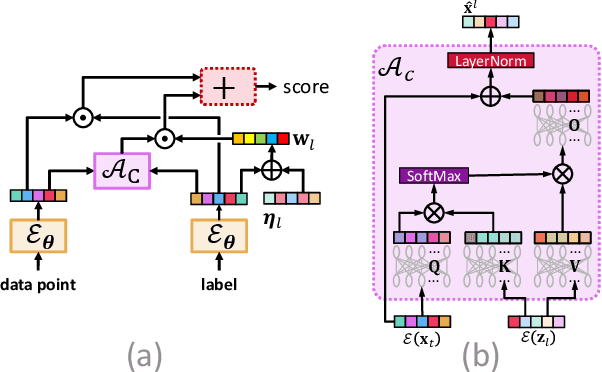
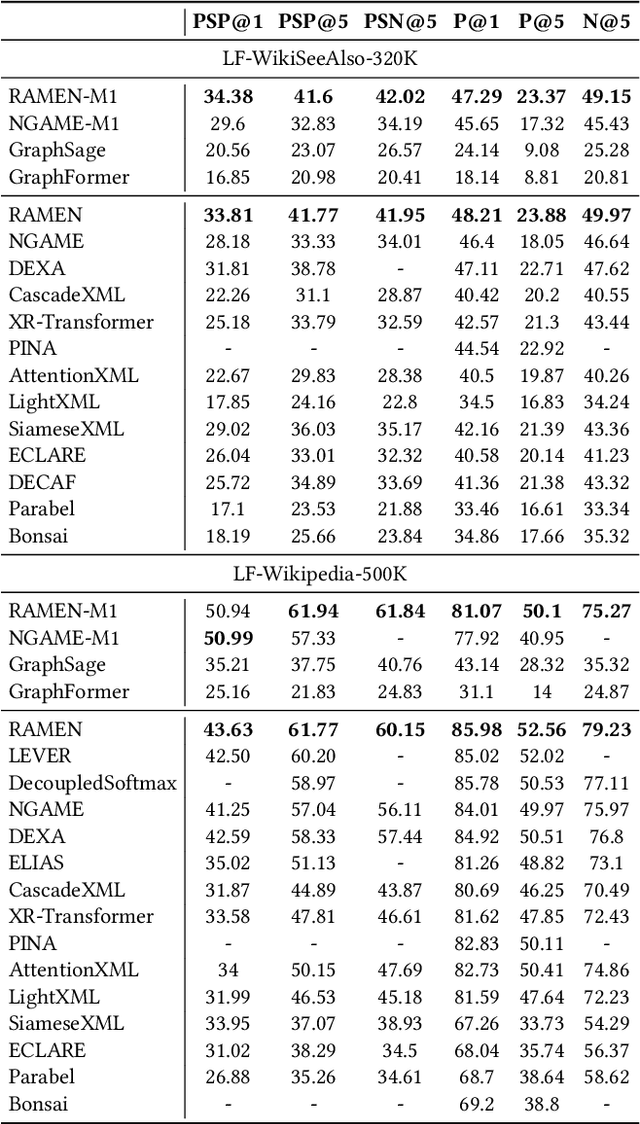
Deep extreme classification (XC) aims to train an encoder architecture and an accompanying classifier architecture to tag a data point with the most relevant subset of labels from a very large universe of labels. XC applications in ranking, recommendation and tagging routinely encounter tail labels for which the amount of training data is exceedingly small. Graph convolutional networks (GCN) present a convenient but computationally expensive way to leverage task metadata and enhance model accuracies in these settings. This paper formally establishes that in several use cases, the steep computational cost of GCNs is entirely avoidable by replacing GCNs with non-GCN architectures. The paper notices that in these settings, it is much more effective to use graph data to regularize encoder training than to implement a GCN. Based on these insights, an alternative paradigm RAMEN is presented to utilize graph metadata in XC settings that offers significant performance boosts with zero increase in inference computational costs. RAMEN scales to datasets with up to 1M labels and offers prediction accuracy up to 15% higher on benchmark datasets than state of the art methods, including those that use graph metadata to train GCNs. RAMEN also offers 10% higher accuracy over the best baseline on a proprietary recommendation dataset sourced from click logs of a popular search engine. Code for RAMEN will be released publicly.
Frugal LMs Trained to Invoke Symbolic Solvers Achieve Parameter-Efficient Arithmetic Reasoning
Dec 19, 2023



Large Language Models (LLM) exhibit zero-shot mathematical reasoning capacity as a behavior emergent with scale, commonly manifesting as chain-of-thoughts (CoT) reasoning. However, multiple empirical findings suggest that this prowess is exclusive to LLMs with exorbitant sizes (beyond 50 billion parameters). Meanwhile, educational neuroscientists suggest that symbolic algebraic manipulation be introduced around the same time as arithmetic word problems to modularize language-to-formulation, symbolic manipulation of the formulation, and endgame arithmetic. In this paper, we start with the hypothesis that much smaller LMs, which are weak at multi-step reasoning, can achieve reasonable arithmetic reasoning if arithmetic word problems are posed as a formalize-then-solve task. In our architecture, which we call SYRELM, the LM serves the role of a translator to map natural language arithmetic questions into a formal language (FL) description. A symbolic solver then evaluates the FL expression to obtain the answer. A small frozen LM, equipped with an efficient low-rank adapter, is capable of generating FL expressions that incorporate natural language descriptions of the arithmetic problem (e.g., variable names and their purposes, formal expressions combining variables, etc.). We adopt policy-gradient reinforcement learning to train the adapted LM, informed by the non-differentiable symbolic solver. This marks a sharp departure from the recent development in tool-augmented LLMs, in which the external tools (e.g., calculator, Web search, etc.) are essentially detached from the learning phase of the LM. SYRELM shows massive improvements (e.g., +30.65 absolute point improvement in accuracy on the SVAMP dataset using GPT-J 6B model) over base LMs, while keeping our testbed easy to diagnose, interpret and within reach of most researchers.