 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHARNESS-LM: A Three-Phase Training Recipe for Harnessing SLMs in Sponsored Search Retrieval
May 22, 2026In the competitive landscape of sponsored search, balancing retrieval quality with production latency is a critical challenge. While large retrieval models based on Small Language Models (SLMs) such as Qwen3-Embedding-4B/8B set strong upper bounds on public benchmarks, their deployment in high-throughput, latency-sensitive environments remains impractical. In this paper, we present HARNESS-LM (HLM), a three-phase training framework for transferring the capabilities of large-scale retrievers into compact, cost-efficient models. The approach comprises: (1) training a high-performance reference ("teacher") retriever by fine-tuning a billion-parameter-scale SLM; (2) aligning query representations via an L2 objective to distill knowledge into a sub-600M parameter student encoder; and (3) applying a final contrastive refinement stage to optimize the student for retrieval performance. We also present a comprehensive empirical study of key design choices, including alignment objectives, embedding dimensionality, model scale, architecture, and optimization strategies, to identify configurations that are most effective in production settings. On a real-world Bing Ads evaluation benchmark, HLM recovers over 98% of the reference retriever's precision across multiple settings, while delivering up to 27x lower online query-encoder latency and 20x higher throughput on NVIDIA A100 GPUs. Online A/B testing on Bing Ads further shows a +1% Revenue, +0.6% Impression, and +0.4% Click uplift over the current ensemble of retrievers running in production with the deployed 190M parameter model, clearly highlighting the practical efficacy of the HLM recipe in a real-world sponsored search setting.
Graph Regularized Encoder Training for Extreme Classification
Feb 28, 2024
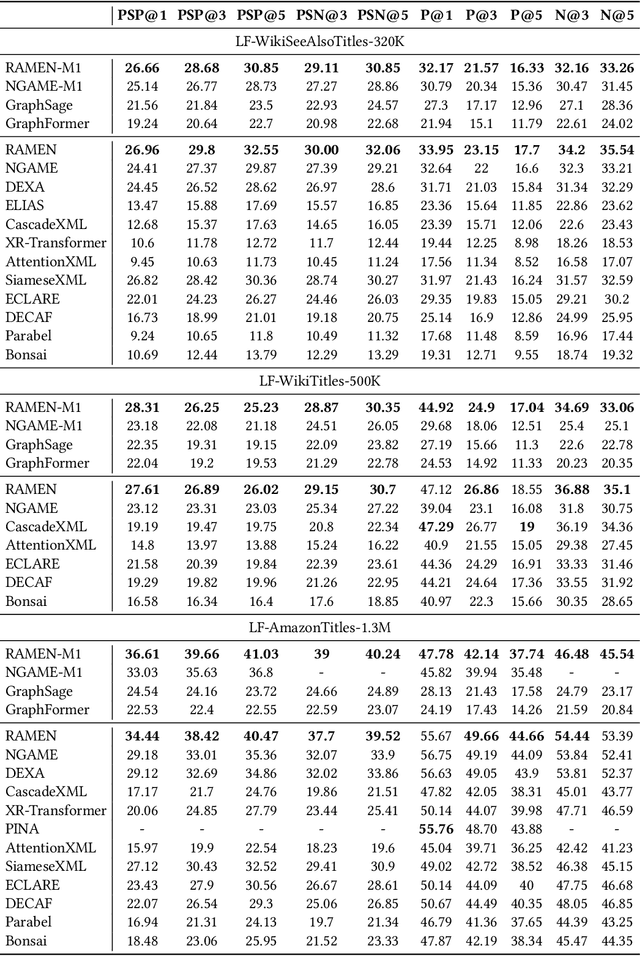
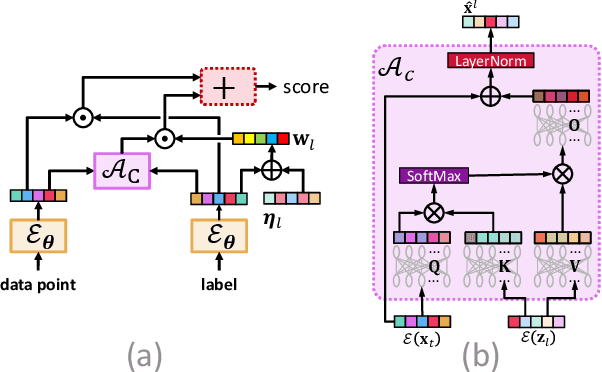
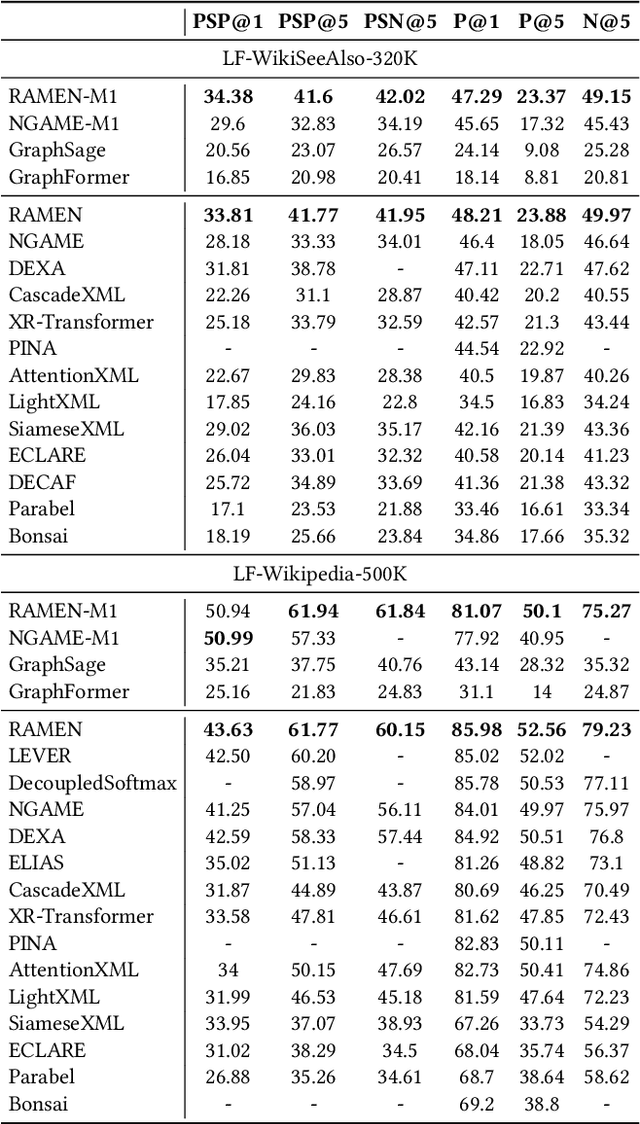
Deep extreme classification (XC) aims to train an encoder architecture and an accompanying classifier architecture to tag a data point with the most relevant subset of labels from a very large universe of labels. XC applications in ranking, recommendation and tagging routinely encounter tail labels for which the amount of training data is exceedingly small. Graph convolutional networks (GCN) present a convenient but computationally expensive way to leverage task metadata and enhance model accuracies in these settings. This paper formally establishes that in several use cases, the steep computational cost of GCNs is entirely avoidable by replacing GCNs with non-GCN architectures. The paper notices that in these settings, it is much more effective to use graph data to regularize encoder training than to implement a GCN. Based on these insights, an alternative paradigm RAMEN is presented to utilize graph metadata in XC settings that offers significant performance boosts with zero increase in inference computational costs. RAMEN scales to datasets with up to 1M labels and offers prediction accuracy up to 15% higher on benchmark datasets than state of the art methods, including those that use graph metadata to train GCNs. RAMEN also offers 10% higher accuracy over the best baseline on a proprietary recommendation dataset sourced from click logs of a popular search engine. Code for RAMEN will be released publicly.
Attention W-Net: Improved Skip Connections for better Representations
Oct 17, 2021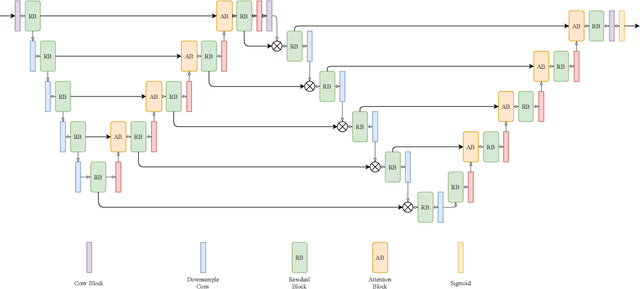

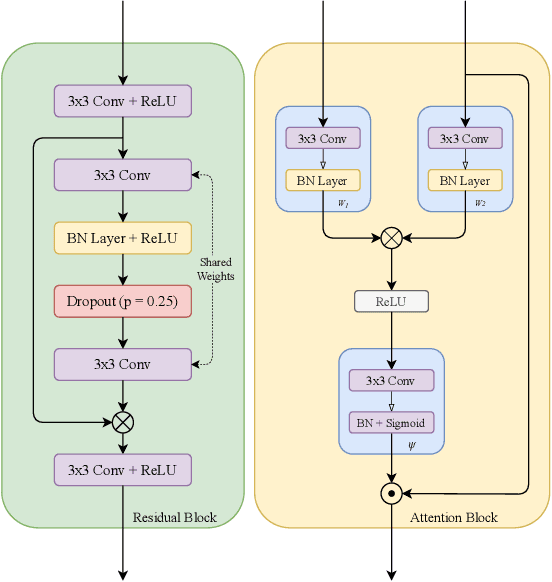
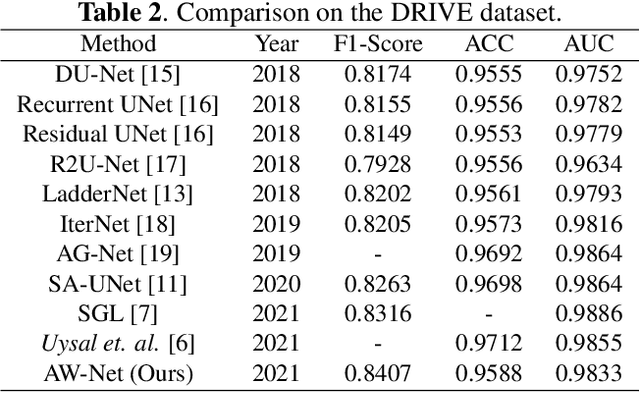
Segmentation of macro and microvascular structures in fundoscopic retinal images plays a crucial role in detection of multiple retinal and systemic diseases, yet it is a difficult problem to solve. Most deep learning approaches for this task involve an autoencoder based architecture, but they face several issues such as lack of enough parameters, overfitting when there are enough parameters and incompatibility between internal feature-spaces. Due to such issues, these techniques are hence not able to extract the best semantic information from the limited data present for such tasks. We propose Attention W-Net, a new U-Net based architecture for retinal vessel segmentation to address these problems. In this architecture with a LadderNet backbone, we have two main contributions: Attention Block and regularisation measures. Our Attention Block uses decoder features to attend over the encoder features from skip-connections during upsampling, resulting in higher compatibility when the encoder and decoder features are added. Our regularisation measures include image augmentation and modifications to the ResNet Block used, which prevent overfitting. With these additions, we observe an AUC and F1-Score of 0.8407 and 0.9833 - a sizeable improvement over its LadderNet backbone as well as competitive performance among the contemporary state-of-the-art methods.