 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoutesplain: Towards Faithful and Intervenable Routing for Software-related Tasks
Nov 12, 2025



LLMs now tackle a wide range of software-related tasks, yet we show that their performance varies markedly both across and within these tasks. Routing user queries to the appropriate LLMs can therefore help improve response quality while reducing cost. Prior work, however, has focused mainly on general-purpose LLM routing via black-box models. We introduce Routesplain, the first LLM router for software-related tasks, including multilingual code generation and repair, input/output prediction, and computer science QA. Unlike existing routing approaches, Routesplain first extracts human-interpretable concepts from each query (e.g., task, domain, reasoning complexity) and only routes based on these concepts, thereby providing intelligible, faithful rationales. We evaluate Routesplain on 16 state-of-the-art LLMs across eight software-related tasks; Routesplain outperforms individual models both in terms of accuracy and cost, and equals or surpasses all black-box baselines, with concept-level intervention highlighting avenues for further router improvements.
Reconciling Methodological Paradigms: Employing Large Language Models as Novice Qualitative Research Assistants in Talent Management Research
Aug 20, 2024



Qualitative data collection and analysis approaches, such as those employing interviews and focus groups, provide rich insights into customer attitudes, sentiment, and behavior. However, manually analyzing qualitative data requires extensive time and effort to identify relevant topics and thematic insights. This study proposes a novel approach to address this challenge by leveraging Retrieval Augmented Generation (RAG) based Large Language Models (LLMs) for analyzing interview transcripts. The novelty of this work lies in strategizing the research inquiry as one that is augmented by an LLM that serves as a novice research assistant. This research explores the mental model of LLMs to serve as novice qualitative research assistants for researchers in the talent management space. A RAG-based LLM approach is extended to enable topic modeling of semi-structured interview data, showcasing the versatility of these models beyond their traditional use in information retrieval and search. Our findings demonstrate that the LLM-augmented RAG approach can successfully extract topics of interest, with significant coverage compared to manually generated topics from the same dataset. This establishes the viability of employing LLMs as novice qualitative research assistants. Additionally, the study recommends that researchers leveraging such models lean heavily on quality criteria used in traditional qualitative research to ensure rigor and trustworthiness of their approach. Finally, the paper presents key recommendations for industry practitioners seeking to reconcile the use of LLMs with established qualitative research paradigms, providing a roadmap for the effective integration of these powerful, albeit novice, AI tools in the analysis of qualitative datasets within talent
Graph Regularized Encoder Training for Extreme Classification
Feb 28, 2024
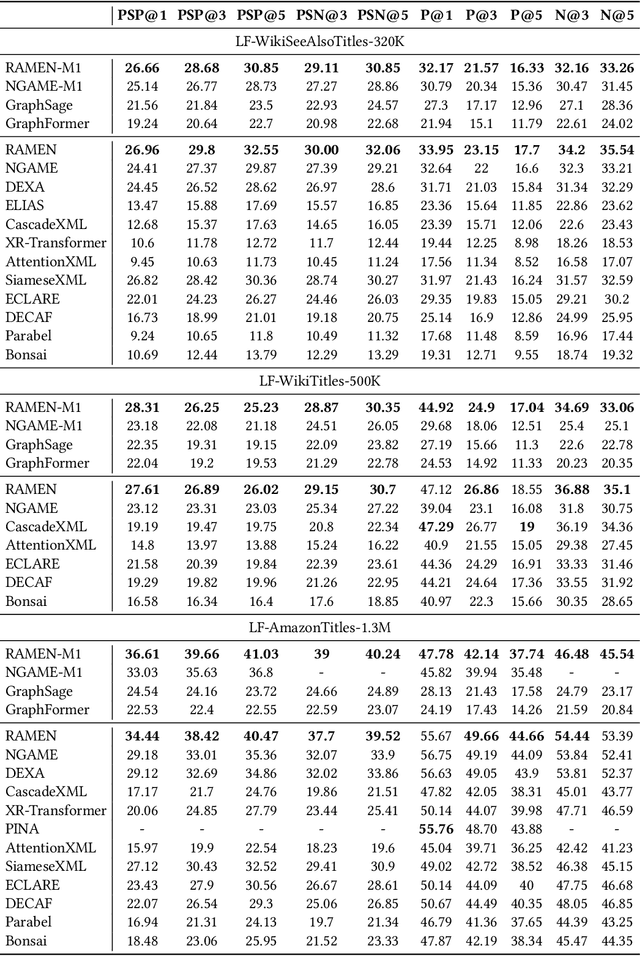
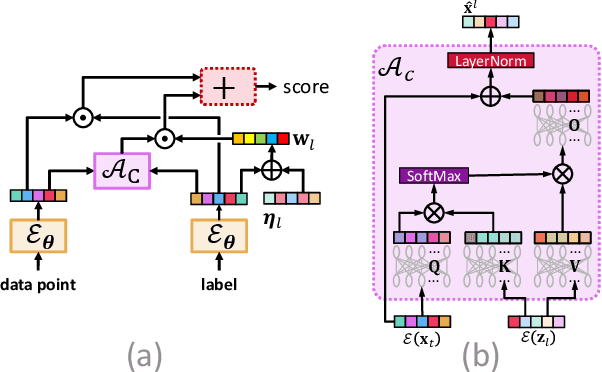
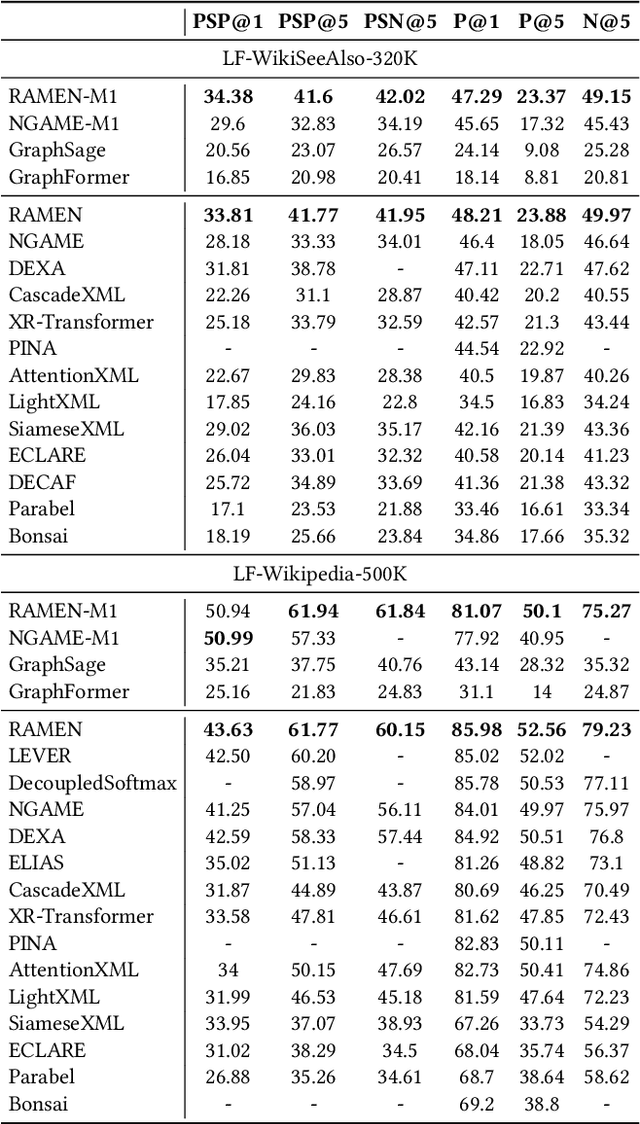
Deep extreme classification (XC) aims to train an encoder architecture and an accompanying classifier architecture to tag a data point with the most relevant subset of labels from a very large universe of labels. XC applications in ranking, recommendation and tagging routinely encounter tail labels for which the amount of training data is exceedingly small. Graph convolutional networks (GCN) present a convenient but computationally expensive way to leverage task metadata and enhance model accuracies in these settings. This paper formally establishes that in several use cases, the steep computational cost of GCNs is entirely avoidable by replacing GCNs with non-GCN architectures. The paper notices that in these settings, it is much more effective to use graph data to regularize encoder training than to implement a GCN. Based on these insights, an alternative paradigm RAMEN is presented to utilize graph metadata in XC settings that offers significant performance boosts with zero increase in inference computational costs. RAMEN scales to datasets with up to 1M labels and offers prediction accuracy up to 15% higher on benchmark datasets than state of the art methods, including those that use graph metadata to train GCNs. RAMEN also offers 10% higher accuracy over the best baseline on a proprietary recommendation dataset sourced from click logs of a popular search engine. Code for RAMEN will be released publicly.
EHI: End-to-end Learning of Hierarchical Index for Efficient Dense Retrieval
Oct 13, 2023Dense embedding-based retrieval is now the industry standard for semantic search and ranking problems, like obtaining relevant web documents for a given query. Such techniques use a two-stage process: (a) contrastive learning to train a dual encoder to embed both the query and documents and (b) approximate nearest neighbor search (ANNS) for finding similar documents for a given query. These two stages are disjoint; the learned embeddings might be ill-suited for the ANNS method and vice-versa, leading to suboptimal performance. In this work, we propose End-to-end Hierarchical Indexing -- EHI -- that jointly learns both the embeddings and the ANNS structure to optimize retrieval performance. EHI uses a standard dual encoder model for embedding queries and documents while learning an inverted file index (IVF) style tree structure for efficient ANNS. To ensure stable and efficient learning of discrete tree-based ANNS structure, EHI introduces the notion of dense path embedding that captures the position of a query/document in the tree. We demonstrate the effectiveness of EHI on several benchmarks, including de-facto industry standard MS MARCO (Dev set and TREC DL19) datasets. For example, with the same compute budget, EHI outperforms state-of-the-art (SOTA) in by 0.6% (MRR@10) on MS MARCO dev set and by 4.2% (nDCG@10) on TREC DL19 benchmarks.
Multi-modal Extreme Classification
Sep 10, 2023This paper develops the MUFIN technique for extreme classification (XC) tasks with millions of labels where datapoints and labels are endowed with visual and textual descriptors. Applications of MUFIN to product-to-product recommendation and bid query prediction over several millions of products are presented. Contemporary multi-modal methods frequently rely on purely embedding-based methods. On the other hand, XC methods utilize classifier architectures to offer superior accuracies than embedding only methods but mostly focus on text-based categorization tasks. MUFIN bridges this gap by reformulating multi-modal categorization as an XC problem with several millions of labels. This presents the twin challenges of developing multi-modal architectures that can offer embeddings sufficiently expressive to allow accurate categorization over millions of labels; and training and inference routines that scale logarithmically in the number of labels. MUFIN develops an architecture based on cross-modal attention and trains it in a modular fashion using pre-training and positive and negative mining. A novel product-to-product recommendation dataset MM-AmazonTitles-300K containing over 300K products was curated from publicly available amazon.com listings with each product endowed with a title and multiple images. On the all datasets MUFIN offered at least 3% higher accuracy than leading text-based, image-based and multi-modal techniques. Code for MUFIN is available at https://github.com/Extreme-classification/MUFIN
NGAME: Negative Mining-aware Mini-batching for Extreme Classification
Jul 10, 2022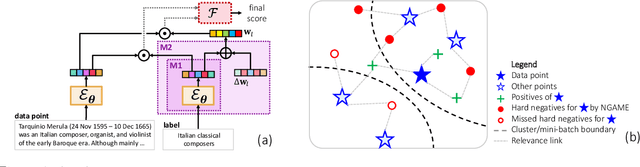
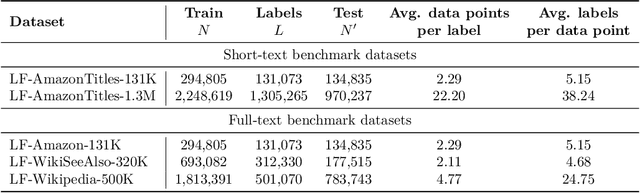
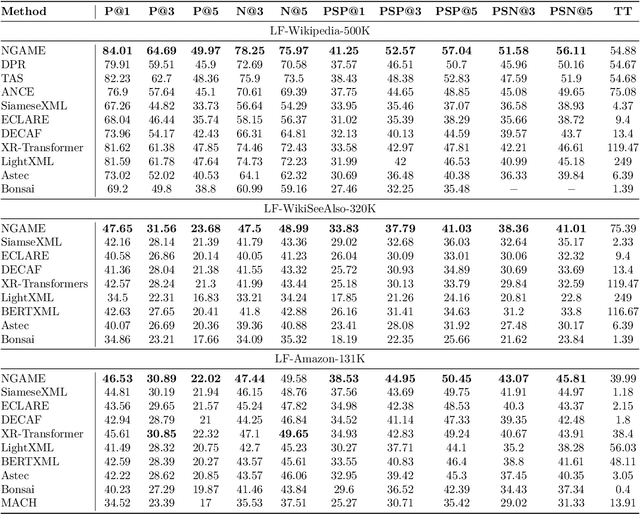
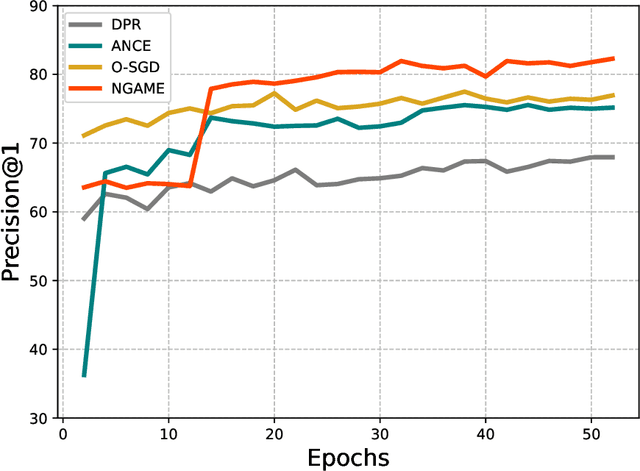
Extreme Classification (XC) seeks to tag data points with the most relevant subset of labels from an extremely large label set. Performing deep XC with dense, learnt representations for data points and labels has attracted much attention due to its superiority over earlier XC methods that used sparse, hand-crafted features. Negative mining techniques have emerged as a critical component of all deep XC methods that allow them to scale to millions of labels. However, despite recent advances, training deep XC models with large encoder architectures such as transformers remains challenging. This paper identifies that memory overheads of popular negative mining techniques often force mini-batch sizes to remain small and slow training down. In response, this paper introduces NGAME, a light-weight mini-batch creation technique that offers provably accurate in-batch negative samples. This allows training with larger mini-batches offering significantly faster convergence and higher accuracies than existing negative sampling techniques. NGAME was found to be up to 16% more accurate than state-of-the-art methods on a wide array of benchmark datasets for extreme classification, as well as 3% more accurate at retrieving search engine queries in response to a user webpage visit to show personalized ads. In live A/B tests on a popular search engine, NGAME yielded up to 23% gains in click-through-rates.
DeepXML: A Deep Extreme Multi-Label Learning Framework Applied to Short Text Documents
Nov 12, 2021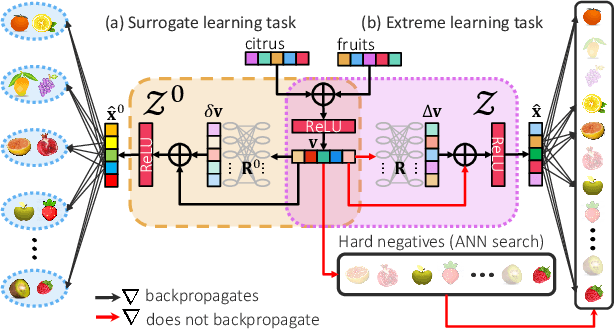
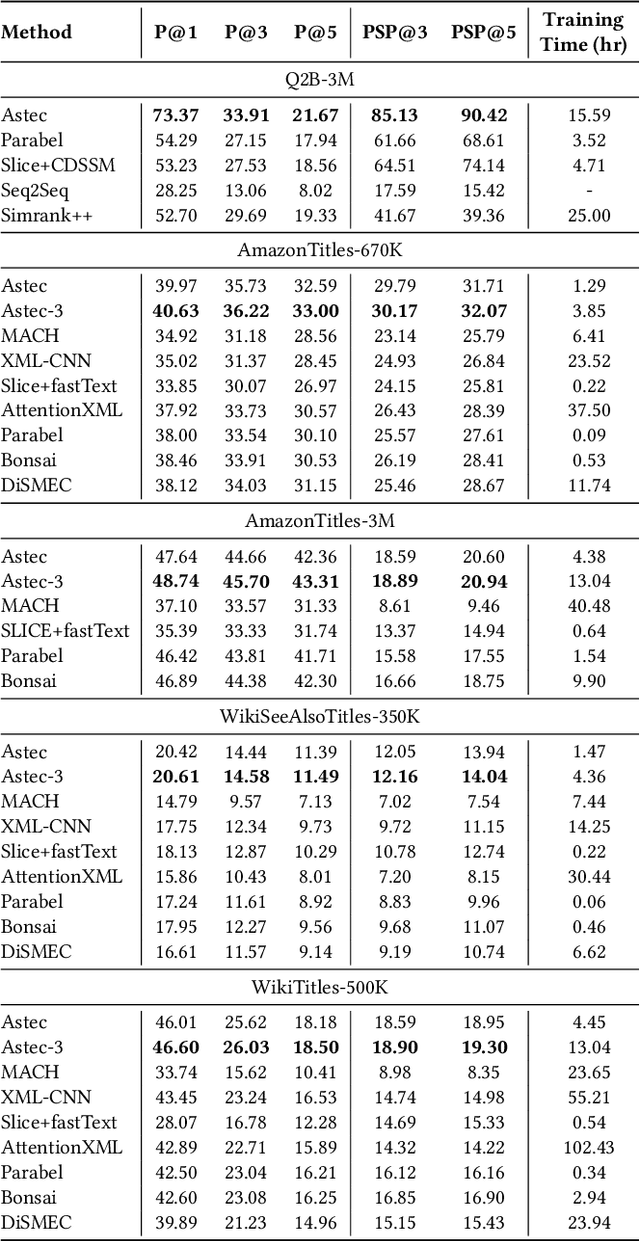

Scalability and accuracy are well recognized challenges in deep extreme multi-label learning where the objective is to train architectures for automatically annotating a data point with the most relevant subset of labels from an extremely large label set. This paper develops the DeepXML framework that addresses these challenges by decomposing the deep extreme multi-label task into four simpler sub-tasks each of which can be trained accurately and efficiently. Choosing different components for the four sub-tasks allows DeepXML to generate a family of algorithms with varying trade-offs between accuracy and scalability. In particular, DeepXML yields the Astec algorithm that could be 2-12% more accurate and 5-30x faster to train than leading deep extreme classifiers on publically available short text datasets. Astec could also efficiently train on Bing short text datasets containing up to 62 million labels while making predictions for billions of users and data points per day on commodity hardware. This allowed Astec to be deployed on the Bing search engine for a number of short text applications ranging from matching user queries to advertiser bid phrases to showing personalized ads where it yielded significant gains in click-through-rates, coverage, revenue and other online metrics over state-of-the-art techniques currently in production. DeepXML's code is available at https://github.com/Extreme-classification/deepxml
DECAF: Deep Extreme Classification with Label Features
Aug 01, 2021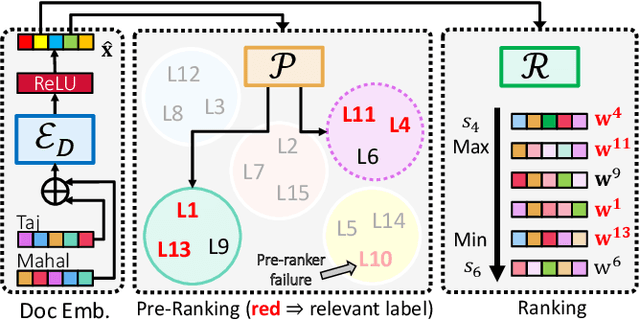
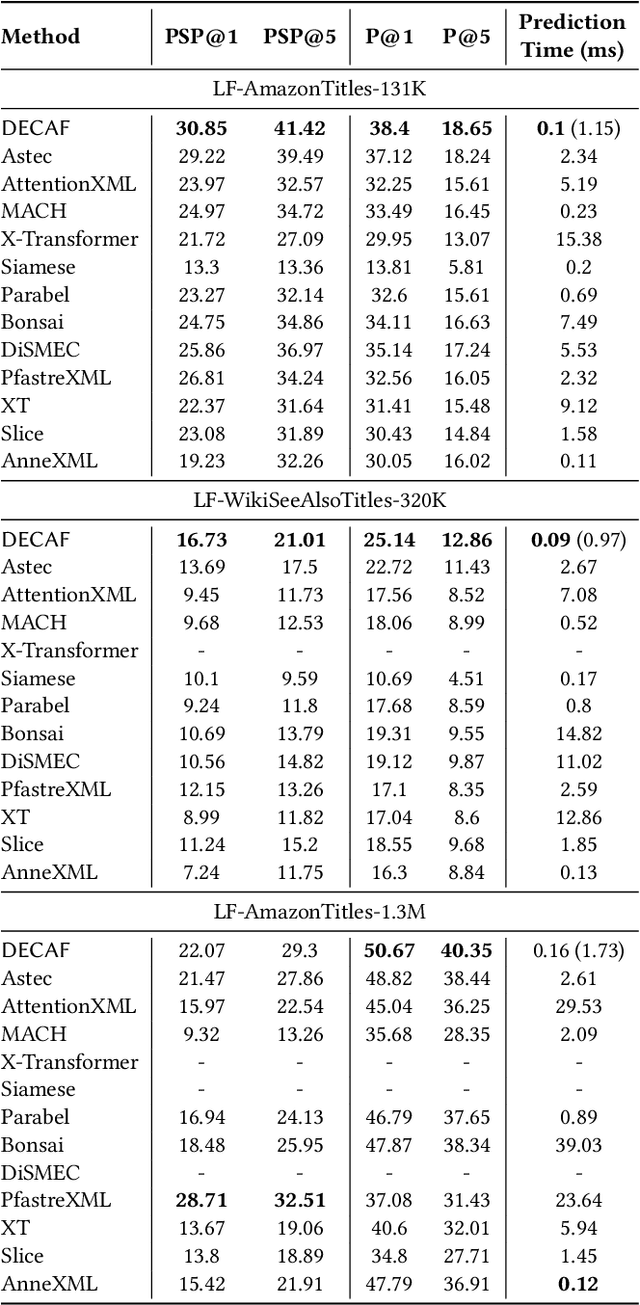
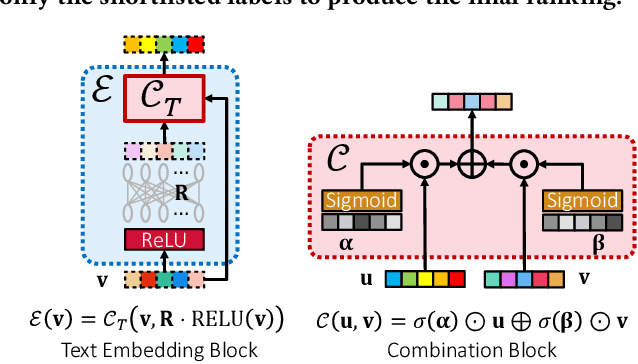
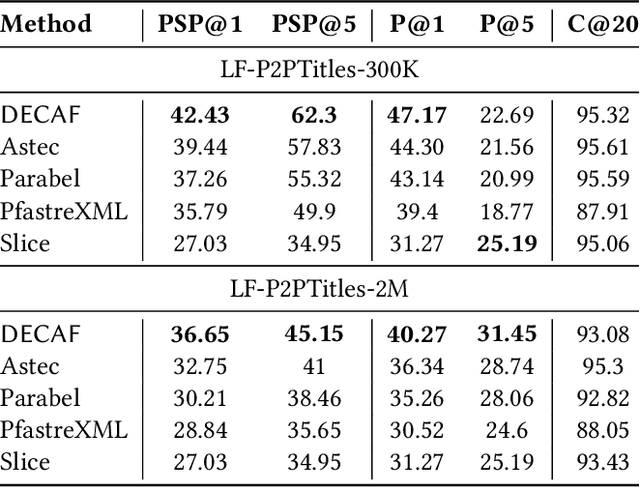
Extreme multi-label classification (XML) involves tagging a data point with its most relevant subset of labels from an extremely large label set, with several applications such as product-to-product recommendation with millions of products. Although leading XML algorithms scale to millions of labels, they largely ignore label meta-data such as textual descriptions of the labels. On the other hand, classical techniques that can utilize label metadata via representation learning using deep networks struggle in extreme settings. This paper develops the DECAF algorithm that addresses these challenges by learning models enriched by label metadata that jointly learn model parameters and feature representations using deep networks and offer accurate classification at the scale of millions of labels. DECAF makes specific contributions to model architecture design, initialization, and training, enabling it to offer up to 2-6% more accurate prediction than leading extreme classifiers on publicly available benchmark product-to-product recommendation datasets, such as LF-AmazonTitles-1.3M. At the same time, DECAF was found to be up to 22x faster at inference than leading deep extreme classifiers, which makes it suitable for real-time applications that require predictions within a few milliseconds. The code for DECAF is available at the following URL https://github.com/Extreme-classification/DECAF.
ECLARE: Extreme Classification with Label Graph Correlations
Jul 31, 2021
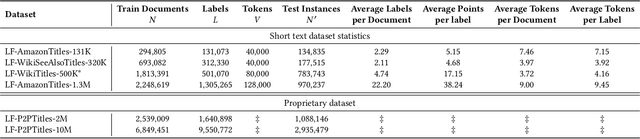
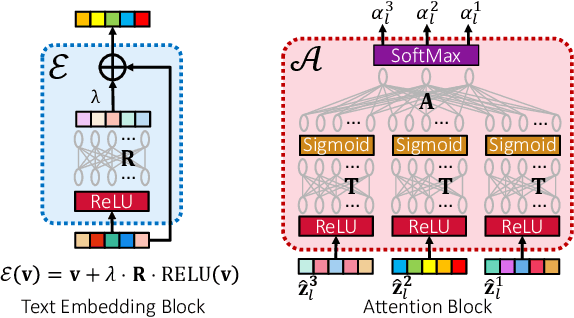
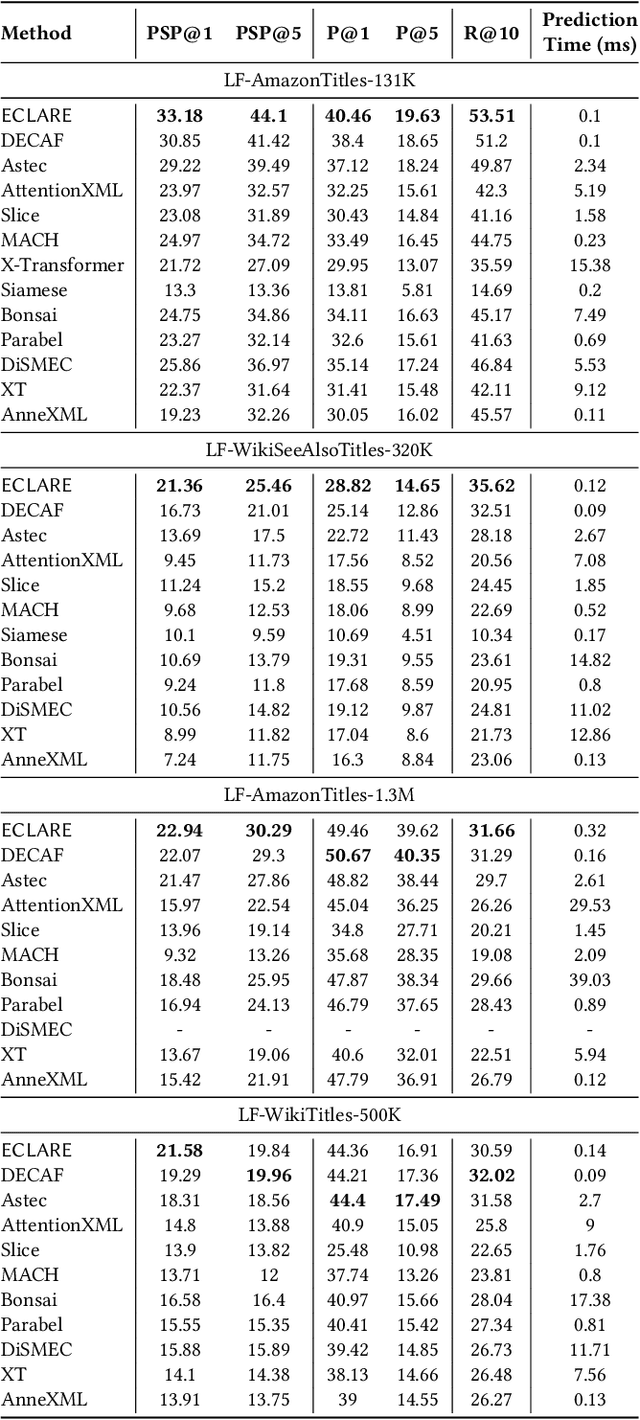
Deep extreme classification (XC) seeks to train deep architectures that can tag a data point with its most relevant subset of labels from an extremely large label set. The core utility of XC comes from predicting labels that are rarely seen during training. Such rare labels hold the key to personalized recommendations that can delight and surprise a user. However, the large number of rare labels and small amount of training data per rare label offer significant statistical and computational challenges. State-of-the-art deep XC methods attempt to remedy this by incorporating textual descriptions of labels but do not adequately address the problem. This paper presents ECLARE, a scalable deep learning architecture that incorporates not only label text, but also label correlations, to offer accurate real-time predictions within a few milliseconds. Core contributions of ECLARE include a frugal architecture and scalable techniques to train deep models along with label correlation graphs at the scale of millions of labels. In particular, ECLARE offers predictions that are 2 to 14% more accurate on both publicly available benchmark datasets as well as proprietary datasets for a related products recommendation task sourced from the Bing search engine. Code for ECLARE is available at https://github.com/Extreme-classification/ECLARE.