 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Magic Correlations: Understanding Knowledge Transfer from Pretraining to Supervised Fine-Tuning
Feb 11, 2026Understanding how language model capabilities transfer from pretraining to supervised fine-tuning (SFT) is fundamental to efficient model development and data curation. In this work, we investigate four core questions: RQ1. To what extent do accuracy and confidence rankings established during pretraining persist after SFT? RQ2. Which benchmarks serve as robust cross-stage predictors and which are unreliable? RQ3. How do transfer dynamics shift with model scale? RQ4. How well does model confidence align with accuracy, as a measure of calibration quality? Does this alignment pattern transfer across training stages? We address these questions through a suite of correlation protocols applied to accuracy and confidence metrics across diverse data mixtures and model scales. Our experiments reveal that transfer reliability varies dramatically across capability categories, benchmarks, and scales -- with accuracy and confidence exhibiting distinct, sometimes opposing, scaling dynamics. These findings shed light on the complex interplay between pretraining decisions and downstream outcomes, providing actionable guidance for benchmark selection, data curation, and efficient model development.
AgenticTagger: Structured Item Representation for Recommendation with LLM Agents
Feb 05, 2026High-quality representations are a core requirement for effective recommendation. In this work, we study the problem of LLM-based descriptor generation, i.e., keyphrase-like natural language item representation generation frameworks with minimal constraints on downstream applications. We propose AgenticTagger, a framework that queries LLMs for representing items with sequences of text descriptors. However, open-ended generation provides little control over the generation space, leading to high cardinality, low-performance descriptors that renders downstream modeling challenging. To this end, AgenticTagger features two core stages: (1) a vocabulary building stage where a set of hierarchical, low-cardinality, and high-quality descriptors is identified, and (2) a vocabulary assignment stage where LLMs assign in-vocabulary descriptors to items. To effectively and efficiently ground vocabulary in the item corpus of interest, we design a multi-agent reflection mechanism where an architect LLM iteratively refines the vocabulary guided by parallelized feedback from annotator LLMs that validates the vocabulary against item data. Experiments on public and private data show AgenticTagger brings consistent improvements across diverse recommendation scenarios, including generative and term-based retrieval, ranking, and controllability-oriented, critique-based recommendation.
PACEvolve: Enabling Long-Horizon Progress-Aware Consistent Evolution
Jan 15, 2026Large Language Models (LLMs) have emerged as powerful operators for evolutionary search, yet the design of efficient search scaffolds remains ad hoc. While promising, current LLM-in-the-loop systems lack a systematic approach to managing the evolutionary process. We identify three distinct failure modes: Context Pollution, where experiment history biases future candidate generation; Mode Collapse, where agents stagnate in local minima due to poor exploration-exploitation balance; and Weak Collaboration, where rigid crossover strategies fail to leverage parallel search trajectories effectively. We introduce Progress-Aware Consistent Evolution (PACEvolve), a framework designed to robustly govern the agent's context and search dynamics, to address these challenges. PACEvolve combines hierarchical context management (HCM) with pruning to address context pollution; momentum-based backtracking (MBB) to escape local minima; and a self-adaptive sampling policy that unifies backtracking and crossover for dynamic search coordination (CE), allowing agents to balance internal refinement with cross-trajectory collaboration. We demonstrate that PACEvolve provides a systematic path to consistent, long-horizon self-improvement, achieving state-of-the-art results on LLM-SR and KernelBench, while discovering solutions surpassing the record on Modded NanoGPT.
Gemma 3 Technical Report
Mar 25, 2025We introduce Gemma 3, a multimodal addition to the Gemma family of lightweight open models, ranging in scale from 1 to 27 billion parameters. This version introduces vision understanding abilities, a wider coverage of languages and longer context - at least 128K tokens. We also change the architecture of the model to reduce the KV-cache memory that tends to explode with long context. This is achieved by increasing the ratio of local to global attention layers, and keeping the span on local attention short. The Gemma 3 models are trained with distillation and achieve superior performance to Gemma 2 for both pre-trained and instruction finetuned versions. In particular, our novel post-training recipe significantly improves the math, chat, instruction-following and multilingual abilities, making Gemma3-4B-IT competitive with Gemma2-27B-IT and Gemma3-27B-IT comparable to Gemini-1.5-Pro across benchmarks. We release all our models to the community.
ActionPiece: Contextually Tokenizing Action Sequences for Generative Recommendation
Feb 19, 2025Generative recommendation (GR) is an emerging paradigm where user actions are tokenized into discrete token patterns and autoregressively generated as predictions. However, existing GR models tokenize each action independently, assigning the same fixed tokens to identical actions across all sequences without considering contextual relationships. This lack of context-awareness can lead to suboptimal performance, as the same action may hold different meanings depending on its surrounding context. To address this issue, we propose ActionPiece to explicitly incorporate context when tokenizing action sequences. In ActionPiece, each action is represented as a set of item features, which serve as the initial tokens. Given the action sequence corpora, we construct the vocabulary by merging feature patterns as new tokens, based on their co-occurrence frequency both within individual sets and across adjacent sets. Considering the unordered nature of feature sets, we further introduce set permutation regularization, which produces multiple segmentations of action sequences with the same semantics. Experiments on public datasets demonstrate that ActionPiece consistently outperforms existing action tokenization methods, improving NDCG@$10$ by $6.00\%$ to $12.82\%$.
GC-Bench: A Benchmark Framework for Graph Condensation with New Insights
Jun 24, 2024



Graph condensation (GC) is an emerging technique designed to learn a significantly smaller graph that retains the essential information of the original graph. This condensed graph has shown promise in accelerating graph neural networks while preserving performance comparable to those achieved with the original, larger graphs. Additionally, this technique facilitates downstream applications such as neural architecture search and enhances our understanding of redundancy in large graphs. Despite the rapid development of GC methods, a systematic evaluation framework remains absent, which is necessary to clarify the critical designs for particular evaluative aspects. Furthermore, several meaningful questions have not been investigated, such as whether GC inherently preserves certain graph properties and offers robustness even without targeted design efforts. In this paper, we introduce GC-Bench, a comprehensive framework to evaluate recent GC methods across multiple dimensions and to generate new insights. Our experimental findings provide a deeper insights into the GC process and the characteristics of condensed graphs, guiding future efforts in enhancing performance and exploring new applications. Our code is available at \url{https://github.com/Emory-Melody/GraphSlim/tree/main/benchmark}.
How to Train Data-Efficient LLMs
Feb 15, 2024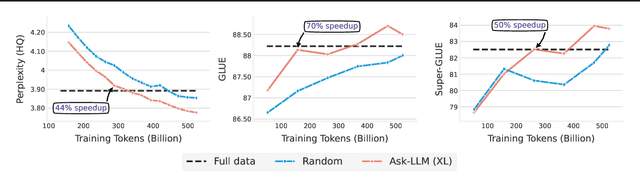
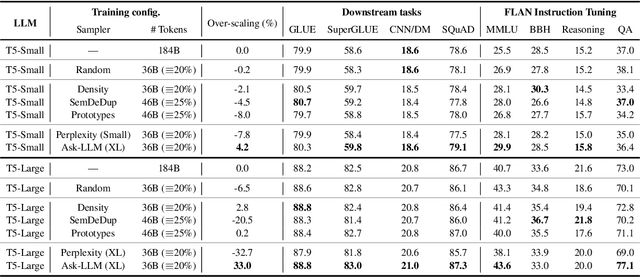
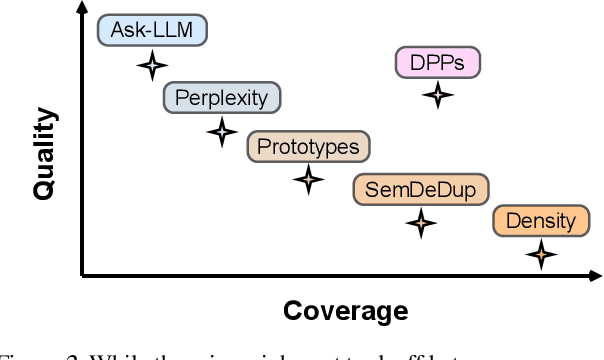

The training of large language models (LLMs) is expensive. In this paper, we study data-efficient approaches for pre-training LLMs, i.e., techniques that aim to optimize the Pareto frontier of model quality and training resource/data consumption. We seek to understand the tradeoffs associated with data selection routines based on (i) expensive-to-compute data-quality estimates, and (ii) maximization of coverage and diversity-based measures in the feature space. Our first technique, Ask-LLM, leverages the zero-shot reasoning capabilities of instruction-tuned LLMs to directly assess the quality of a training example. To target coverage, we propose Density sampling, which models the data distribution to select a diverse sample. In our comparison of 19 samplers, involving hundreds of evaluation tasks and pre-training runs, we find that Ask-LLM and Density are the best methods in their respective categories. Coverage sampling can recover the performance of the full data, while models trained on Ask-LLM data consistently outperform full-data training -- even when we reject 90% of the original dataset, while converging up to 70% faster.
Off-Policy Evaluation for Large Action Spaces via Policy Convolution
Oct 24, 2023Developing accurate off-policy estimators is crucial for both evaluating and optimizing for new policies. The main challenge in off-policy estimation is the distribution shift between the logging policy that generates data and the target policy that we aim to evaluate. Typically, techniques for correcting distribution shift involve some form of importance sampling. This approach results in unbiased value estimation but often comes with the trade-off of high variance, even in the simpler case of one-step contextual bandits. Furthermore, importance sampling relies on the common support assumption, which becomes impractical when the action space is large. To address these challenges, we introduce the Policy Convolution (PC) family of estimators. These methods leverage latent structure within actions -- made available through action embeddings -- to strategically convolve the logging and target policies. This convolution introduces a unique bias-variance trade-off, which can be controlled by adjusting the amount of convolution. Our experiments on synthetic and benchmark datasets demonstrate remarkable mean squared error (MSE) improvements when using PC, especially when either the action space or policy mismatch becomes large, with gains of up to 5 - 6 orders of magnitude over existing estimators.
Farzi Data: Autoregressive Data Distillation
Oct 15, 2023



We study data distillation for auto-regressive machine learning tasks, where the input and output have a strict left-to-right causal structure. More specifically, we propose Farzi, which summarizes an event sequence dataset into a small number of synthetic sequences -- Farzi Data -- which are optimized to maintain (if not improve) model performance compared to training on the full dataset. Under the hood, Farzi conducts memory-efficient data distillation by (i) deriving efficient reverse-mode differentiation of the Adam optimizer by leveraging Hessian-Vector Products; and (ii) factorizing the high-dimensional discrete event-space into a latent-space which provably promotes implicit regularization. Empirically, for sequential recommendation and language modeling tasks, we are able to achieve 98-120% of downstream full-data performance when training state-of-the-art models on Farzi Data of size as little as 0.1% of the original dataset. Notably, being able to train better models with significantly less data sheds light on the design of future large auto-regressive models, and opens up new opportunities to further scale up model and data sizes.
Data Distillation: A Survey
Jan 11, 2023The popularity of deep learning has led to the curation of a vast number of massive and multifarious datasets. Despite having close-to-human performance on individual tasks, training parameter-hungry models on large datasets poses multi-faceted problems such as (a) high model-training time; (b) slow research iteration; and (c) poor eco-sustainability. As an alternative, data distillation approaches aim to synthesize terse data summaries, which can serve as effective drop-in replacements of the original dataset for scenarios like model training, inference, architecture search, etc. In this survey, we present a formal framework for data distillation, along with providing a detailed taxonomy of existing approaches. Additionally, we cover data distillation approaches for different data modalities, namely images, graphs, and user-item interactions (recommender systems), while also identifying current challenges and future research directions.